
Why a microservices approach to building applications?
2017.05.20 23:41
Why a microservices approach to building applications?





As software developers, there is nothing new in how we think about factoring an application into component parts. It is the central paradigm of object orientation, software abstractions, and componentization. Today, this factorization tends to take the form of classes and interfaces between shared libraries and technology layers. Typically, a tiered approach is taken with a back-end store, middle-tier business logic, and a front-end user interface (UI). What has changed over the last few years is that we, as developers, are building distributed applications that are for the cloud and driven by the business.
The changing business needs are:
- A service that's built and operates at scale to reach customers in new geographical regions (for example).
- Faster delivery of features and capabilities to be able to respond to customer demands in an agile way.
- Improved resource utilization to reduce costs.
These business needs are affecting how we build applications.
For more information about the approach of Azure to microservices, read .
Monolithic vs. microservice design approach
All applications evolve over time. Successful applications evolve by being useful to people. Unsuccessful applications do not evolve and eventually are deprecated. The question becomes: How much do you know about your requirements today, and what will they be in the future? For example, let's say that you are building a reporting application for a department. You are sure that the application will remain within the scope of your company and that the reports will be short-lived. Your choice of approach is different from, say, building a service that delivers video content to tens of millions of customers.
Sometimes, getting something out the door as proof of concept is the driving factor, while you know that the application can be redesigned later. There is little point in over-engineering something that never gets used. It’s the usual engineering trade-off. On the other hand, when companies talk about building for the cloud, the expectation is growth and usage. The issue is that growth and scale are unpredictable. We would like to be able to prototype quickly while also knowing that we are on a path to deal with future success. This is the lean startup approach: build, measure, learn, and iterate.1
During the client-server era, we tended to focus on building tiered applications by using specific technologies in each tier. The term monolithic application has emerged for these approaches. The interfaces tended to be between the tiers, and a more tightly coupled design was used between components within each tier. Developers designed and factored classes that were compiled into libraries and linked together into a few executables and DLLs.1
There are benefits to such a monolithic design approach. It's often simpler to design, and it has faster calls between components, because these calls are often over interprocess communication (IPC). Also, everyone tests a single product, which tends to be more people-resource efficient. The downside is that there's a tight coupling between tiered layers, and you cannot scale individual components. If you need to perform fixes or upgrades, you have to wait for others to finish their testing. It is more difficult to be agile.
Microservices address these downsides and more closely align with the preceding business requirements, but they also have both benefits and liabilities. The benefits of microservices are that each one typically encapsulates simpler business functionality, which you scale up or down, test, deploy, and manage independently. One important benefit of a microservice approach is that teams are driven more by business scenarios than by technology, which the tiered approach encourages. In practice, smaller teams develop a microservice based on a customer scenario and use any technologies they choose.
In other words, the organization doesn’t need to standardize tech to maintain monolithic applications. Individual teams that own services can do what makes sense for them based on team expertise or what’s most appropriate to solve the problem. In practice, a set of recommended technologies, such as a particular NoSQL store or web application framework, is preferable.2
The downside of microservices comes in managing the increased number of separate entities and dealing with more complex deployments and versioning. Network traffic between the microservices increases as well as the corresponding network latencies. Lots of chatty, granular services are a recipe for a performance nightmare. Without tools to help view these dependencies, it is hard to “see” the whole system.
Standards make the microservice approach work by agreeing on how to communicate and being tolerant of only the things you need from a service, rather than rigid contracts. It is important to define these contracts up front in the design, because services update independently of each other. Another description coined for designing with a microservices approach is “fine-grained service-oriented architecture (SOA).”
At its simplest, the microservices design approach is about a decoupled federation of services, with independent changes to each, and agreed-upon standards for communication.
As more cloud apps are produced, people discover that this decomposition of the overall app into independent, scenario-focused services is a better long-term approach.
