
- 전체
- JAVA 일반
- JAVA 수학
- JAVA 그래픽
- JAVA 자료구조
- JAVA 인공지능
- JAVA 인터넷
- Java Framework
- Java GUI (AWT,SWING,SWT,JFACE)
- SWT and RCP (web RAP/RWT)[eclipse], EMF
Java Framework Spring Batch Example 3 - 청크 지향 프로세싱
2020.10.24 15:39
Spring Batch Example 3 - 청크 지향 프로세싱
청크 지향 프로세싱
Spring batch 처리 방법
스프링 배치는 크게 2가지 배치 처리 방법이 있습니다. Tasklet 방식과 청크 제향 프로세싱 방법입니다. 이전 글에서 예제로 만들었던 job 방식이 Tasklet 방입니다. 실무에서 tasklet 방식 같은 경우 일반적으로 통계를 구하는 작업에서 많이 쓰이는 방법입니다.
이번 글에서 알아볼 방식은 청크 제향 프로세싱 방법입니다. 반대로 청크 제향 프로세싱 방법은 일괄 데이터 변경이나 어떤 데이터 변화를 주는 작업에서 청크 제향 프로세싱 방법을 사용할 수 있습니다.
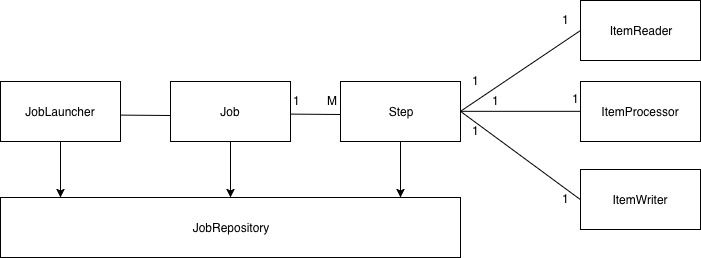
위 설계도는 Srping-batch1 글에서 봤던 Spring batch 구조대입니다. 일반적으로 Spring batch는 위와 같은 구조를 가지게 됩니다. 위에서 Step을 tasklet 방법으로 구성하느냐, ItemReader, ItemProcessor, ItemWriter의 단위로 구성하느냐에 따라 tasklet 방식이 될 수 있고, 청크 제향 프로세싱 방법이 될 수 있습니다.
청크 지향을 프로세싱을 알아보기전에 간단하게 ItemReader, ItemProcessor, ItemWriter개념을 다시한번 봐보겠습니다.
ItemReader
ItemReader는 Step의 대상이 되는 배치 데이터를 읽어오는 인터페이스입니다. FILE, XML, DB등 여러타입의 데이터를 읽어올 수 있습니다.
public interface ItemReader<T> {
T read() throws Exception;
}
ItemReader에서 read() 메서드의 반환타입을 제네릭으로 구현했기 때문에 직접 타입을 지정 할 수 있습니다.
ItemProcessor
ItemProcessor는 ItemReader로 읽어온 배치 데이터를 변환하는 역할을 수행합니다. 다음은 ItemProcessor인터페이스 코드입니다다. 제니릭을 사용해 인풋, 아웃풋 타입을 정의하고 비지니스 로직을 구현할 수 있습니다.
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}
ItemWriter
ItemWriter도 ItemReader 와 비슷한 방식으로 구현하면 됩니다. 제네릭으로 원하는 타입을 받습니다. write() 메서드는 List 자료구조를 사용해 지정한 타입의 리스트를 매개변수로 받습니다. 리스트의 데이터 수는 설정한 청크 단위로 불러옵니다. write() 메서 더의 반환값은 따로 없고 매개변수로 받은 데이터를 저장하는 로직을 구현하면 됩니다.
public interface ItemWriter<T> {
void write(List<? extends T> items) throws Exception;
}
청크 지향 프로세싱
청크 지향 프로세싱은 트랜잭션 경계 내에서 청크 단위로 데이터를 읽고 생성하는 기법입니다. 청크란 아이템이 트랜잭션에서 커밋되는 수를 말합니다. 읽어온 데이터를 지정된 청크수에 맞게 트랜잭션 커밋을 진행합니다.
