
- 전체
- JAVA 일반
- JAVA 수학
- JAVA 그래픽
- JAVA 자료구조
- JAVA 인공지능
- JAVA 인터넷
- Java Framework
- Java GUI (AWT,SWING,SWT,JFACE)
- SWT and RCP (web RAP/RWT)[eclipse], EMF
JAVA 인공지능 [Weka] Weka를 이용한 Iris 데이터 머신러닝
2020.01.30 21:29
[Weka] Weka를 이용한 Iris 데이터 머신러닝
머신러닝을 위한 프로그램을 찾아보다가 사용하기 쉬워보이는 프로그램이 있어서 바로 다운을 받았다.
프로그램 이름은 Weka(웨카)이고 사용 방법만 알면 몇 번의 클릭으로 머신러닝을 수행할 수 있는 프로그램이다.
프로그램은 웨카 홈페이지(https://www.cs.waikato.ac.nz/ml/weka/)에서 받을 수 있다.
웨카 홈페이지 -> 소프트웨어 -> 다운로드에 들어가서
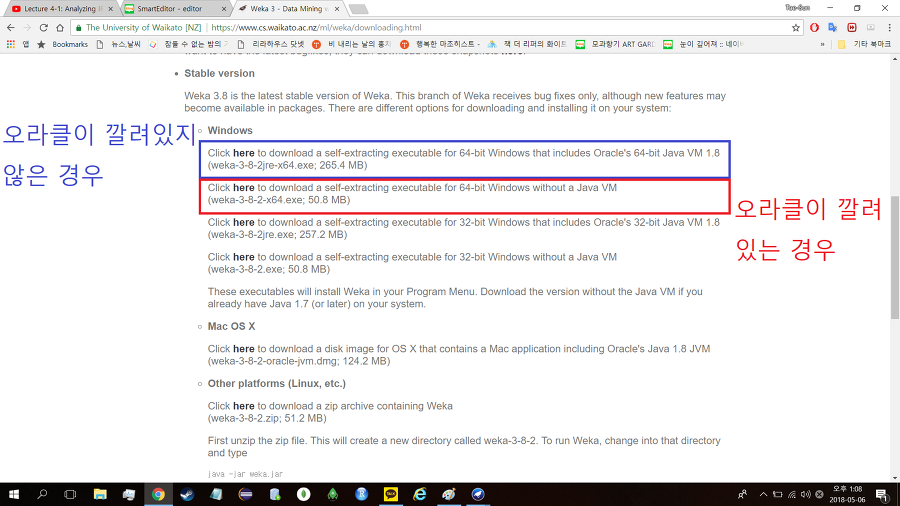
1. 오라클이 컴퓨터에 깔려있지 않다면 위
2. 오라클리 컴퓨터에 깔려있다면 아래
이렇게 다운받으면 된다.
설치는 계속 NEXT를 누르고 Finish를 해주면된다.
이 포스트에서는 웨카에 있는 기본데이터를 이용할 예정이지만 더 많은 자료를 원한다면
웨카 홈페이지 -> 소프트웨어 -> 데이터셋 에 들어가면 된다.
이제 분석을 시작해보자.
웨카를 실행시키고 Explorer를 누른다.
그럼 이제 데이터를 불러와보자.
오픈 파일(Open file...)을 누르고 C:\Program Files\Weka-3-8\data에 있는 iris.arff파일을 불러온다.