Comparison between application development approaches
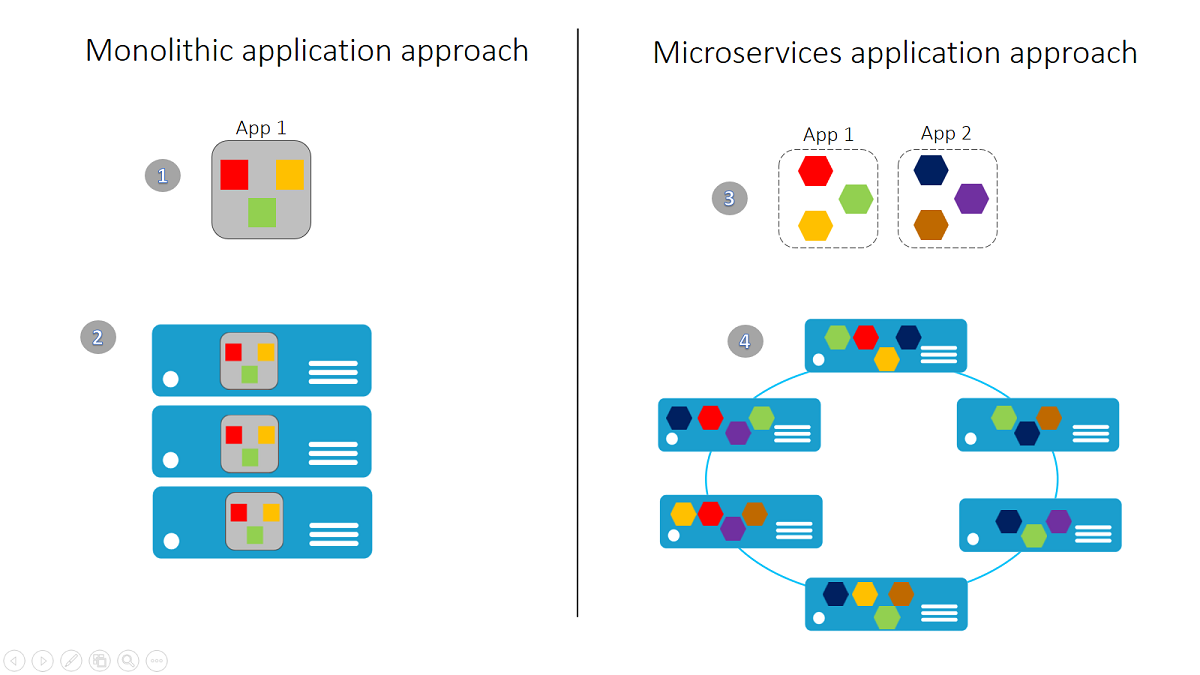
- A monolithic app contains domain-specific functionality and is normally divided by functional layers, such as web, business, and data.
- You scale a monolithic app by cloning it on multiple servers/virtual machines/containers.
- A microservice application separates functionality into separate smaller services.
- The microservices approach scales out by deploying each service independently, creating instances of these services across servers/virtual machines/containers.
Designing with a microservice approach is not a panacea for all projects, but it does align more closely with the business objectives described earlier. Starting with a monolithic approach might be acceptable if you know that you will not have the opportunity to rework the code later into a microservice design if necessary. More commonly, you begin with a monolithic app and slowly break it up in stages, starting with the functional areas that need to be more scalable or agile.
To summarize, the microservice approach is to compose your application of many small services. The services run in containers that are deployed across a cluster of machines. Smaller teams develop a service that focuses on a scenario and independently test, version, deploy, and scale each service so that the entire application can evolve.
What is a microservice?
There are different definitions of microservices. If you search the Internet, you'll find many useful resources that provide their own viewpoints and definitions. However, most of the following characteristics of microservices are widely agreed upon:
- Encapsulate a customer or business scenario. What is the problem you are solving?
- Developed by a small engineering team.
- Written in any programming language and use any framework.
- Consist of code and (optionally) state, both of which are independently versioned, deployed, and scaled.
- Interact with other microservices over well-defined interfaces and protocols.
- Have unique names (URLs) used to resolve their location.
- Remain consistent and available in the presence of failures.
You can summarize these characteristics into:
Microservice applications are composed of small, independently versioned, and scalable customer-focused services that communicate with each other over standard protocols with well-defined interfaces.
We covered the first two points in the preceding section, and now we expand on and clarify the others.
Written in any programming language and use any framework
As developers, we should be free to choose a language or framework that we want, depending on our skills or the needs of the service. In some services, you might value the performance benefits of C++ above all else. In other services, the ease of managed development in C# or Java might be most important. In some cases, you may need to use a specific partner library, data storage technology, or means of exposing the service to clients.
After you have chosen a technology, you come to the operational or lifecycle management and scaling of the service.


Allows code and state to be independently versioned, deployed, and scaled
However you choose to write your microservices, the code and optionally the state should independently deploy, upgrade, and scale. This is actually one of the harder problems to solve, because it comes down to your choice of technologies. For scaling, understanding how to partition (or shard) both the code and state is challenging. When the code and state use separate technologies, which is common today, the deployment scripts for your microservice need to be able to cope with scaling them both. This is also about agility and flexibility, so you can upgrade some of the microservices without having to upgrade all of them at once.
Returning to the monolithic versus microservice approach for a moment, the following diagram shows the differences in the approach to storing state.
