
Hive & Pig - 하둡(Hadoop)의 맵리듀스를 보다 편하게~
2016.04.16 21:13
Hive & Pig - 하둡(Hadoop)의 맵리듀스를 보다 편하게~
하둡(Hadoop) 프로젝트를 진행할 때 사람들의 고민이 무엇일까? 하고 생각해 봤습니다.
Java 언어에 익숙하더라도 첫번째로 만나는 문제는 역시 맵리듀스(MapReduce)가 아닐까 합니다.
맵리듀스는 맵과 리듀스가 합쳐진 것으로 각각의 Map 함수와 Reduce 함수를 구현하고 JobClient를 통해 호출해야 합니다.
그런데 일반적으로 하둡 프로젝트에서 한번만 맵리듀스를 사용하는 경우는 거의 없습니다.
대부분 맵 리듀스를 반복적으로 사용하게 됩니다.
여기에 맵리듀스에서 기본적으로 사용하는 타입인 Text, IntWritable, LongWritable과 같은 것 이외에 객체를 사용한다든지.
Key 항목이 아닌 Value에 속하는 항목으로 정렬을 하고 싶다든지,
하는 경우에 많은 개발자들이 어려움을 느끼고 있습니다.
물론 위와 같은 문제들에 대한 해결책은 맵리듀스에 존재합니다.
그러나 마치 어셈블리어로 모두다 가능하지만 고급언어로 씌워서 개발자가 좀 더 편하게 개발할 수 있는 환경을 만드는 것처럼
하둡에서도 맵리듀스로 변환해 줄 수 있는 스크립트 언어들이 존재합니다.
제가 굳이 고급 언어라고 하지 않고 스크립트 언어라고 하는 이유는
개인적으로는 아직까지 맵리듀스가 더 나을 수 있다고 보기 때문입니다.
물론 시간이 흘러 스크립트 언어들의 성능 개선이 이루어지겠지만 맵리듀스로 변환해야 하는 오버헤드는 존재하겠죠..
Google Sawzall
이런 스크립트 언어를 맨 처음 만든 것은 역시 Google 이었습니다.
구글은 GFS와 맵리듀스에서 사용할 수 있는 절차형 프로그래밍 언어를 개발했고 Sawzall 이라는 이름으로 사용하고 있다고 합니다.
이런 Sawzall을 모델로 Hadoop과 관련한 프로젝트들이 만들어집니다.
바로 Hive와 Pig 입니다.

Hive
먼저 Hive부터 살펴보도록 하죠.
Hive는 HiveQL이라고 하는 SQL과 유사한 쿼리를 사용합니다.
HiveQL로 정의한 내용을 Hive가 MapReduce Job으로 변환해서 실행한다고 합니다.
정확하게 설명하면, MapReduce 작업이 필요할 때 Hive는 Java MapReduce 프로그램을 생성하는 것은 아니라고 합니다.
인터프리터 언어처럼 내장된 Generic Mapper와 Reducer 모듈을 사용하고,
여기에 Job Plan이라는 XML 파일을 적용해 MapReduce Job을 생성한다고 하네요.
이렇게 MapReduce Job을 생성하면서 비로소 Job Tracker와 통신하기 시작한다고 합니다.
Facebook 주도로 개발했고 국내에서도 Hive를 위주로 사용하는 곳도 있습니다.
예를 한번 살펴보도록 하죠.
Q) K1 메타 저장소에서 Key 값이 100보다 큰 것을 Key와 count로 출력
hive> select key, count(1) from kv1 where key > 100 group by key
위와 같은 형태로 구현이 가능하다고 합니다.
실제 SQL 쿼리를 사용하는 것과 같은 느낌이 듭니다.
이번에는 Hadoop의 기본 예제로 사용하는 WordCount를 Hive로 구성해 보도록 하겠습니다.
WordCount에 대한 MapReduce 설명은 http://blog.acronym.co.kr/333#wordcount 을 참고하시기 바랍니다.
CREATE TABLE docs (line STRING);
LOAD DATA INPATH 'docs' OVERWRITE INTO TABLE docs;CREATE TABLE word_counts ASSELECT word, count(1) AS countFROM (SELECT explode(split(line,'\s')) AS word FROM docs) wGROUP BY wordORDER BY word;
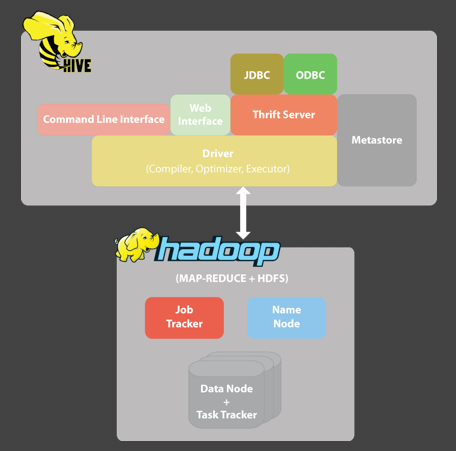


구성도를 살펴보면 Hive에 Metastore가 존재합니다.