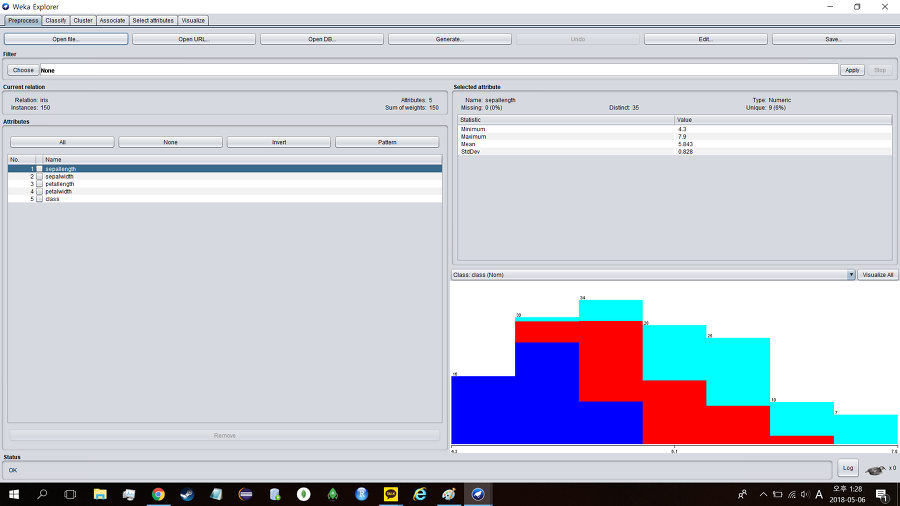
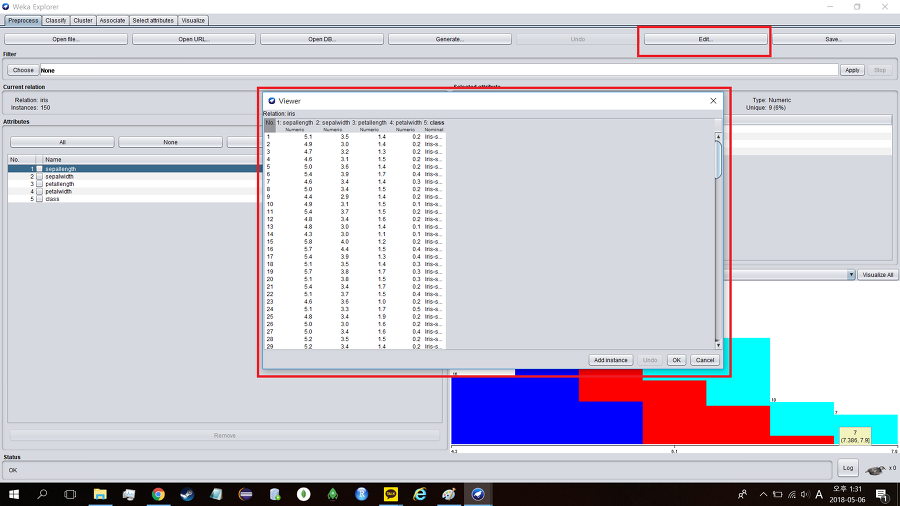
어떤 데이터가 들어가 있는지 확인하기 위해 에딧(Edit...)을 눌러 확인해본다.
비주얼라이즈 올(Visualize all)을 이용하면 들어있는 데이터를 시각화 된 자료로도 볼 수 있다.
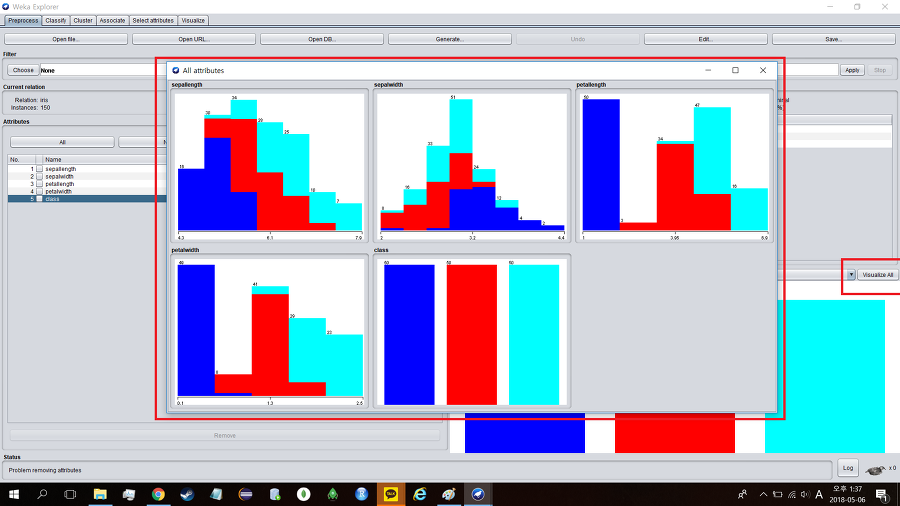
막대그래프가 아닌 상관관계 분석을 보고 싶다면 비주얼라이즈(Visualize)탭에 들어가면 된다.