예를 들어 1천 개의 데이터를 업데이트해야 한다고 해보겠습니다. 이럴 경우 위에서 말한 tasklet 방식이나 청크로 데이터를 지정하지 않은 경우 천 개의 데이터에 변경을 한 번에 해야 합니다. 이렇게 되면 천 개의 데이터 중 한 개의 데이터라도 업데이트를 실패하여 Exception 발생할 경우 천 개의 데이터를 롤백 해야 합니다. 또한 트랜잭션 시간을 길게 가져감으로써 데이터베이스로부터 읽어온 데이터들이 lock이 걸리게 됩니다. 이러한 문제를 해결하기 위해서는 청크 지향 프로세싱을 이용해야 합니다. 청크를 지정하게 되면 한 건에 실패에 대한 청크부터 뒤에까지만 영향을 받게 됩니다. 실패한 청크 앞에 영역은 영향을 받지 않습니다. 또한 청크만큼만 트랜잭션 시간을 가져가기 때문에 트랜잭션 시간을 짧게 가져갈 수 있습니다.
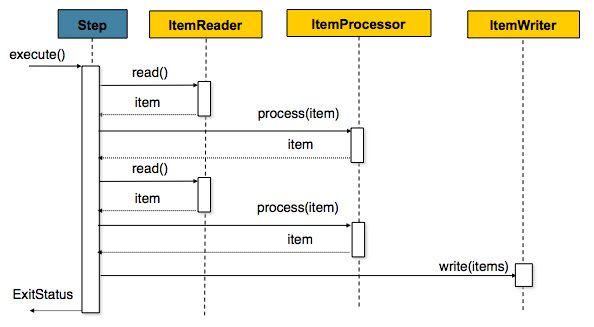
위에 도식 표는 처크 지향 프로세싱이 flow를 나태는 그림입니다. 다음 코드는 청크 제향 프로세싱 flow를 콘셉을 나타내는 자바 소스코드입니다. 아래에서 조금 더 세밀하게 청크 제향 flow를 파악해보겠습니다.
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read() //reader에서 데이터 읽어오기
Object processedItem = itemProcessor.process(item); //process로 비지니스로직처리
items.add(processedItem); //list에 target 데이터 사빕
}
itemWriter.write(items); // 청크만큼 데이터 저장
ChunkOrientedTasklet
위에 청크지향 콘셉을 실제로 담당하는 클래스는 ChunkOrientedTasklet 클래스입니다. ChunkOrientedTasklet 클래스가 ItemReader로부터 데이터를 읽어와 ItemProcessor로 데이터를 가공하고 ItemWriter로 데이터를 저장하는 일을 총괄하는 class입니다.


ChunkOrientedTasklet
청크 단위로 처리하는 작업을 아래에 execute메소드가가 처리를 하게 됩니다.
- chunkProvider.provide() 빈으로 등록된 ItemReader에서 Chunk size만큼 데이터를 가져옵니다.
- chunkProcessor.process() 에서 ItemReader로 받은 데이터를 빈으로 등록된 ItemProcess와 ItemWriter를 통해 데이터를 가공하고 저장하는 처리 해줍니다.
public class ChunkOrientedTasklet<I> implements Tasklet {
...
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
@SuppressWarnings("unchecked")
Chunk<I> inputs = (Chunk<I>) chunkContext.getAttribute(INPUTS_KEY);
if (inputs == null) {
//chunkProvider의 구현체인 SimpleChunkProvider가 존재한다. 이것을 deafult로 사용한다.
inputs = chunkProvider.provide(contribution); //1. 데이터를 읽어온다.
if (buffering) {
chunkContext.setAttribute(INPUTS_KEY, inputs);
}
}
chunkProcessor.process(contribution, inputs); //2. 실제 데이터를 가공 처리하고 저장한다.
chunkProvider.postProcess(contribution, inputs);
if (inputs.isBusy()) {
logger.debug("Inputs still busy");
return RepeatStatus.CONTINUABLE;
}
chunkContext.removeAttribute(INPUTS_KEY);
chunkContext.setComplete();
if (logger.isDebugEnabled()) {
logger.debug("Inputs not busy, ended: " + inputs.isEnd());
}
return RepeatStatus.continueIf(!inputs.isEnd());
}
}
아래는 chunkProvider.provide(), chunkProcessor.process() 에 세부 내용입니다.
