
당근마켓에서 딥러닝 활용하기 - 불량 게시물 검사
2018.03.06 07:19
당근마켓에서 딥러닝 활용하기 - 불량 게시물 검사
[출처] http://aidev.co.kr/deeplearning/3000
당근마켓에서 딥러닝 활용하기
안녕하세요, 당근마켓 소프트웨어 엔지니어 Ed 입니다.
요새 인공지능/딥러닝이 정말 많이 거론되고 있는데요. 저희 당근마켓에서도 이러한 기술을 적극 활용하려 하고, 그동안 서비스에 적용한 내용을 공유하고자 합니다.
아직 당근마켓을 모르시는 분들을 위해 소개하면,
당근마켓은 우리 동네 주민들과 중고 직거래를 위한 스마트폰 앱 서비스예요. 주변 맘들은 이젠 익히 아실지도 :)
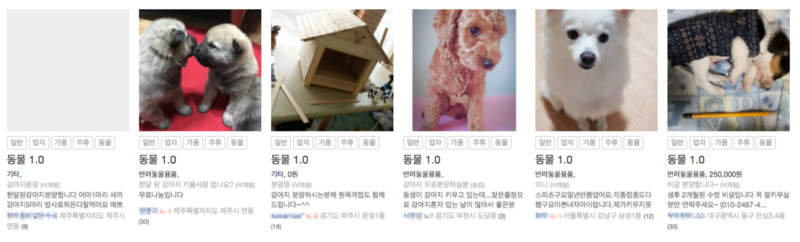
게시글 분류
당근마켓 사용자들로부터 게시글이 판매금지 품목에 해당한다면 신고 기능으로 제보받고 있습니다. 이렇게 제보받은 항목을 저희 당근마켓 팀은 검토하여 수락/거부 후 규정에 따라 처리하고 있습니다. 문제는 서비스가 성장하면서 저희 소규모 인원만으로는 감당할 수 없을 정도로 신고량이 늘어나게 되었습니다. 그렇다고 스타트업에서 운영인력을 선형적으로 채용하기 부담이 될 수 밖에 없었습니다.
그래서 딥러닝을 이용하여 해결하려 했습니다. 기존에 신고 처리한 내역을 학습 데이터로 사용하여 Tensorflow 분류 모델을 만들 수 있었습니다. 새로운 게시글이 등록되면 학습 모델에 예측을 하여 정해놓은 확률에 따라 신고받기 전 선조치, 다수 신고 자동처리에 활용하여 운영량을 대폭 줄일 수 있었습니다.
더불어 확실한 광고 같은 게시글은 등록 후 바로 미노출되어 사용자에게 불쾌감을 주지도 않게 되어 서비스 품질/만족도를 높일 수 있는 이점도 생겼습니다.
예측 결과


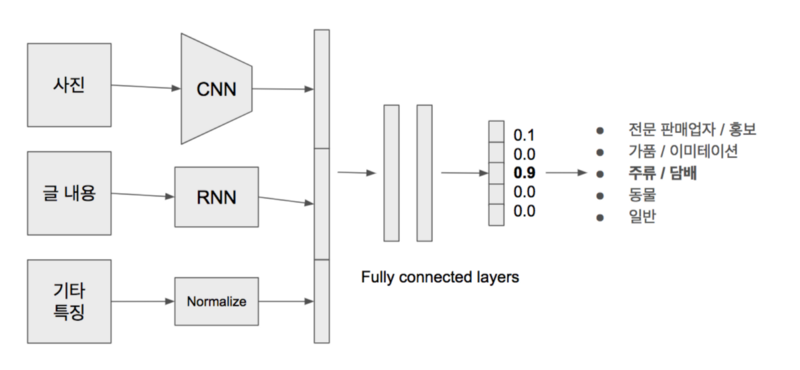
전체 분류 테스트 정확도 accuracy는 88% 결과가 나왔습니다. 중요하게 생각한 것은 일반 게시글 재현율 recall 95% 입니다.
