
재고되고 있는 데이터 정규화, Part 2: 21세기의 비즈니스 기록
2012.07.07 00:29
◎ 연재기사 ◎
▷ 재고되고 있는 데이터 정규화, Part 1: 비즈니스 기록의 역사
▶ 재고되고 있는 데이터 정규화, Part 2: 21세기의 비즈니스 기록
재고되고 있는 데이터 정규화, Part 2: 21세기의 비즈니스 기록
컴퓨터 시스템에서 유지되는 기록의 조사
소개
두 파트로 구성된 이 시리즈의 첫 번째 파트에서는 21세기 이전의 기록 보존 체계와 관계형 데이터베이스 및 웹의 효과를 살펴보았다. 컴퓨팅 시스템이 도입되기 전에는 비즈니스 기록을 원래의 비정규화된 형식으로 그대로 저장했다. 이러한 사례로는 석판, 엄대 및 종이 양식이 있다. 컴퓨팅 시스템이 도입되면서 비즈니스 기록을 공간을 절약하고 데이터베이스에서 이상 항목을 업데이트하지 않아도 되는 다양한 표현으로 변환하기 위해 데이터 정규화가 고안되었다. 그러나 정규화된 표현은 원래의 데이터와는 매우 다르고 이해하기도 어렵다.
두 파트로 구성된 이 시리즈의 두 번째 파트에서는 데이터 형식의 경향과 21세기의 비즈니스 기록을 살펴본다. 여기에서는 먼저, 사례 연구를 통해 정규화하지 않고 디지털화한 비즈니스 기록의 이점, 즉 우수한 성능과 낮은 애플리케이션 개발 및 유지보수 비용을 강조한다. 또한, JSON 및 RDF와 같은 기타 새로운 데이터 표현을 살펴보고 관련된 사용 시나리오에 대해 이러한 표현의 장단점을 집중적으로 설명한다.
관계형 및 XML 데이터 표현: 비교
오늘날에는 많은 시스템과 애플리케이션이 비즈니스 기록을 XML 문서로 작성하고 표현한다. 예를 들면, 각각의 주문, 금융 거래, 세금 반환, 보험 청구 등은 주로 별도의 XML 문서로 되어 있다. 그 이유는 XML이 확장 가능하고 유연하며 자기 기술적이고 구조화된 정보와 비구조화된 정보 및 반구조화된 정보에 적합하기 때문이다. XML의 이러한 특성 때문에 훨씬 더 복잡한 기록을 표현하고, 필요에 따라 데이터 표현을 확장하고, 애플리케이션(A2A)이나 조직(B2B) 간에 비즈니스 기록을 교환하기가 용이하다. 이로 인해 XML은 웹 서비스와 SOA(Service-Oriented Architecture)에 적합한 데이터 형식이 되었다. 이러한 경향에 대응하여 주요 데이터베이스 벤더는 그들의 제품에[1] [3] [5] XML 기능을 추가했으며 여러 가지 XML 전용 데이터베이스가 출현했다[6]. 이러한 제품에서는 관계형 데이터와 동일한 여러 가지 특성(예: ACID 트랜잭션, 복구 가능성, 확장 가능성, 고가용성)을 사용하여 XML을 저장 및 인덱스화하고, 쿼리 및 업데이트할 수 있다. 이러한 데이터베이스 기술의 발전 덕택에 비즈니스 기록을 원래의 형식, 즉 XML로 저장하고 관리할 수 있게 되었다. 이 섹션에서는 (역)정규화와 중복 및 성능 관점에서 XML과 관계형 데이터베이스를 비교한다.
예제
XML은 계층 구조적 데이터 형식이기 때문에 일대다 관계를 불연속 오브젝트 세트로 정규화하지 않고도 하나의 문서로 이러한 관계를 얼마든지 표현할 수 있다. 고객을 설명하는 비즈니스 기록을 생각해 보면, 각 고객에게는 주소, 휴대전화 번호, 이메일 주소, 중간 이름 및 투자 계정이 여러 개 있을 수 있다. 게다가, 각 고객의 계정에는 여러 가지 포지션(보유)이 있을 수 있고, 각 주소에는 "거리" 항목이 여러 개 있을 수 있다. 그림 1에 표시되어 있듯이 정규화된 관계형 스키마에서는 이러한 각각의 일대다 관계를 유지하려면 추가로 테이블이 필요하다. 결국, 하나의 비즈니스 기록을 저장하려면 여러 개의 테이블에 다수의 SQL INSERT 문이 있어야 하며 이 예제에서는 12개의 테이블에 최대 12개의 INSERT 문이 필요하다.
