
[Artificial Intelligence / MXNet] MXNet을 이용한 Classification 문제 풀기
2018.02.25 17:53
[Artificial Intelligence / MXNet]
MXNet을 이용한 Classification 문제 풀기
by Geol Choi | Jun.
이번 포스팅에서는 R에서 MXNet 딥러닝 프레임워크를 활용하여 간단한 Classification 문제를 풀어보도록 한다.
만약 R에서 MXNet 개발환경을 처음으로 구축하고자 한다면 여기를 참고하도록 한다.
MXNet 개발환경 설정이 모두 완료되면, MXNet 라이브러리를 로딩한다:
|
1
2
3
4
|
###########################################################
# load libraries
###########################################################
base::require(mxnet)
|
cs |
이제 데이터를 준비해야 하는데, R에 빌트인(Built-in) 데이터인 그 유명한 iris 데이터를 활용하도록 한다. iris 데이터는 대략 다음과 같은 피쳐(Features)들을 포함한다:
> utils::data("iris")
> utils::head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
"Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width", "Species" 등 모두 5개의 열(Column)로 구성된 피쳐들을 갖는데, 이 중 "Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width"를 입력(X)으로, "Species"를 출력(Y)으로 지정한다.
위에서 보이는 바와 같이, "Species"는 "setosa", "versicolor", "virginica" 등 3개의 범주를 갖는 Nominal Data이므로 이를 숫자형으로 변환해야 하는데, 변환에 앞서 iris 데이터 컨테이너를 "IrisData"라는 이름의 변수에 저장한 후, 변환하도록 한다:
|
1
2
3
4
5
6
7
|
###########################################################
# prepare data
###########################################################
utils::data("iris")
IrisData <- iris
utils::head(IrisData)
IrisData$Species <- base::as.numeric(IrisData$Species) - 1
|
cs |
정수로 변환한 후에는 "IrisData"의 "Species" 필드값인 "setosa", "versicolor", "virginica"는 다음과 같이 각각 1, 2, 3으로 변경되는데, 이 값에서 1을 뺀 것은 제로-인덱스로 변환하기 위함이다.
> IrisData$Species
[1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1
[61] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
[121] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
|
1
2
3
4
5
|
###########################################################
# define train & test dataset
###########################################################
set.seed(2)
train.ind <- base::sample(x=1:150, size=100, replace=FALSE)
|
cs |
IrisData의 1~4번째 열인 "Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width"를 입력(Input)으로 정의하므로, test dataset의 입력을 다음과 같이 IrisData의 train.ind에 저장된 인덱스의 행과 1:4번째 열을 선택하여 저장한다:
|
1
|
train.x <- base::data.matrix(IrisData[train.ind, 1:4])
|
cs |
Train dataset의 출력 train.y는 입력인 trains.x과 동일한 행을 선택하지만 열은 5번째에 해당된다:
|
1
|
train.y <- IrisData[train.ind, 5]
|
cs |
train.ind를 제외한 나머지 행으로 test dataset을 구성한다:
|
1
2
|
test.x <- base::data.matrix(IrisData[-train.ind, 1:4])
test.y <- IrisData[-train.ind, 5]
|
cs |
함수 mxnet::mx.mlp()를 이용하여 Mutli-Layer Perceptron(MLP) 모델을 학습시키되 랜덤 초기화를 한다:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
###########################################################
# model construction by Multi-Layer Perceptron
###########################################################
mxnet::mx.set.seed(0)
model <- mxnet::mx.mlp(data = train.x,
label = train.y,
hidden_node = 5,
out_node = 3,
out_activation = "softmax",
activation = "tanh",
num.round = 50,
device = mx.ctx.default(),
array.layout = "rowmajor",
array.batch.size = 5,
learning.rate = 0.01,
momentum = 0.9,
eval.metric = mx.metric.accuracy)
|
cs |
mxnet::mx.mlp()의 입력 파라미터를 모두 다 일일이 설명하는 것은 무리이며, R Studio 사용자라면 함수 이름을 검색하여 입력 파라미터에 대한 정보를 얻을 수 있으며 또는 R-MXNet 문서(아직 문서가 많이 미흡하다)를 참고하기 바란다. 다만, 몇 가지 중요 파라미터를 언급하자면(이름 자체만으로도 의미를 충분히 알 수 있으리라 생각된다),
-
out_node: 출력 노드의 개수. 본 Classification 문제에서는 출력값이 0, 1, 2로 모두 3개.
-
num.round: 반복 계산 횟수. 또는 Epoch 수.
-
device: CPU 또는 GPU.


