
- 전체
- Python 일반
- Python 수학
- Python 그래픽
- Python 자료구조
- Python 인공지능
- Python 인터넷
- Python SAGE
- wxPython
- TkInter
- iPython
- wxPython
- pyQT
- Jython
- django
- flask
- blender python scripting
- python for minecraft
- Python 데이터 분석
- Python RPA
- cython
- PyCharm
- pySide
- kivy (python)
Python 데이터 분석 [Python 데이터 분석] 데이터 과학을 단순하게 만드는 3가지 Python 패키지
2021.09.24 00:40
[Python 데이터 분석] 데이터 과학을 단순하게 만드는 3가지 Python 패키지
Mito는 Python용 스프레드시트 프론트엔드입니다. Mito를 Jupyter Notebook으로 호출할 수 있으며 프런트 엔드에서 편집할 때마다 동등한 Python이 생성됩니다.
다음은 비디오 데모입니다.
Mito를 설치하려면 다음 세 가지 명령을 사용하십시오.
python -m pip install mitoinstaller
python -m mitoinstaller install
python -m jupyter lab
Mito는 데이터를 슬라이싱하고 다이싱하기 위한 훌륭한 패키지입니다. Mito를 사용하면 몇 번의 클릭만으로 대화형 피벗 테이블과 그래프를 만들 수 있습니다.
Mito 피벗 테이블은 다양한 변수 간의 관계를 확인하고 통찰력을 보다 명확하게 하는 방식으로 데이터를 그룹화하는 좋은 방법입니다.
도구 모음에서 피벗 버튼을 선택한 다음 행, 열, 값 및 집계 유형을 선택하여 Mito 피벗 테이블을 구성할 수 있습니다.
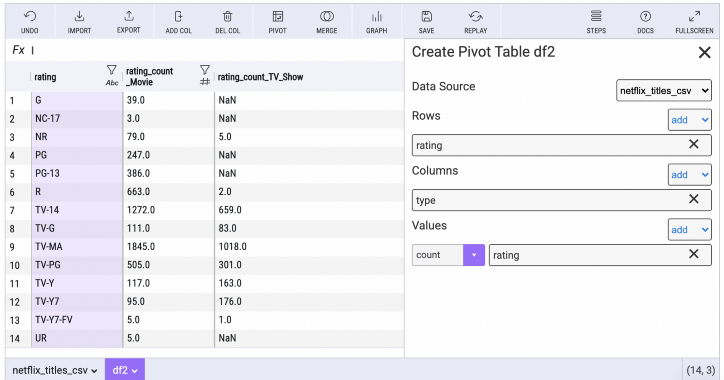
Mito에서 편집할 때마다 아래 코드 셀에 동등한 Python이 생성됩니다. 올바른 구문을 찾기 위해 계속해서 스택 오버플로로 향하는 것보다 훨씬 빠른 코드 생성 방법입니다.
위의 피벗 테이블은 이 코드를 생성하고 자동 주석도 추가합니다!

Mito는 피벗 테이블에 대한 코드를 생성하지 않습니다. 에서 미토, 당신은 데이터 세트, 일종의 필터, 사용, 기능, 요약 통계에 모습을 병합 등의 작업을 수행 할 수 있습니다 - 미토는 이러한 편집의 각각에 해당하는 파이썬을 생성합니다.
Mito는 또한 사용자가 코딩 없이 동적 플롯 차트 를 생성할 수 있도록 합니다. Plotly는 놀라운 Python 그래프 패키지입니다.
Plotly 차트를 생성하려면 사용자가 그래프 버튼을 클릭하고 축을 선택하기만 하면 됩니다.
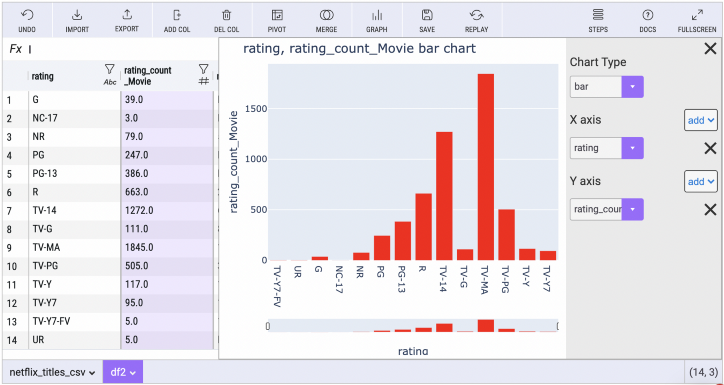
다음은 Mito의 전체 문서 입니다.
Pandas Profiling은 Pandas의 df.describe() 함수를 가져와 기능에 대해 자세히 설명하여 데이터 프레임에 대한 놀라운 요약 정보를 빠르고 효율적으로 제공합니다.
Pandas Profiling은 탐색적 데이터 분석을 위한 훌륭한 도구입니다.