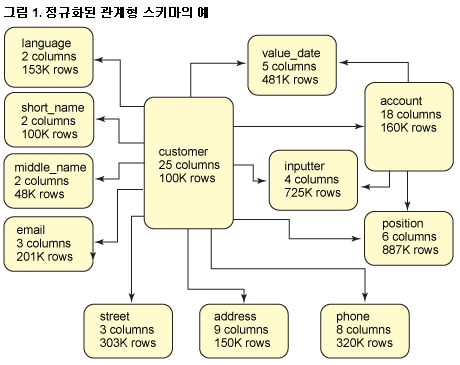
마찬가지로 애플리케이션이 하나의 고객 레코드를 검색할 때는 12개의 테이블 모두를 대상으로 SELECT 문을 실행해야 한다. 이 프로세스를 수행하려면 데이터베이스에 대한 별도의 API 호출이 12개 이상 필요하기 때문에 이 프로세스는 비효율적이다. 이렇게 호출될 때마다 네트워크 트래픽이 발생하며 데이터베이스 테이블과, 테이블 및 인덱스로 향하는 실제 I/O에 액세스하게 된다. 12개의 테이블 모두를 결합하는 하나의 쿼리가 일반적으로 훨씬 더 나쁘다. 예를 들어, 표 1 - 3에 표시되어 있듯이 고객에게 총 7개의 포지션이 있는 3개의 계정이 있는 경우에는 표 4에 표시되어 있듯이 이러한 세 개의 테이블 간의 결합에서 7개의 열이 리턴된다. 이 결과 세트에서는 고객 테이블에서 선택된 값이 일곱 번 반복되었으며 모든 계정의 값이 계정의 각 포지션에 대해 반복되었다. 이러한 중복으로 인해 결과 세트의 크기가 증가되고 클라이언트 서버 간의 통신이 지연되어 성능이 악화된다. 더 많은 테이블이 결합에 추가되면 결과 세트는 빠르게 증가하고 이로 인해 문제점이 확대된다.
표 1 - 3에는 고객, 계정 및 포지션 데이터의 정규화된 관계형 스키마가 표시되어 있다.
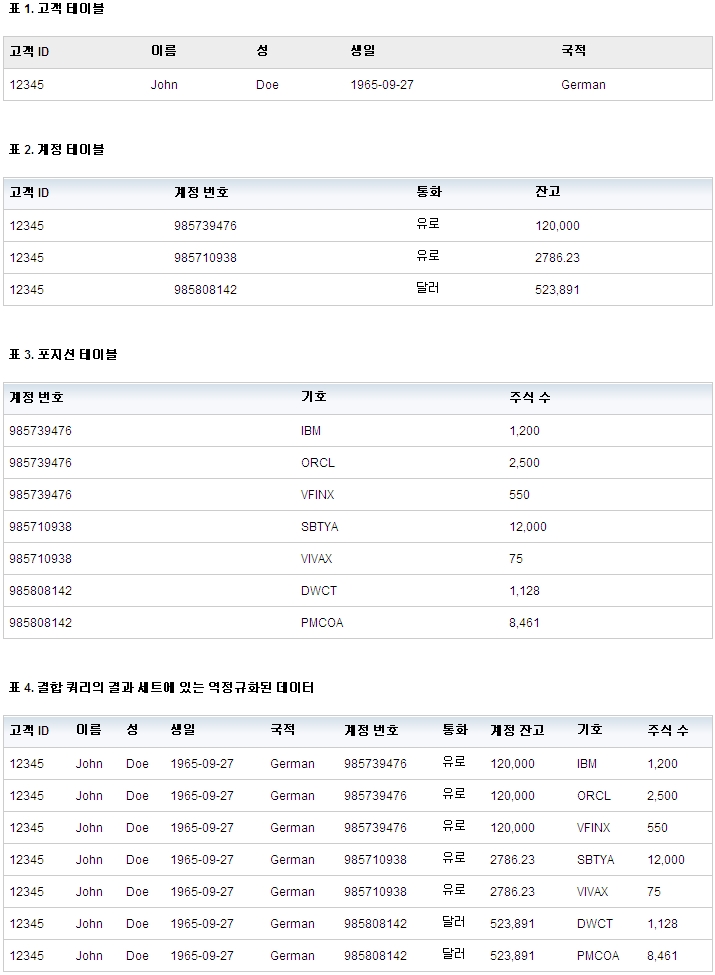
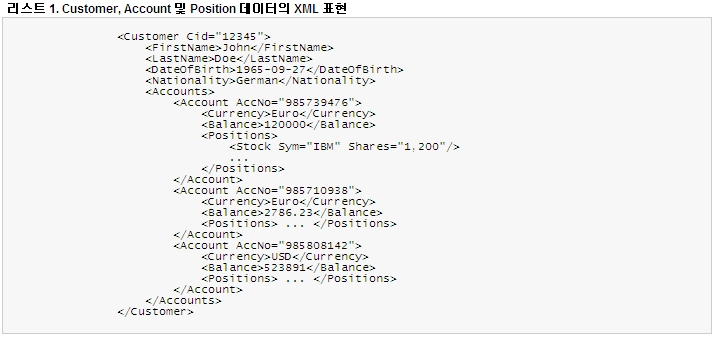
또한, 표 4에서는 데이터베이스 스키마를 역정규화하는 과정에서 데이터 중복이 발생한다는 것을 알 수 있다. 목록 1에는 동일한 논리적 비즈니스 기록을 XML로 표현한 코드가 표시되어 있다. 정규화된 관계형 스키마는 고객 정보를 다수의 테이블에 분산하는 반면에 XML의 트리 구조는 동일한 일대다 관계를 하나의 문서로 표현한다. 동시에 "Account"와 같은 각 하위 노드에서는 "Customer"와 같은 상위 노드가 반복되지 않기 때문에 XML 문서에는 중복된 부분이 없게 된다. 따라서 XML은 중복을 일으키지 않고도 비정규화된 하나의 문서로 비즈니스 기록을 표현할 수 있다. 결국, 하나의 SQL문으로 비즈니스 기록을 삽입하거나 검색할 수 있게 되어 데이터베이스 API 호출 수, 애플리케이션 복잡도, CPU 비용 및 네트워크 트래픽을 줄일 수 있게 된다. 다음 섹션에서 살펴보겠지만, 이러한 장점은 다수의 상업용 데이터베이스 시스템에서 관찰되고 평가되었다.