이제 위의 코드를 실행시켜 모델을 학습시켜 보도록 한다:
Start training with 1 devices
[1] Train-accuracy=0.347368421052632
[2] Train-accuracy=0.35
[3] Train-accuracy=0.63
[4] Train-accuracy=0.67
[5] Train-accuracy=0.68
[6] Train-accuracy=0.71
[7] Train-accuracy=0.75
[8] Train-accuracy=0.86
[9] Train-accuracy=0.89
[10] Train-accuracy=0.88
[11] Train-accuracy=0.89
[12] Train-accuracy=0.92
[13] Train-accuracy=0.97
[14] Train-accuracy=0.97
[15] Train-accuracy=0.97
[16] Train-accuracy=0.97
[17] Train-accuracy=0.97
[18] Train-accuracy=0.97
[19] Train-accuracy=0.97
[20] Train-accuracy=0.97
[21] Train-accuracy=0.97
[22] Train-accuracy=0.97
[23] Train-accuracy=0.97
[24] Train-accuracy=0.97
[25] Train-accuracy=0.97
[26] Train-accuracy=0.97
[27] Train-accuracy=0.97
[28] Train-accuracy=0.97
[29] Train-accuracy=0.97
[30] Train-accuracy=0.97
[31] Train-accuracy=0.97
[32] Train-accuracy=0.97
[33] Train-accuracy=0.97
[34] Train-accuracy=0.97
[35] Train-accuracy=0.97
[36] Train-accuracy=0.98
[37] Train-accuracy=0.98
[38] Train-accuracy=0.98
[39] Train-accuracy=0.98
[40] Train-accuracy=0.98
[41] Train-accuracy=0.98
[42] Train-accuracy=0.98
[43] Train-accuracy=0.98
[44] Train-accuracy=0.98
[45] Train-accuracy=0.98
[46] Train-accuracy=0.98
[47] Train-accuracy=0.98
[48] Train-accuracy=0.98
[49] Train-accuracy=0.97
[50] Train-accuracy=0.97
97% 학습 정확도의 결과를 얻었다.
MXNet의 장점 중 하나는 TensorFlow의 TensorBoard와 유사하게 네트워크를 시각화해 주는 기능이 있다:
|
1
2
3
4
|
###########################################################
# visualze network
###########################################################
mxnet::graph.viz(model$symbol)
|
cs |
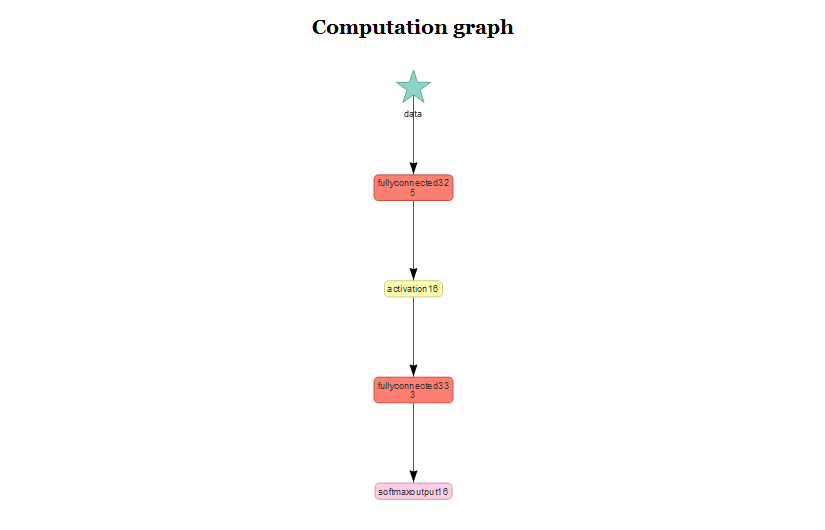
다만, 그래프가 썩 예뻐보이지는 않는 것 같다. 어쨌든 컨텍스트만 이해할 수 있으면 충분할 것 같다.
마지막으로 계산으로 얻은 모델을 평가해 보도록 한다:
|
1
2
3
4
|
###########################################################
# model validation with test dataset
###########################################################
preds <- stats::predict(model, test.x, array.layout = "rowmajor")
|
cs |
위의 코드에서 stats::predict() 함수를 통해 얻은 preds는 test dataset의 각 Score를 의미한다. 즉, 각각의 열은 각 테스트 데이터에 대한 0(setosa), 1(versicolor), 2(virginica)의 Score라고 생각하면 되겠다.