State storage between application styles
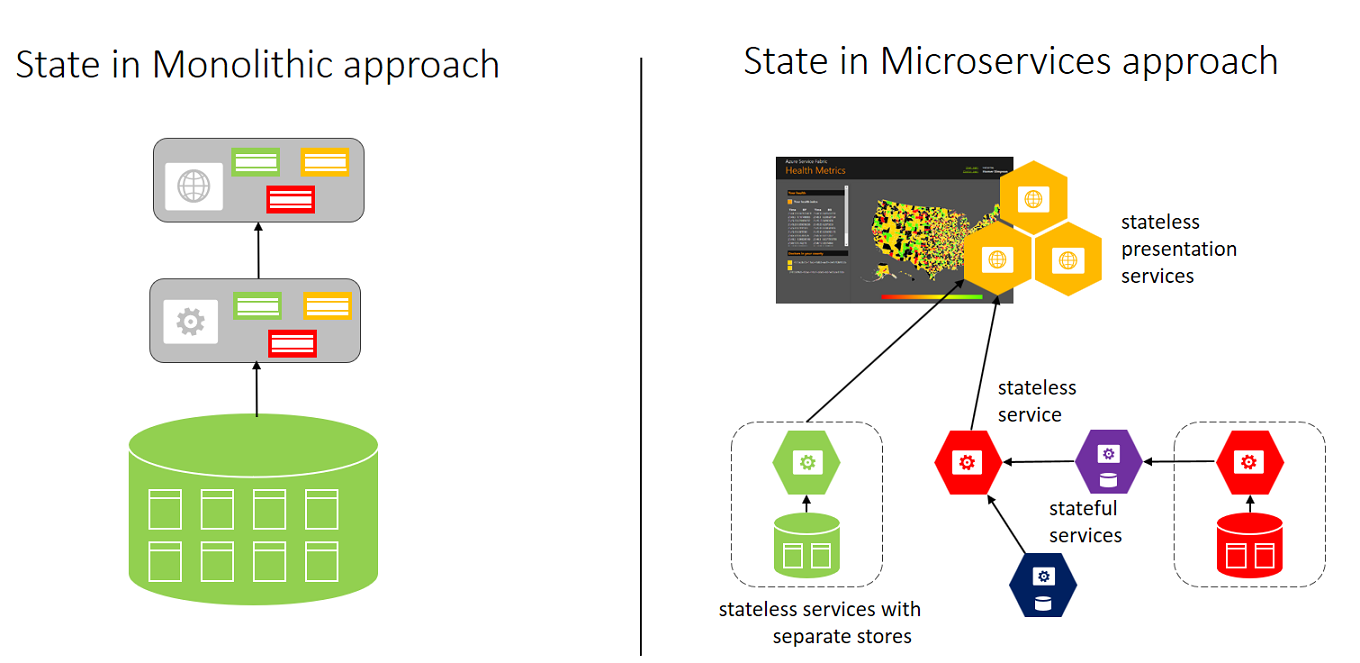
The monolithic approach on the left has a single database and tiers of specific technologies.
The microservices approach on the right has a graph of interconnected microservices where state is typically scoped to the microservice and various technologies are used.
In a monolithic approach, typically the application uses a single database. The advantage is that it is a single location, which makes it easy to deploy. Each component can have a single table to store its state. Teams need to strictly separate state, which is a challenge. Inevitably there are temptations to add a new column to an existing customer table, do a join between tables, and create dependencies at the storage layer. After this happens, you can't scale individual components.
In the microservices approach, each service manages and stores its own state. Each service is responsible for scaling both code and state together to meet the demands of the service. A downside is that when there is a need to create views, or queries, of your application’s data, you will need to query across disparate state stores. Typically, this is solved by having a separate microservice that builds a view across a collection of microservices. If you need to perform multiple impromptu queries on the data, each microservice should consider writing its data to a data warehousing service for offline analytics.
Versioning is specific to the deployed version of a microservice so that multiple, different versions deploy and run side by side. Versioning addresses the scenarios where a newer version of a microservice fails during upgrade and needs to roll back to an earlier version. The other scenario for versioning is performing A/B-style testing, where different users experience different versions of the service. For example, it is common to upgrade a microservice for a specific set of customers to test new functionality before rolling it out more widely. After lifecycle management of microservices, this now brings us to communication between them.
Interacts with other microservices over well-defined interfaces and protocols
This topic needs little attention here, because extensive literature about service-oriented architecture that has been published over the past 10 years describes communication patterns. Generally, service communication uses a REST approach with HTTP and TCP protocols and XML or JSON as the serialization format. From an interface perspective, it is about embracing the web design approach. But nothing stops you from using binary protocols or your own data formats. Be prepared for people to have a harder time using your microservices if these are openly available.