OLTP 시스템에서의 XML과 관계형 구조의 성능 비교
비즈니스 기록을 정규화된 관계형 열 대신 비정규화된 하나의 XML 문서로 삽입하고 검색함으로써 얻을 수 있는 이점은 데이터베이스 전문가 사이에서 주목을 끌었다. 전세계에 있는 주요 물류 사업자는 이러한 가치 제안을 테스트했다. 그들의 OLTP 시스템 중 하나는 특정 비즈니스 기록을 12개의 테이블로 구성된 정규화된 관계형 스키마로 표현한다. 비즈니스 기록 하나를 검색하려면 애플리케이션은 15개의 SQL문을 실행해야 한다. 대부분의 비즈니스 기록은 15개의 열로 표현되지만, 일부는 수백 개의 열로 구성된다. 그들은 비교를 위해 25만 개의 비즈니스 기록을 선택하여 하나의 비즈니스 기록을 하나의 XML 문서로 변환했다. 대부분 문서는 크기가 1 - 2KB였지만 일부 문서의 크기는 최대 500KB였다.
테스트 시나리오에서는 32GB 메모리의 8 코어 AMD Opteron 서버에서 Linux RHEL 4.6과 DB2 9.5 수정팩 4를 사용했다. 최대 7개의 클라이언트 시스템을 사용하여 데이터베이스에 액세스하는 동시 사용자 수가 증가하는 과정을 시뮬레이션했다. 각 클라이언트는 IBM xSeries 345(2 코어) 시스템이었다. 12개의 관계형 테이블 각각에는 적절한 인덱스가 있었다. 비교를 위해 XML 문서를 하나의 테이블과, 레코드 ID 속성에 하나의 XML 인덱스가 있는 하나의 XML 열에 저장했다. 관계형 테스트에서는 시뮬레이션된 각각의 동시 사용자가 무작위로 레코드 ID를 선택했으며, 각 ID로 15개의 SQL 쿼리로 된 트랜잭션을 실행하여 해?? 고려되지 않았다. XML 테스트에서 각 동시 사용자는 레코드 ID를 무작위로 선택하여 XMLEXISTS 조건부에서 XPath 표현식으로 하나의 SQL/XML 쿼리를 실행하여 XML 문서를 검색했다.