SimpleChunkProvider
- SimpleChunkProvider에 provide메소드는 Chunk 만큼에 데이터를 읽어서 ChunkOrientedTasklet로 업데이트할 데이터를 리턴해주는 역할을 합니다.
- item = read(contribution, inputs); 는 빈으로 등록된 itemReader로 item을 읽어오는 역할을 합니다.
public class SimpleChunkProvider<I> implements ChunkProvider<I> {
@Override
public Chunk<I> provide(final StepContribution contribution) throws Exception {
final Chunk<I> inputs = new Chunk<I>();
repeatOperations.iterate(new RepeatCallback() { //chunk수만큼 데이터를 읽어 inputs에 넣어준다.
@Override
public RepeatStatus doInIteration(final RepeatContext context) throws Exception {
I item = null;
try {
item = read(contribution, inputs); //등록된 ItemReader로부터 item을 읽어온다.
}
catch (SkipOverflowException e) {
return RepeatStatus.FINISHED;
}
if (item == null) {
inputs.setEnd();
return RepeatStatus.FINISHED;
}
inputs.add(item); //실제 inputs에 itemreader로부터 읽어온 데이터를 추가해주는 부분이다.
contribution.incrementReadCount();
return RepeatStatus.CONTINUABLE;
}
});
return inputs;
}
protected I read(StepContribution contribution, Chunk<I> chunk) throws SkipOverflowException, Exception {
return doRead();
}
@Nullable
protected final I doRead() throws Exception {
try {
listener.beforeRead();
I item = itemReader.read(); //실제 itemReader로 빈을등록한 itemreder 호출(만약 페이징 처리되어있으면 페이징 처리대상을 부름)
if(item != null) {
listener.afterRead(item);
}
return item;
}
catch (Exception e) {
if (logger.isDebugEnabled()) {
logger.debug(e.getMessage() + " : " + e.getClass().getName());
}
listener.onReadError(e);
throw e;
}
}
...
}
SimpleChunkProcessor
- protected void write(StepContribution contribution, Chunk inputs, Chunk
outputs) 는 실제로 빈으로 등록된 ItemWriter로 데이터를 데이터베이스에 저장하는역할을 합니다.
public class SimpleChunkProcessor<I, O> implements ChunkProcessor<I>, InitializingBean {
@Override
public final void process(StepContribution contribution, Chunk<I> inputs) throws Exception {
initializeUserData(inputs);
if (isComplete(inputs)) {
return;
}
Chunk<O> outputs = transform(contribution, inputs); //ItemReader로부터 읽어온 데이터들을 빈으로 등록된 ItemProcessor로가공하여 ouputs에 저장한다.
contribution.incrementFilterCount(getFilterCount(inputs, outputs));
write(contribution, inputs, getAdjustedOutputs(inputs, outputs)); // 실제 가공한 데이터를 빈으로 등록되어진 ItemWriter를 통해 저장한다.
}
protected Chunk<O> transform(StepContribution contribution, Chunk<I> inputs) throws Exception {
Chunk<O> outputs = new Chunk<O>();
for (Chunk<I>.ChunkIterator iterator = inputs.iterator(); iterator.hasNext();) {
final I item = iterator.next();
O output;
try {
output = doProcess(item);
}
catch (Exception e) {
inputs.clear();
throw e;
}
if (output != null) {
outputs.add(output);
}
else {
iterator.remove();
}
}
return outputs;
}
protected final O doProcess(I item) throws Exception {
if (itemProcessor == null) {
@SuppressWarnings("unchecked")
O result = (O) item;
return result;
}
try {
listener.beforeProcess(item);
O result = itemProcessor.process(item);
listener.afterProcess(item, result);
return result;
}
catch (Exception e) {
listener.onProcessError(item, e);
throw e;
}
}
protected void write(StepContribution contribution, Chunk<I> inputs, Chunk<O> outputs) throws Exception {
try {
doWrite(outputs.getItems());
}
catch (Exception e) {
inputs.clear();
throw e;
}
contribution.incrementWriteCount(outputs.size());
}
protected final void doWrite(List<O> items) throws Exception {
if (itemWriter == null) {
return;
}
try {
listener.beforeWrite(items);
writeItems(items);
doAfterWrite(items);
}
catch (Exception e) {
doOnWriteError(e, items);
throw e;
}
}
...