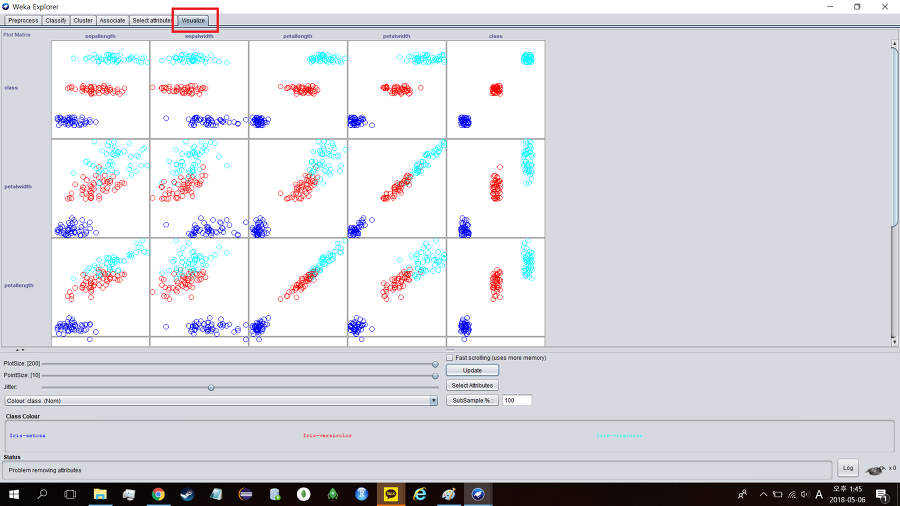
각 그래프를 눌러보면 더 자세한 정보를 얻을 수 있다.
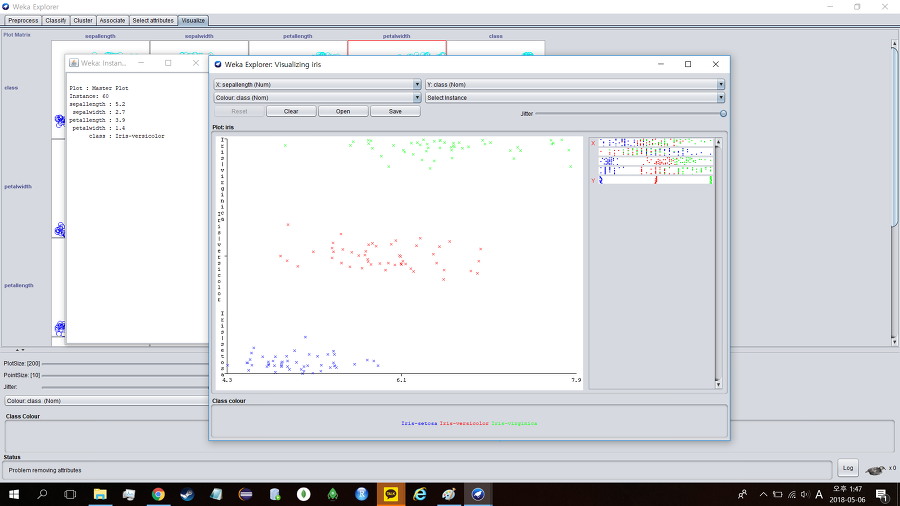
그러면 본격적으로 분석을 시작하겠다.
속성값 설정을 먼저 해보자.
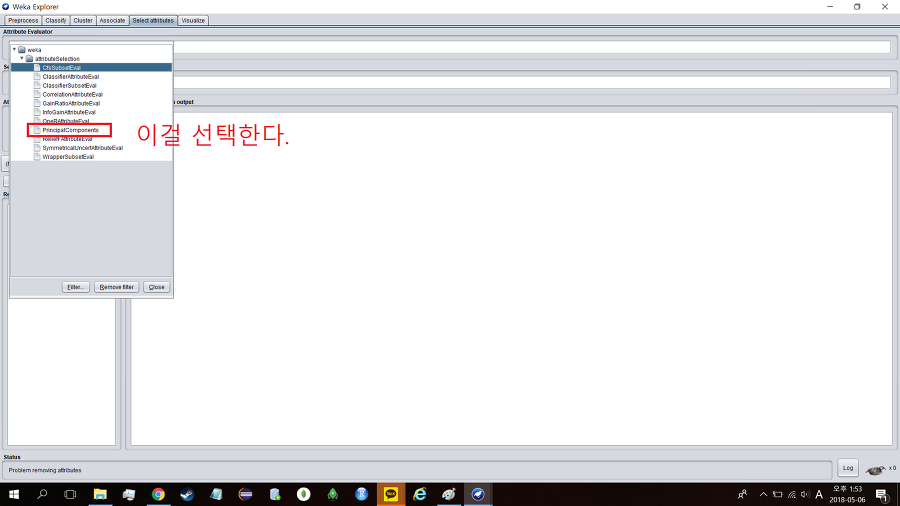
셀렉트 애트리뷰트즈(select attributes) 탭에 들어가서 애트리뷰트 이벨류에이터(attribute evaluator)를 변경할 것이다.