그 결과는 그림 2에 표시되어 있다. 평균적으로 XML 솔루션은 정규화된 관계형 스키마보다 처리 속도가 55% 더 빨랐다. 관계형 테스트에서는 84명의 사용자가 초당 약 3800개의 트랜잭션을 동시에 수행하자 테스트에 사용된 시스템의 CPU 용량이 고갈되었다. XML 솔루션을 사용한 경우에는 동일한 시스템이 최대 150명의 동시 사용자와 초당 약 6000개의 트랜잭션을 지원했다. 동시에 XML 솔루션은 관계형 솔루션보다 클라이언트 시스템의 CPU 사용량이 매우 낮았다.


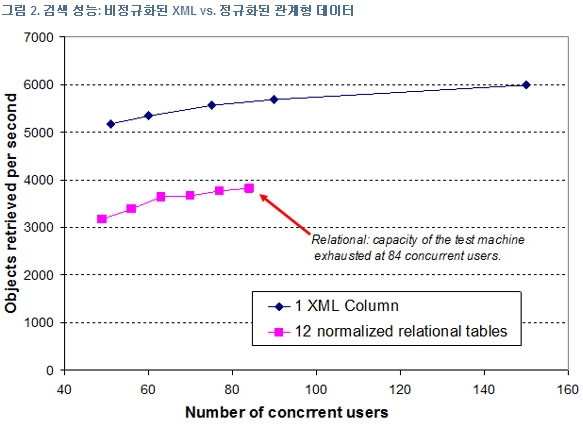
물류 회사의 경우에는 성능이 높아지고 CPU 사용량이 낮아진다는 점 외에도 비정규화된 XML 솔루션의 이점이 많이 있다. 예를 들면, 각 XML 문서는 클라이언트 애플리케이션이 바로 사용할 수 있게 되지만, 검색된 관계형 열을 사용하려면 비즈니스 기록을 구성해야 하기 때문에 그림 2에는 표시되어 있지 않지만 추가 작업이 필요하다. 또한, XML 솔루션에는 더 단순한 데이터베이스 스키마가 있어서 시간이 경과하여 기록 형식이 발전되었을 때 유지보수하기가 더 수월하다. 비즈니스 기록이 데이터베이스와 애플리케이션(XML)에서 동일하게 표현되기 때문에 애플리케이션 개발이 단순해진다. 이러한 이점은 XML 기반 유형 처리, 이벤트 로깅 및 주문 처리에서도[??4] 보고되었다.
XML에 액세스하는 것이 동일한 비즈니스 기록을 표현하는 정규화된 관계형 테이블에 동일하게 액세스하는 것보다 CPU를 적게 사용한다. 비즈니스 기록 자체를 XML로 전송하는 대신 관계형 결합으로 비즈니스 기록을 재구성하면 데이터베이스와 클라이언트 간에 더 많은 데이터가 전송된다. 게다가, XML은 실제 비즈니스 기록과 동일하지는 않다고 해도 더 유사하기 때문에 이해하기가 더 수월하다. 별도의 논리적 데이터 모델은 더 이상 필요하지 않다. 실제 비즈니스 기록과 컴퓨터 안에 저장된 기록 간의 맵핑이 필요하지 않다.
