
- 전체
- C/C++ 일반
- C/C++ 수학
- C/C++ 그래픽
- C/C++ 자료구조
- C/C++ 인공지능
- C/C++ 인터넷
- wxWidget
- GTK+
- UNIX or LINUX programming
- 리눅스 마스터 - 국가공인자격
- VC++/ MFC
- C#/CLI/.NET
- QT/기타UI
- Boost lib
- 오픈소스 C 분석자료
- MSA (마이크로서비스), Docker, kubernetes
- WSL(windows subsystem linux)
C/C++ 인공지능 [C++ 인공지능] C ++을 이용한 단순 MLP 역 전파 인공 신경망 (단계 별)
2022.04.11 06:52
[C++ 인공지능] C ++을 이용한 단순 MLP 역 전파 인공 신경망 (단계 별)
C ++를 사용한
f (x) = sin (x) 를 근사화하는 매우 간단한 역 전파 신경망 알고리즘 구현
소개
신경망은 기계 학습 방법에서 가장 유행하는 솔루션 중 하나입니다.
이 방법은 정확한 솔루션이없는 문제에 매우 유용합니다.
최근에는 이러한 메소드의 인기가 높아지면서 Matlab, Python, C ++ 등에서 많은 라이브러리가 개발되었습니다.
훈련 세트를 입력으로 받고 가정 된 문제에 적합한 신경망을 자동으로 구축합니다.
또한 고속 CPU와 GPU, 그리고 심층 신경망과 신경망 계산에 정확히 최적화 된 NPU가 더 많이 개발됨으로써 매일 성장하고 있습니다.
그러나 이러한 라이브러리를 사용함으로써 때때로 우리는 정확히 무슨 일이 일어 났는지, 그리고 네트워크이 어떻게 최적화 되는 지에 대해서 정확히 이해하지 못합니다.
솔루션의 기본을 아는 것은 고전적인 방법들을 개발하는 데 매우 중요합니다.
따라서이 기사에서는 f (x)) (= sin (x)를 근사화하기위한 신경망 알고리즘의 매우 간단한 구조를 설명하면서 C ++로 차근차근 구현 해 봅시다.
배경
가장 성공적이고 유용한 신경망 중 하나는
Feed Forward Supervised Neural Networks 또는 Multi-Layer Perceptron Neural Networks (MLP)라고 합니다.
이러한 종류의 신경망에는 다음과 같은 세 부분이 포함됩니다.
1. Input Layer(입력 레이어)
2. Hidden Layers(은닉 레이어)
3. Output Layer(출력 레이어)
각 계층에는 네트워크의 다른 뉴런에 연결되는 뉴런이라는 여러 노드가 있습니다. 모든 신경망에는 다음과 같은 5 가지 중요한 속성이 있습니다.
1. Number of input nodes(입력 노드 수)
2. Number of nodes per hidden layer(은닉층 당 노드 수)
3. Number of output nodes(출력 노드 수)
4. Number of hidden layers(은닉 레이어 수)
5. The learning rate(학습률)
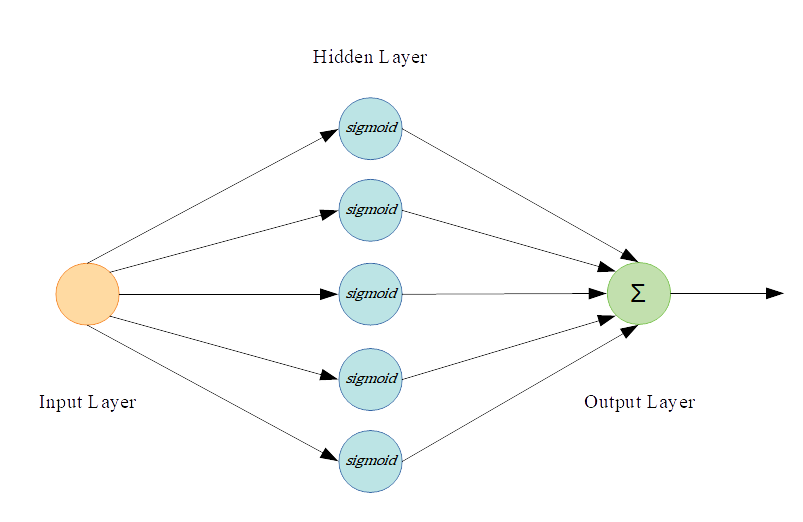
이 예에서는 은닉레이어 1 개와 은닉레이어에 5 개의 뉴런이있는 MLP 신경망을 사용합니다. 다음의 식으로 정의 된 \ (sigmoid \) 함수를 각 노드 활성화 함수로 사용할 것입니다.
다음 그림은 사용 된 신경망 구조를 보여줍니다.
여기서 x는 입력 벡터,
는 은닉레이어의 출력이며,
는 이 예제에서
의 근사치가되는 신경망의 주요 출력입니다.
이 고전적인 예제의 손실 함수는 다음과 같이 제곱 오차 일 수 있습니다.