이 부분에 DB 스키마와 같이 저장하는 것 같고 실제 데이터는 하둡의 HDFS에 분산되어 저장되는 구조인 듯 합니다.
Metastore는 별도의 Relation Database로서 일반적으로 MySQL 인스턴스를 사용한다고 합니다.
즉, Hive는 주로 MySQL을 사용하여 테이블 스키마와 시스템 메타데이터를 유지하고 있다고 보면 됩니다.
JDBC, ODBC 드라이버가 존재하는 것으로 봐서 기존 DB와도 연동해서 사용할 수 있는 것 같네요.
뿐만 아니라, CLI (Command Line Interface), HWI (Hive Web Interface), 그리고 Thrift 서버 프로그래밍을 제공합니다.
최근에는 다양한 GUI 툴도 제공하고 있는데요.
Karmasphere(http://karmasphere.com), Cloudera의 Hue (https://github.com/cloudera/hue),
그리고 Hive-as-a-service를 제공하는 Qubole(http://qubole.com)를 Hive GUI로 활용할 수 있습니다.
Pig
Pig와 관련해서는 http://blog.acronym.co.kr/372 에서 간단하게 정리하기는 했는데요.
MapReduce의 비직관적이고 반복되는 코딩을 줄이기 위해 간결한 문법으로 새로 만든 스크립트 언어입니다.
정확하게 설명하면, Pig는 Query Language가 아닌 Data Flow를 처리하는 Laguage라 할 수 있습니다.
사용자 정의 함수로 확장이 가능하지만 컴파일 과정이 필요하므로 MapReduce에 비해 성능이 떨어진다고 하네요.
야후(Yahoo)에서는 하둡 작업의 30%를 Pig를 사용하고 있고, 트위터도 사용한다고 들었던 것 같습니다.
또한 Pig는 외부 데이터를 하둡 클러스터로 가져오고 적절한 형식으로 변환하기 위한 ETL(Extract, Transform, and Load) 프로세스의 일부로도 종종 사용된다고 합니다.
Pig에 대한 예제를 Hadoop 완벽 가이드에 나오는 내용을 기반으로 살펴보죠.
Q) 날씨 데이터에서 연중 가장 높은 기온을 계산하는 프로그램
1: grunt> records = LOAD ‘input/sample.txt’
2: >> AS(year: chararray, temperature:int, quality:int);
3: grunt> filtered_records = FILTER records BY temperature != 9999
4: >> AND quality == 1
5:
6: grunt> grouped_records = Group filtered_records BY year;
7: grunt> max_temp = FOREACH grouped_records GENERATE group,
8: >> MAX(filtered_records.temperature);
9:
10: grunt> DUMP max_temp;
11: (1949, 111)
12: (1950, 22)
1~2번째 줄을 보면 HDFS에서 input/ 폴더의 sample.txt를 가져와서 year, temperature, quality를 중심으로 분류합니다.
그리고 3~4번째 줄에 temperature와 quality가 적절한 값들만 필터링해서 filtered_records에 저장합니다.
6번째 줄에서 연도별을 기준으로 그룹화해서 grouped_records에 저장합니다.
그리고 7~8번째 줄에서 각 그룹별로 최고 기온을 체크해서 max_temp에 저장하고
마지막에 max_temp를 출력하면 결과가 위와 같이 나옵니다.
실제 관련 책을 보면 위 내용을 맵리듀스로 작성하는 내용이 나옵니다.
비교해보면 정말 간단하기는 합니다.
In Pig, you write a series of declarative statements that define relations from other relations,
where each new relation performs some new data transformation.
Pig looks at these declarations and then builds up a sequence of MapReduce jobs
to perform the transformations until the final results are computed the way that you want.
마치면서
이상으로 Hive와 Pig에 대해서 간략하게 정리해 봤습니다.
분명 Hive나 Pig는 발전하고 있고 프로그래밍하기에 보다 편리한 것이 사실입니다.
하지만 개인적으로는 반드시 하둡을 사용하려면 MapReduce로 한번쯤 직접 해 보시기를 권장하고 싶습니다.
MapReduce의 처리 흐름을 이해하고 난 뒤 Hive나 Pig를 사용해도 늦지 않을 것이라는 생각이거든요.
어차피 내부적으로 MapReduce로 변환해 실행한다면 MapReduce를 이해하고 있어야 나중에 응용도 보다 자유롭게 하지 않을까 합니다.
-- 2012년 11월 2일 작성한 글을 최신 내용으로 업데이트 했습니다.
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.