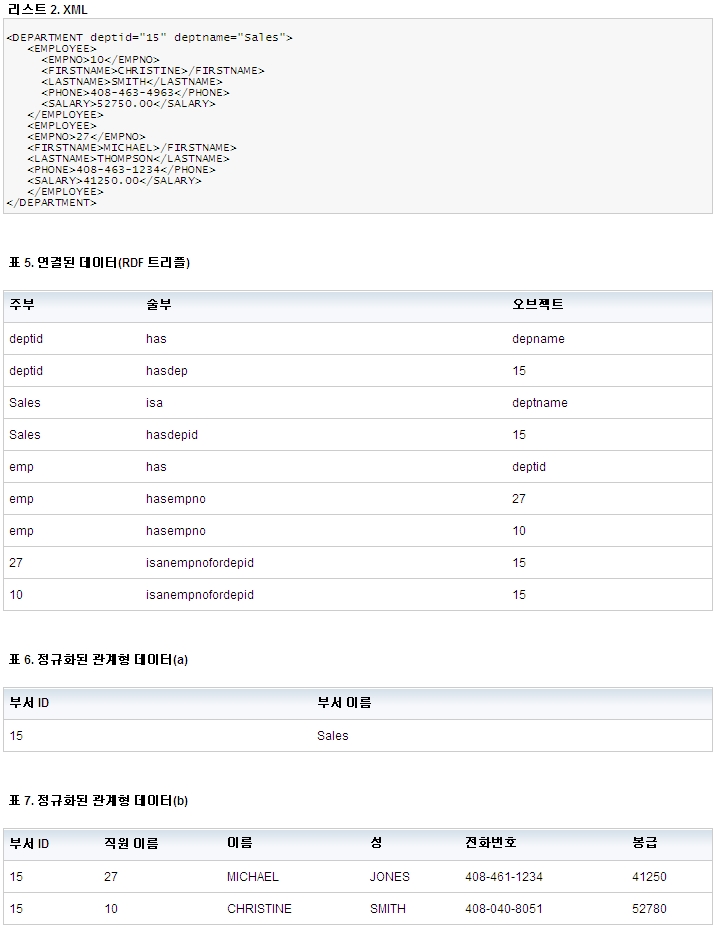
정규화를 통해 데이터를 트리플로 변환하는 과정은 강력한 통합을 이끌어 낼 수 있는 RDF 저장소를 형성하는, 시맨틱 웹의 핵심 부분이다. 정보를 가장 작은 요소인 트리플로 분할하면, 주부와 오브젝트를 노드로하고 술부를 연결부로 하는 그래프로 데이터를 표현할 수 있다. 추론 소프트웨어(추론자)는 그래프를 분석하고 규칙을 적용하여 새로운 문장을 추론할 수 있다. 예를 들면, 부서에는 직원이 있고 인적자원이 부서이면 인적자원에는 직원이 있다고 추론할 수 있다.
관계형 테이블의 기본 키와 외부 키가 그러하듯이 연결된 데이터 링크는 일반적으로 최신 정보만 연결한다. 예를 들면, 관계형 키를 링크하거나 탐색하여 생성되는 주문의 감사는 현재의 고객 주소를 선택하지, 주문을 한 시점에서의 고객 주소를 선택하지는 않는다. 비즈니스 시스템에서는 감사와 준수상의 이유로 주문 수령이나 계좌 입출금내역서 발생과 같은 중요한 이벤트가 발생하는 시점에서 관련된 비즈니스 정보의 스냅샷을 작성해야 한다. 스냅샷의 목적은 나중에 탐색하기 위한 것이 아니라 감사나 쿼리가 이루어질 때 비즈니스 기록을 재생성하기 위한 것이다. 때로는 비즈니스 기록이 작성된 이후로 변조되지 않았다는 증거로 스냅샷에 서명을 한다.
극도로 정규화된 형식인 RDF는 버전화를 처리하고 히스토리와 감사를 관리하기 어렵다는 점에서 정규화된 관계형 데이터와 유사하다. RDF는 고정된 스키마에 구속되지 않는다는 점에서 정규화된 관계형 데이터와 다르다. 자원에 특성이 새로 추가되면 특성을 쉽게 표현하기 위해 추가적 문장(트리플)을 추가한다. 그러나 트리플이 기존의 관계형 스키마보다 쿼리하기가 더 어려울 수 있다.
연결된 데이터와 시맨틱 웹의 메커니즘은 강력하여 겉으로는 관련이 없는 시스템을 통합할 수 있다. 호텔과 항공권 예약, 주문 처리 또는 보험 연장을 소셜 네트워킹 정보와 통합하는 것을 예로 들 수 있다. 시맨틱 어노테이션(트리플)으로 XML 형식의 비즈니스 기록을 증대하면 기존의 비즈니스 기록을 연결된 데이터 및 시맨틱 웹 구성과 융합할 수 있다. 실제로 Best Buy(미국 소매상점)에서는 검색 엔진 및 분류기와 같은 프로그램을 통해 처리할 수 있는 RDF(RDF 어노테이션)를 사용하여 제품을 기술하는 XHTML 페이지를 어노테이션한다[??9].
관계형 데이터베이스 스키마를 변경하지 않으면서 관계형 데이터를 증대할 수 있는 메커니즘이 없기 때문에, 어노테이션을 적용하기가 수월한 XML 비즈니스 기록과 비교해 볼 때 관계형 데이터베이스는 시맨틱 어노테이션과 융합하기가 더 어렵다.