그리고 훈련 함수는 다음과 같습니다.

여기서
는 t 번째 훈련 입력입니다.


신경망의 주요 목표는 W, V, b, c 매개 변수를 업데이트하여 이 비용 함수를 최소화하는 것입니다.
마지막으로 이 예제의 고전적인 훈련 절차는 경사 하강 법으로,
다음과 같이 매개 변수 W, V, b, c를 반복적으로 업데이트합니다.

코드 만들기
제안 된 신경망을 훈련하려면 데이터가 필요합니다.
훈련 세트는 매우 중요하며, 일반 훈련 세트는 더 나은 근사치로 이어집니다.
예를 들어, 여기서는 범위 [0, 2π]를 Train_Set_Size 부분으로 나누고 신경망에 훈련 세트로 제공합니다.
시그 모이 드 함수는 C ++ 표준 함수가 아니므로 시그 모이 드를 계산하는 함수를 정의해야만 합니다.
또, 우리는 각 반복 마다,
를 계산하는 함수가 필요 합니다.
여기서
x는 1x1 입력 트레인 값,
W는 1x1 (벡터 포함),
c는 각 뉴런의 오프셋에 대한 스케일러 값이지만
단순성을 위해 모든 노드 오프셋 값을 1x5 배열에 저장하고 마지막으로 b는 출력 노드 오프셋입니다.
코드 시작 부분에 이러한 변수를 다음과 같이 정의합니다.
앞서 언급했듯이 각 반복에서 W, V, b, c 매개 변수를 업데이트해야합니다. W에 대한 기울기를 계산하여 매개 변수 W의 경우 다음과 같이됩니다.

나머지 매개 변수는 다음과 같이 계산할 수 있습니다.
V:

b:

c:

이제 각 훈련 데이터에 대해 신경망 매개 변수를 업데이트해야하지만 대부분의 경우 좋은 결과를 수렴하기 위해 모든 훈련 쌍을 신경망에 여러 번 제공해야합니다.
"Epoch"라 불리는 신경망에 모든 훈련 데이터를 제공 합니다 :
마지막으로 우리는 gnuplot으로 해당 결과를 그려 낼 수 있습니다.
전체 소스
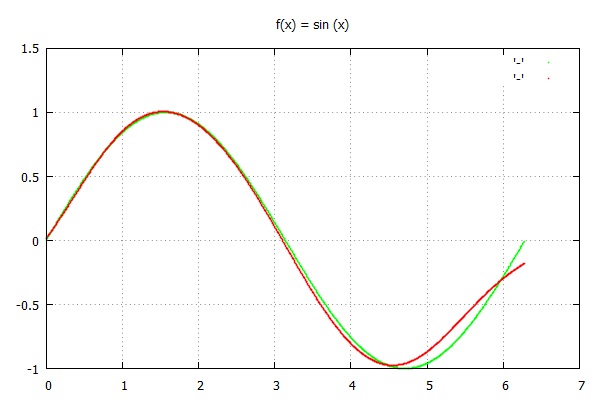
주요 요점들
1. Epoch의 효과. Epoch를 늘리면 우리는 더 나은 오류 최소화를 수행 할 수 있습니다.
2. 신경망 매개 변수의 초기 값 효과. 경험했듯이 매개 변수의 초기 값으로 0을 선택하면 단순 경사 하강 법이 국소 최소값으로 수렴되므로 언급 된 코드에서 임의의 값이 초기 값으로 선택됩니다.
엡실론 값은 수렴 률에서 매우 중요합니다.
3.작은 엡실론은 조기 수렴을 일으키고 큰 엡실론은 매개 변수를 발산시킵니다.
4. 단순 경사 하강 법은 전역 최소값을 찾는 강력한 방법이 아닙니다.
위 그림에서 알 수 있듯이 신경망은 좋은 근사치를 충족하지 않습니다.
참고 문헌
[1] Neural networks by Simon Haykin
[2] Deep Learning by Yoshua Bengio-Ian, J. Goodfellow and Aaron Courville (March 30, 2015)
이상.
[출처] https://m.blog.naver.com/tommybee/222074665249
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.