Has a unique name (URL) used to resolve its location
Remember how we keep saying that the microservice approach is like the web? Like the web, your microservice needs to be addressable wherever it is running. If you are thinking about machines and which one is running a particular microservice, things will go bad quickly.
In the same way that DNS resolves a particular URL to a particular machine, your microservice needs to have a unique name so that its current location is discoverable. Microservices need addressable names that make them independent from the infrastructure that they are running on. This implies that there is an interaction between how your service is deployed and how it is discovered, because there needs to be a service registry. Equally, when a machine fails, the registry service must tell you where the service is now running.
This brings us to the next topic: resilience and consistency.
Remains consistent and available in the presence of failures
Dealing with unexpected failures is one of the hardest problems to solve, especially in a distributed system. Much of the code that we write as developers is handling exceptions, and this is also where the most time is spent in testing. The problem is more involved than writing code to handle failures. What happens when the machine where the microservice is running fails? Not only do you need to detect this microservice failure (a hard problem on its own), but you also need something to restart your microservice.
A microservice needs to be resilient to failures and restart often on another machine for availability reasons. This also comes down to the state that was saved on behalf of the microservice, where the microservice can recover this state from, and whether the microservice is able to restart successfully. In other words, there needs to be resilience in the compute (the process restarts) as well as resilience in the state or data (no data loss and the data remains consistent).
The problems of resiliency are compounded during other scenarios, such as when failures happen during an application upgrade. The microservice, working with the deployment system, doesn't need to recover. It also needs to then decide whether it can continue to move forward to the newer version or instead roll back to a previous version to maintain a consistent state. Questions such as whether enough machines are available to keep moving forward and how to recover previous versions of the microservice need to be considered. This requires the microservice to emit health information to be able to make these decisions.
Reports health and diagnostics
It may seem obvious, and it is often overlooked, but a microservice must report its health and diagnostics. Otherwise, there is little insight from an operations perspective. Correlating diagnostic events across a set of independent services and dealing with machine clock skews to make sense of the event order is challenging. In the same way that you interact with a microservice over agreed-upon protocols and data formats, there emerges a need for standardization in how to log health and diagnostic events that ultimately end up in an event store for querying and viewing. In a microservices approach, it is key that different teams agree on a single logging format. There needs to be a consistent approach to viewing diagnostic events in the application as a whole.
Health is different from diagnostics. Health is about the microservice reporting its current state to take appropriate actions. A good example is working with upgrade and deployment mechanisms to maintain availability. Although a service may be currently unhealthy due to a process crash or machine reboot, the service might still be operational. The last thing you need is to make this worse by performing an upgrade. The best approach is to do an investigation first or allow time for the microservice to recover. Health events from a microservice help us make informed decisions and, in effect, help create self-healing services.
Service Fabric as a microservices platform
Azure Service Fabric emerged from a transition by Microsoft from delivering box products, which were typically monolithic in style, to delivering services. The experience of building and operating large services, such as Azure SQL Database and Azure Cosmos DB, shaped Service Fabric. The platform evolved over time as more and more services adopted it. Importantly, Service Fabric had to run not only in Azure but also in standalone Windows Server deployments.
The aim of Service Fabric is to solve the hard problems of building and running a service and utilize infrastructure resources efficiently, so that teams can solve business problems using a microservices approach.
Service Fabric provides two broad areas to help you build applications that use a microservices approach:
- A platform that provides system services to deploy, upgrade, detect, and restart failed services, discover service location, manage state, and monitor health. These system services in effect enable many of the characteristics of microservices previously described.
- Programming APIs, or frameworks, to help you build applications as microservices: . Of course, you can choose any code to build your microservice. But these APIs make the job more straightforward, and they integrate with the platform at a deeper level. This way, for example, you can get health and diagnostics information, or you can take advantage of built-in high availability.
Service Fabric is agnostic on how you build your service, and you can use any technology.However, it does provide built-in programming APIs that make it easier to build microservices.
Are microservices right for my application?
Maybe. What we experienced was that as more and more teams in Microsoft began to build for the cloud for business reasons, many of them realized the benefits of taking a microservice-like approach. Bing, for example, has been developing microservices in search for years. For other teams, the microservices approach was new. Teams found that there were hard problems to solve outside of their core areas of strength. This is why Service Fabric gained traction as the technology of choice for building services.
The objective of Service Fabric is to reduce the complexities of building applications with a microservice approach, so that you do not have to go through as many costly redesigns. Start small, scale when needed, deprecate services, add new ones, and evolve with customer usage is the approach. We also know that there are many other problems yet to be solved to make microservices more approachable for most developers. Containers and the actor programming model are examples of small steps in that direction, and we are sure that more innovations will emerge to make this easier.
[출처] https://docs.microsoft.com/en-us/azure/service-fabric/service-fabric-overview-microservices
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.