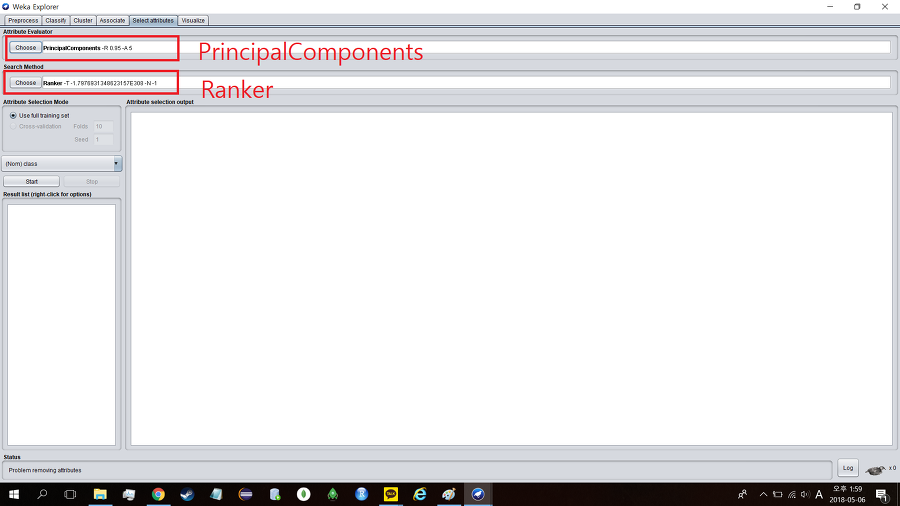
디폴트는 CfsSubSetEval인데 PrincipalComponents로 바꿔준다. PrincipalComponents는 주성분 분석을 한다는 의미로 표본의 차이를 잘 나타내는 성분으로 분해하여 분석하는 기법을 말한다.
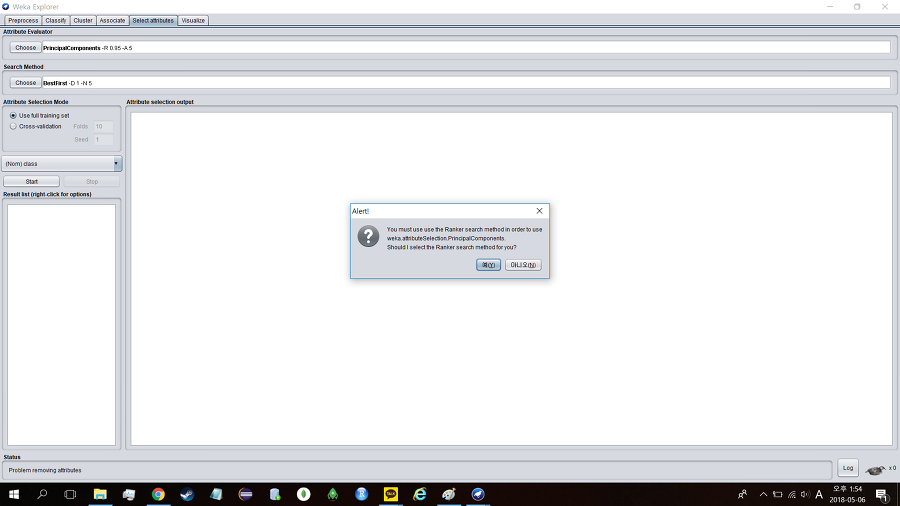
PrincipalComponents를 선택하면 서치 메서드(serch method)가 적절하지 않다는 창이 뜨면서 Ranker를 사용하라고 나올 것이다. Yes를 누르고 진행하면 된다.