다음 명령을 사용하여 로컬로 패키지를 설치할 수 있습니다.
import sys
!{sys.executable} -m pip install -U pandas-profiling[notebook]
!jupyter nbextension enable --py widgetsnbextension
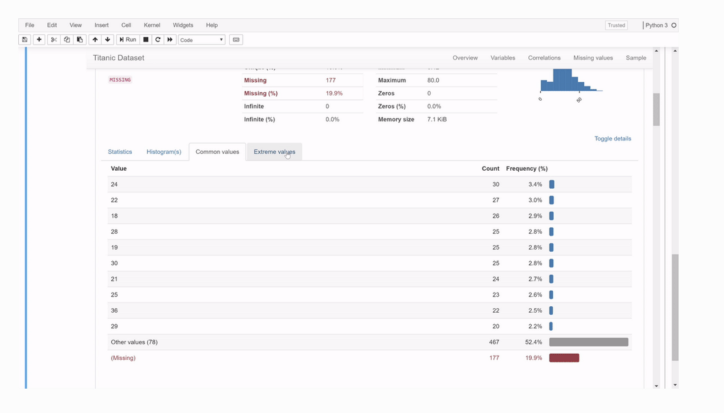
다음은 문서 웹 사이트 에 설명된 대로 Pandas 프로파일링 기능에 대한 전체 설명입니다 .

두 가지 정말 강력한 기능은 결 측값 및 기술 통계 에 대한 보고서입니다 . 새 데이터 세트를 분석할 때 누락된 값을 처리하는 것이 어려울 수 있습니다. Pandas 프로파일링은 이 프로세스를 훨씬 쉽게 만듭니다. 기술 통계는 분석을 진행하기 전에 데이터 세트를 더 깊이 이해하는 데 유용합니다.
Lux는 데이터 시각화를 위한 훌륭한 패키지입니다. 원하는 차트를 만들기 위해 코드를 정확하게 맞추는 지루함은 시간을 크게 단축시킬 수 있습니다. Lux는 버튼 클릭으로 선택할 수 있는 그래프를 추천합니다.
Lux는 모든 데이터 프레임에 적용할 수 있으며 사용자가 선택할 수 있는 그래프를 자동으로 제안합니다.
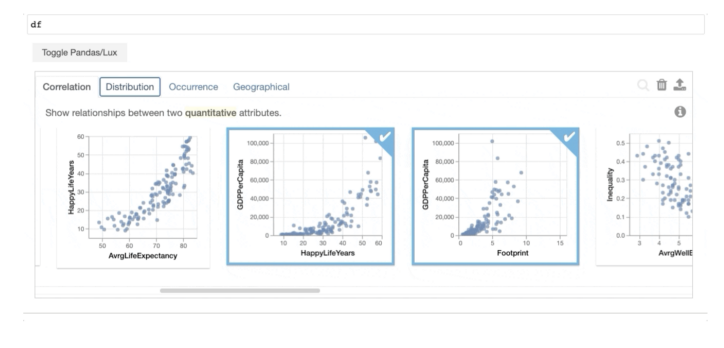
사용자는 Intent 함수를 사용하여 탐색하려는 열을 전달할 수도 있으며 Lux는 자동으로 그래프를 제안합니다.
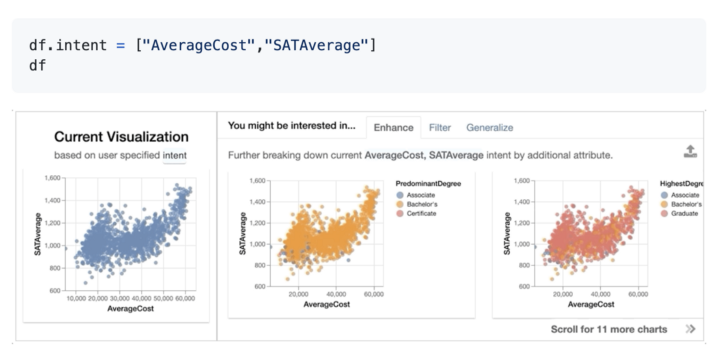
Lux는 간단한 Python 라인으로 설치할 수 있습니다.
**pip install lux-api**
[출처] https://ichi.pro/ko/deiteo-gwahag-eul-dansunhage-mandeuneun-3gaji-python-paekiji-70868267050386
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.