JSON
JSON(JavaScript Object Notation)은 Javascript 프로그래밍 언어의 서브세트를 기반으로 하며 정보를 Javascript 클라이언트에 표시하기 위해 널리 사용된다[?10]. 실제로 많은 REST 및 웹 API가 XML과 JSON 변종을 모두 제공한다. JSON은 Javascript로 사용자 인터페이스를 빌드하는 데 적합한 경량 데이터 교환 형식이다. JSON은 사람이 읽고 쓰기가 수월하며 Javascript로 구문 분석하고 생성하기도 쉽다. 표 8에는 데이터 샘플이 있을 뿐만 아니라 JSON과 XML 표기법도 비교되어 있다.
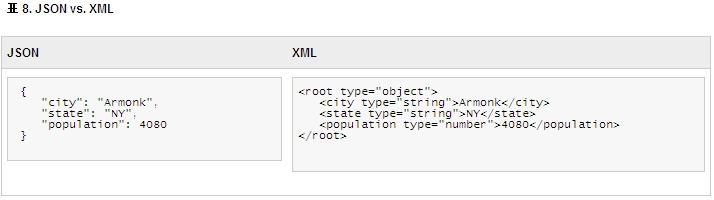
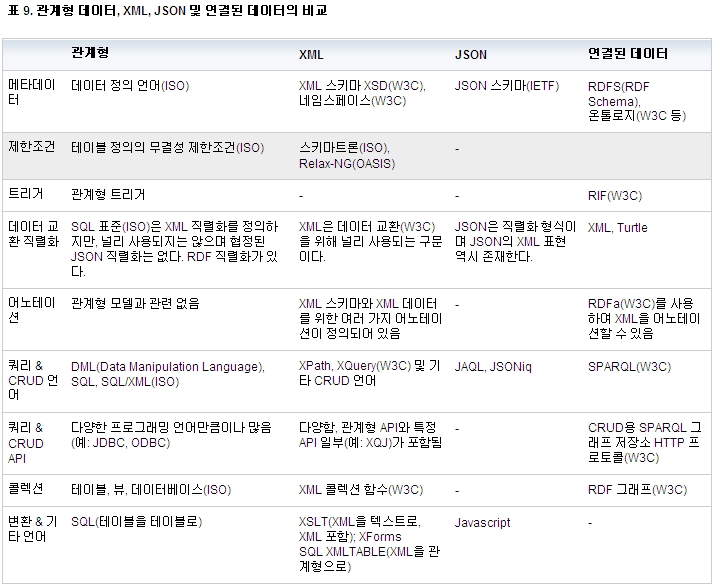
JSON은 쿼리 결과를 즉시 형식화하여 Javascript 클라이언트에 맞게 처리를 단순화하는 데 매우 적합하다. 따라서 JSON은 웹 애플리케이션에 매우 적합하다. 그러나 JSON에는 네임스페이스가 없기 때문에 제한조건이 사용 가능한 경우에도 이 제한조건을 손쉽게 공유하거나 확장 또는 혼합할 수 없다. 스키마 또는 변환 언어와 같은 JSON 스펙에 대한 지원은 존재하지 않거나 XML 스펙에 못미친다. 데이터 정규화 면에서 JSON에 XML과 같은 이점이 일부 있다고 하더라도 표 9에 표시되어 있듯이 JSON은 XML만큼 성숙되지 않았다.
요약
초기에 매우 상업적인 프로젝트에서 시작된 프로세스인 데이터 정규화로 인해 비즈니스 기록을 거의 언제나 원래의 형식인 XML로 저장하지 못한다. 게다가 XML 비즈니스 기록에 대한 작업은 비효율적이라고 여겨지기도 한다. 이 기사에 있는 성능 비교 결과를 살펴보면 이러한 생각이 꼭 타당한 것은 아니라는 점을 알 수 있다. 사실상, 정규화된 테이블에서 비즈니스 기록을 검색하고 재구성하는 데 들어가는 비용이 비정규화된 XML 문서를 원래대로 저장하고 검색하는 데 필요한 비용보다 더 높은 경우가 많다. 그래서 XML을 비즈니스 기록을 표현하기 위해 사용하는 경우에는 XML을 해당 저장 형식으로 고려해야 한다. 오브젝트 지향 데이터 액세스는 정규화된 관계형 테이블보다는 XML에서 더 잘 수행되며 높은 XML 트랜잭션 비율을 허용한다[2]. 또한, XML을 이용하면 관계형 테이블과 XML 간의 맵핑을 설계하고 유지보수할 필요가 없기 때문에 신속하게 애플리케이션 프로토타입을 작성하여 애플리케이션을 개발하고 발전시켜나갈 수 있다.