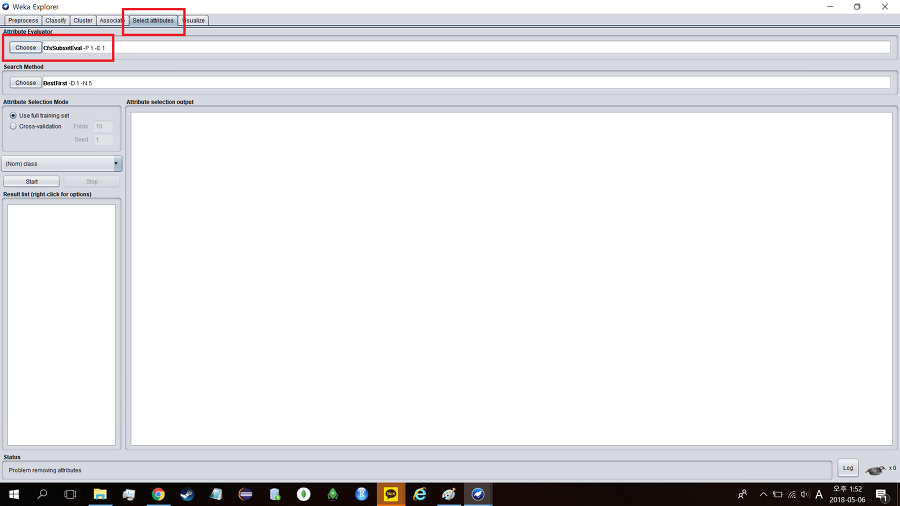
이제 스타트(start)를 눌러 분석을 해보자.
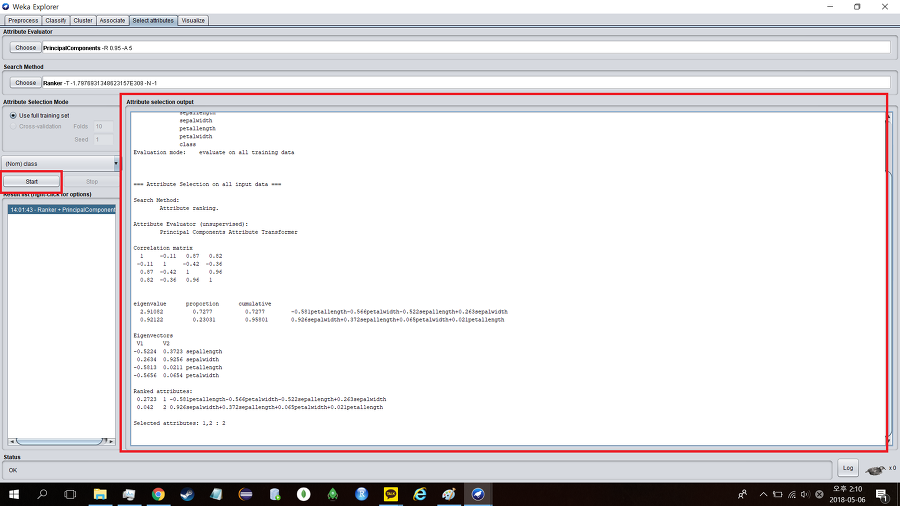
속성 분석이 끝났다.
Correlation matrix
1 -0.11 0.87 0.82
-0.11 1 -0.42 -0.36
0.87 -0.42 1 0.96
0.82 -0.36 0.96 1
1.
eigenvalue proportion cumulative
2.91082 0.7277 0.7277
-0.581petallength-0.566petalwidth-0.522sepallength+0.263sepalwidth
2.
eigenvalue proportion cumulative
0.92122 0.23031 0.95801
0.926sepalwidth+0.372sepallength+0.065petalwidth+0.021petallength
Eigenvectors
V1 V2
-0.5224 0.3723 sepallength
0.2634 0.9256 sepalwidth
-0.5813 0.0211 petallength
-0.5656 0.0654 petalwidth
주성분 분석의 결과는 첫 주성분 proportion 0.7277 두 번째 주성분 proportion 0.23031로 이 두 개를 합하면 0.95807로 아주 정확한 분석이 가능하다는 결론을 얻었다. 이 중, 첫 번째는 70%이상을 설명하기 때문에 첫 주성분 분석에서 가중치가 큰 Petallength, Petalwidth를 설명 변수로 채택하였다.