> preds
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
[1,] 9.935761e-01 9.933755e-01 9.935236e-01 9.911000e-01 9.927827e-01 9.950120e-01 9.916157e-01 9.922737e-01 9.945858e-01
[2,] 6.418932e-03 6.619421e-03 6.471368e-03 8.893428e-03 7.211749e-03 4.984017e-03 8.378012e-03 7.720454e-03 5.409957e-03
[3,] 4.975651e-06 5.120336e-06 4.997034e-06 6.643984e-06 5.504070e-06 3.906533e-06 6.277127e-06 5.845937e-06 4.232460e-06
[,10] [,11] [,12] [,13] [,14] [,15] [,16] [,17] [,18]
[1,] 9.936086e-01 0.9848120213 9.933048e-01 9.921175e-01 9.929829e-01 9.943505e-01 0.007417649 0.005416418 0.004244234
[2,] 6.386424e-03 0.0151775675 6.690053e-03 7.876604e-03 7.011825e-03 5.645154e-03 0.992250979 0.993507862 0.987540007
[3,] 4.935561e-06 0.0000104796 5.173965e-06 5.930814e-06 5.385812e-06 4.404085e-06 0.000331274 0.001075732 0.008215859
[,19] [,20] [,21] [,22] [,23] [,24] [,25] [,26] [,27]
[1,] 0.004785218 0.006385177 0.0082242331 0.0082849180 0.00214893 0.002671337 0.0087469993 0.004938253 0.0087838909
[2,] 0.992688835 0.991604149 0.9914662838 0.9913083911 0.87912756 0.941698074 0.9908814430 0.993299246 0.9907998443
[3,] 0.002525974 0.002010735 0.0003093819 0.0004067142 0.11872354 0.055630598 0.0003716509 0.001762437 0.0004162203
[,28] [,29] [,30] [,31] [,32] [,33] [,34] [,35] [,36]
[1,] 0.0063713072 0.005258560 0.005294404 0.0072387410 0.0067940969 7.251625e-05 9.680467e-05 2.162374e-05 6.602941e-05
[2,] 0.9927304387 0.991775155 0.992246509 0.9922373891 0.9923233986 6.566226e-02 8.319482e-02 2.342504e-02 6.057485e-02
[3,] 0.0008981919 0.002966302 0.002459001 0.0005238768 0.0008825203 9.342653e-01 9.167084e-01 9.765534e-01 9.393591e-01
[,37] [,38] [,39] [,40] [,41] [,42] [,43] [,44] [,45]
[1,] 0.001863288 0.0001342284 3.276289e-05 9.685445e-06 1.753258e-05 0.001171929 0.0002190276 2.950236e-05 2.314545e-05
[2,] 0.831283808 0.1092996225 3.239850e-02 1.175829e-02 1.957790e-02 0.621040285 0.1666817814 3.008866e-02 2.443355e-02
[3,] 0.166852891 0.8905661702 9.675688e-01 9.882321e-01 9.804046e-01 0.377787739 0.8330992460 9.698818e-01 9.755433e-01
[,46] [,47] [,48] [,49] [,50]
[1,] 0.002078916 0.002111664 0.0002431867 0.0006765017 0.0005830525
[2,] 0.878279388 0.870933473 0.1797741354 0.4148673117 0.3647069931
[3,] 0.119641662 0.126954898 0.8199826479 0.5844562650 0.6347098947
각 테스트 데이터에 대한 라벨(Label)은 각각 열(Column)에서 최대값을 갖는 행(Row)의 인덱스를 얻으면 된다:
|
1
|
pred.label <- base::max.col(base::t(preds)) - 1
|
cs |
그리고 base::table() 함수를 이용하여 pred.label와 test.y를 비교하는 테이블을 출력해 보면,
|
1
|
base::print(base::table(pred.label, test.y))
|
cs |
다음과 같은 출력 결과을 확인할 수 있다:
> base::print(base::table(pred.label, test.y))
test.y
pred.label 0 1 2
0 15 0 0
1 0 17 4
2 0 0 14
Dataset이 너무나도 훌륭해서 그런지 예측 데이터(pred.label)가 실제 테스테 데이터(test.y)를 단 하나도 잘못 판단한 것이 없다 (옵션을 적당히 조절하면 정확도를 임의로 낮출 수도 있다).
한편, 변수 model은 Weights와 Biases 정보를 가지고 있다:
> model
$symbol
C++ object <0000000013bd27d0> of class 'MXSymbol' <00000000137f2a30>
$arg.params
$arg.params$fullyconnected32_weight
[,1] [,2] [,3] [,4] [,5]
[1,] -0.5822342 0.1539952 -0.6584291 0.2161309 0.6591061
[2,] -0.9130311 0.4267913 -1.0125560 0.7703336 1.0504905
[3,] 1.0153695 -0.6274304 1.1278919 -1.2413483 -1.1523126
[4,] 1.0816779 -0.4050416 1.2042744 -0.5874040 -1.2058102
$arg.params$fullyconnected32_bias
[1] -0.5192163 0.1093897 -0.5846227 0.1274193 0.5859299
$arg.params$fullyconnected33_weight
[,1] [,2] [,3]
[1,] -0.8814825 -0.5732985 1.4416800
[2,] 1.0791504 -0.3596519 -0.7267237
[3,] -0.9087289 -0.6849672 1.5978891
[4,] 2.1900928 -1.6756068 -0.5267907
[5,] 1.0792551 0.6406125 -1.7158098
$arg.params$fullyconnected33_bias
[1] -0.1424098 0.7154709 -0.5730608
$aux.params
list()
attr(,"class")
[1] "MXFeedForwardModel"
네트워크의 각 Connection의 Weights와 Biases 값을 알고 있으므로, 직접 이 값들을 이용하여 Score 값을 계산해 볼 수도 있다.
아직 MXNet 사용법을 알아가는 중이라 설명이 많이 미흡하다. R-MXNet의 도큐먼트를 수시로 확인하는대로 추후에 설명을 좀 더 보강할 수 있도록 하겠다.
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.