}
심사 상태에 따른 유저 상태 변경 배치 처리
실제 예제를 한번만들어 보겠습니다. 아래 예제는 다음과 같은 요구 조건으로 시나리오로 만들어진 배치잡입니다.
- 유저가 처음 생성되면 유저의 상태는 WAITING 즉 싱사대기중인 상태이다.
- 유저가 가입한지 하루가 지났다면 COMPLETED 심사 완료 배치처리를 해야한다.
그럼 위의 요구조건을 만족하기위해 어떠한 설정들이 필요할지 나열해보겠습니다.
- 유저 심사 완료처리 Job
- 유저 심사 완료처리 Step
- 유저 심사 완료처리 Reader, Processor, Writer
@Slf4j
@Configuration
@RequiredArgsConstructor
public class JobConfiguration {
private final MemberRepository memberRepository;
private final int CHUNK_SIZE = 10;
@Bean
public Job completeUserJob(JobBuilderFactory jobBuilderFactory, Step completeJobStep) {
return jobBuilderFactory.get("completeUserJob")
.incrementer(new RunIdIncrementer())
.start(completeJobStep)
.build();
}
@Bean
public Step completeJobStep(StepBuilderFactory stepBuilderFactory) {
return stepBuilderFactory.get("completeUserStep")
.allowStartIfComplete(true)
.<Member, Member> chunk(CHUNK_SIZE)
.reader(completeMemberReader())
.processor(completeUserProcessor())
.writer(completeUserWriter())
.build();
}
@Bean
@StepScope
public QueueItemReader<Member> completeMemberReader() {
List<Member> oldMembers =
memberRepository.findByCreatedAtBeforeAndProcessStatusEquals(
LocalDateTime.now().minusDays(1), ProcessStatus.WAITING);
return new QueueItemReader<>(oldMembers); // 전체를 다읽어옴
}
public ItemProcessor<Member, Member> completeUserProcessor() {
return new ItemProcessor<Member, Member>() {
@Override
public Member process(Member member) {
return member.setCompleted();
}
};
}
public ItemWriter<Member> completeUserWriter() {
return new ItemWriter<Member>() {
@Override
public void write(List<? extends Member> users) {
// 위에 청크가 있어서 10개씩 커밋함.
memberRepository.saveAll(users);
}
};
}
}
원래 기존 예제에서는 JobParmeter가 변경되어야 Job을 실행할 수 있다고 했는데 위에 예제에서는 JobParameter가 구분될 필요가 없어 같은 Jobparameter 나 같은 Job을 실행하도록 incrementer, allowStartIfComplete를 설정했습니다.
실제 예제가 돌아가려는 모습을 보시려면 ExampleApplicationTests.java 코드를 실행하시면 됩니다. 따로 테스트 코드는 작성되어 있지 않지만 아래 코드를 실행하면 예제가 돌아가는 것을 확인하실 수 있습니다.
@Test
public void contextLoads() {
}
하지만 위에 문제가 있습니다. 문제는 유저를 불러오는 부분입니다. 저렇게 유저를 불러오게 되면 데이터베이스 모든 유저를 불러오게 됩니다. 그렇게 되면 업데이트해야 할 유저에 대상이 수십, 수백만 건에 데이터가 된다면 그 많은 데이터를 메모리에 올리다가 시스템이 뻗을 수가 있습니다. 그렇기 때문에 이러한 문제를 해결하기 위해서는 데이터를 읽어올 때 페이징 처리를 해야 합니다. 다음 장에서는 어떤 식으로 페이징 처리를 할 수 있는지 알아보도록 하겠습니다.
[출처] https://wan-blog.tistory.com/55?category=776769
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.