그럼 이제 본격적으로 머신러닝을 시작해보자.
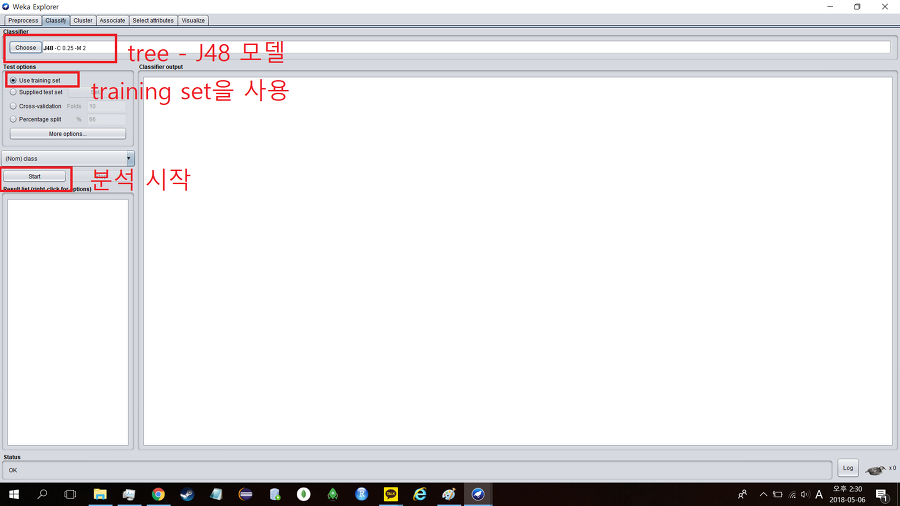
클래시파이(classify)에 들어가서 테스트 옵션(test option)을 유즈 트레이닝 셋(use training set)으로 설정하고 사용할 모델은 J48 알고리즘(C4.5 decision tree algorithm) 을 사용한다.
스타트(start)버튼을 눌러서 분석을 시작한다.
분석을 통해 어떤 결과를 얻었는지 확인해보자.
J48 pruned tree
------------------
petalwidth <= 0.6: Iris-setosa (50.0)
petalwidth > 0.6
| petalwidth <= 1.7
| | petallength <= 4.9: Iris-versicolor (48.0/1.0)
| | petallength > 4.9
| | | petalwidth <= 1.5: Iris-virginica (3.0)
| | | petalwidth > 1.5: Iris-versicolor (3.0/1.0)
| petalwidth > 1.7: Iris-virginica (46.0/1.0)
Number of Leaves : 5
Size of the tree : 9
=== Summary ===
Correctly Classified Instances 147 98 %
Incorrectly Classified Instances 3 2 %
Kappa statistic 0.97
Mean absolute error 0.0233
Root mean squared error 0.108
Relative absolute error 5.2482 %
Root relative squared error 22.9089 %
Total Number of Instances 150
=== Confusion Matrix ===
a b c <-- classified as
50 0 0 | a = Iris-setosa
0 49 1 | b = Iris-versicolor
0 2 48 | c = Iris-virginica
결과의 가독성을 높이기 위해서 모델 시각화를 해보자.
결과 데이터에 오른쪽 클릭을 하고 비주얼라이즈 트리(Visualize tree)를 눌러보자.
위에 있는 트리모델을 보다 더 정확하게 볼 수 있다.