또한, Google Big Table 및 HBase와 같은 새로운 스토리지 시스템은 정규화를 하지 않는다. 이러한 시스템에서는 강력한 역정규화를 따르고 데이터를 액세스하는 방식에 따라 데이터를 저장일치하는 수준에서 가장 잘 저장된다는 사실은 XML 데이터?이터, 시맨틱 웹 및 JSON은 최근에 생겨난 데이터 표현이지만 아직은 비즈니스 시스템에서 시스템 간 데이터 교환을 위해 널리 사용되고 있지는 않다. 정규화를 통해 데이터를 트리플로 변환하는 과정은 추론을 통해 새로운 사실을 이끌어낼 수 있는 RDF 저장소를 형성하는, 시맨틱 웹의 핵심 부분이다. XML로 표현된 비즈니스 기록을 RDFa와 같은 시맨틱 어노테이션으로 증대하면 기존의 비즈니스 기록을 연결된 데이터 및 시맨틱 웹과 융합할 수 있다.
이러한 발전에도 불구하고 정규화는 여전히 사용되고 있다. 정규화는 여전히 유용하며, 예를 들어 높은 업데이트 율을 지원하는 기존의 관계형 트랜잭션 처리 시스템에서는 원래의 비즈니스 기록을 거의 재구성하지 않아도 될 뿐만 아니리 기존 업데이트 대신 새 레코드 버전을 삽입하지도 않는다(표 10 참조).

관계형 데이터베이스 시스템, 데이터 정규화 및 XML로 표현된 비즈니스 기록은 그 당시에는 모두 타당한 이유가 있었기 때문에 대단한 성공을 거둘 수 있었다. 21세기에는 일반적으로 비즈니스 기록을 "그대로" 저장하고 조작한다. 실제 세계와의 유사성을 비교하자면, 사람은 장롱안에 있는 의복 및 주차장 안에 있는 자동차와 같은 실물을 취득하여 조작하고 저장한다. 이러한 것들은 주요한 액세스 유형에 매우 적합한 형태로 저장된다. 다시 말해서 자동차와 의복은 먼저 여러 개의 조각으로 분해되지 않고 그대로 저장된다(그림 3 참조).

결론
두 파트로 구성된 이 시리즈에서는 비즈니스 기록을 변경하지 않고 저장하고 데이터 관리 솔루션을 신속하게 전달하지 못하게 하는 주요 장벽을 데이터 정규화로 간주했다. 효과적인 XML 데이터베이스는 즉시 사용 가능하지만[7], 시스템 설계의 초기 단계에서 정규화가 통합되어 원래의 비즈니스 기록을 추적할 수 있는 모든 데이터가 제거되기 때문에 XML 데이터베이스의 효율성이 간과되는 경우가 많다. 데이터 정규화는 조심스럽게 재고되어야 한다.
출처 : 한국IBM
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 7 |
[정보처리기술사][데이터베이스] [DB] DB확장을 하는 두가지 방법- 스케일 아웃(scale out)과 스케일 업 (scale up)
| 졸리운_곰 | 2021.03.07 | 211 |
| 6 |
DB와 미들웨어 간 인터페이스에 대한 변화와 전망(2회)
| 가을의 곰 | 2013.01.18 | 1141 |
| 5 |
미들웨어 발전 방향에 비춰본 DB 인터페이스의 변화
| 가을의 곰 | 2013.01.18 | 1428 |
| 4 |
MongoDB 탐구
| 가을의 곰을... | 2012.07.07 | 1617 |
| » |
재고되고 있는 데이터 정규화, Part 2: 21세기의 비즈니스 기록
| 가을의 곰을... | 2012.07.07 | 1304 |
| 2 |
재고되고 있는 데이터 정규화, Part 1: 비즈니스 기록의 역사
| 가을의 곰을... | 2012.07.07 | 1879 |
| 1 |
서적 "SQL 기초2" 주에서 발최
| 가을의 곰을... | 2009.11.07 | 2776 |