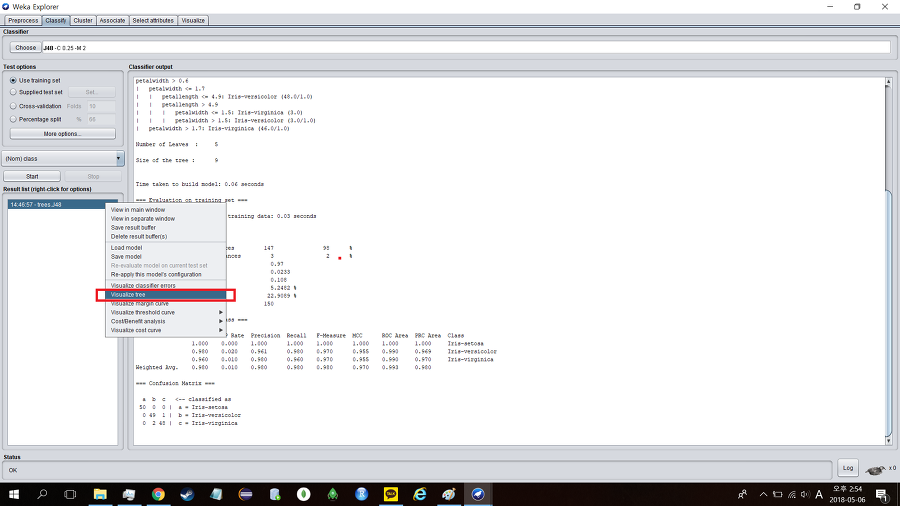
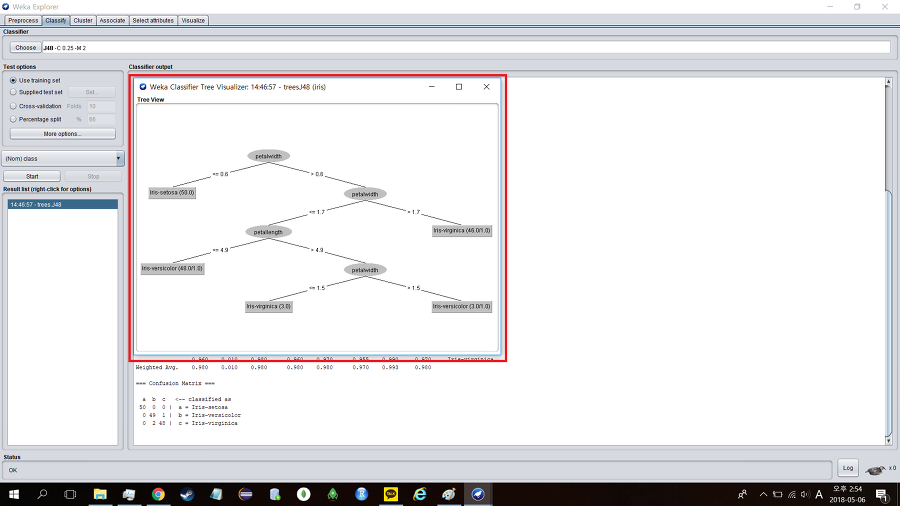

해석해보자면 petalwidth의 크기가 0.6보다 작거나 같은걸로 시작하여 petalwidth, petallength의 값만 있으면 iris가 어떤 종인지 확인 할 수 있다는 결과를 얻은 것이다.
즉, petalwidth가 0.6보다 작으면 setosa 종이고 0.6보다 큰 경우에는 아래로 내려간다.
petalwidth의 크기가 1.7보다 크면 virginica종일 확률이 크고 1.7보다 작거나 같으면 아래로 내려간다.
petallength가 4.9보다 작거나 같으면 versicolor종일 확률이 크고 4.9보다 크면 아래로 내려간다.
petalwidth가 1.5보다 작거나 같으면 virginica종이고 1.5보다 크면 versicolor일 확률이 있다.
Weka 머신러닝을 이용하여 데이터 분석을 해보았다.
버튼 몇 번만 누르면 쉽게 사용할 수 있어 편리한 툴이라고 생각한다.
아쉬운 점은 모델을 직접 수정하기가 어렵고 하둡 없이는 대용량 데이터 처리가 안 된다는 점이 있다.
만약 공공데이터에서 받을 수 있는 정도의 데이터셋을 머신러닝을 해보고 싶은데 파이썬이나 R을 할 줄 모른다면 아주 좋은 선택이라고 생각한다.
ref.
wikipedia / c4.5 algorithm
- https://en.wikipedia.org/wiki/C4.5_algorithm
leyla zhuhadar / Lecture 4-1:Analyzing IRIS Data set with Weka(cc)
- https://www.youtube.com/watch?v=aF7FEjplYPg
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.