일반 게시글이 다른 분류로 예측되는 피해를 입지 않도록 다른 분류의 정확도 precision를 높이는 것보다 일반 게시글 재현율을 높이는데 중점을 둔 결과입니다.
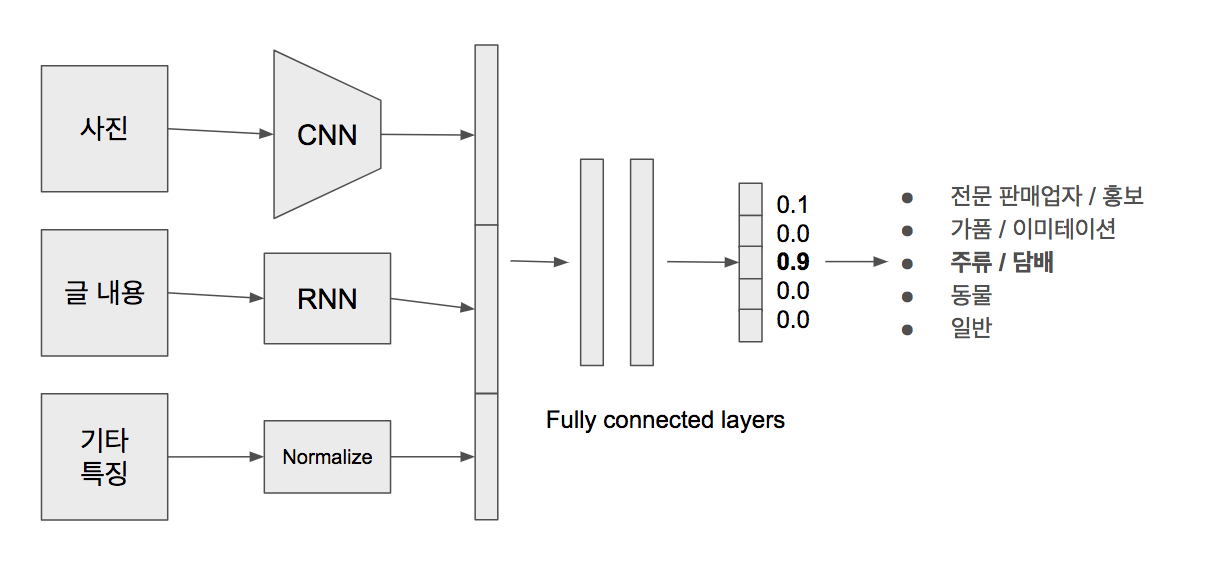
Tensorflow 기반의 CNN, RNN, Fully connected layers로 네트워크를 구성하여 모델을 학습합니다. 이 모델은 Cloud Machine Learning Engine에 배포하여 예측에 사용하고 있으며, cloudml-samples/flowers 예제를 참고하여 모델 배포까지 시스템을 보다 쉽게 구축할 수 있었습니다.
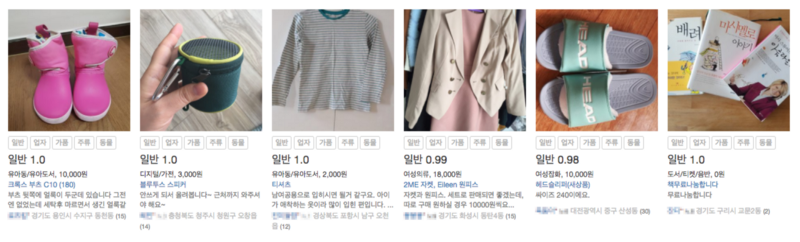
유사한 게시글 찾기
당근마켓은 따뜻한 지역거래를 위해 사기꾼이거나 비매너 사용자를 적극 제재하고 있습니다. 일부는 제재를 받고도 악의적이거나 제재를 피해 새로운 계정을 만들어 활동하여 당근마켓 사용자에게 지속적으로 피해를 주고 있는 문제가 있습니다. 대비책으로 이용 제재 받은 사용자의 게시글과 유사한 글을 올리는 사용자는 같은 사용자일 확률이 높으므로 적극 모니터링 관리 / 자동 처리하고 있습니다.
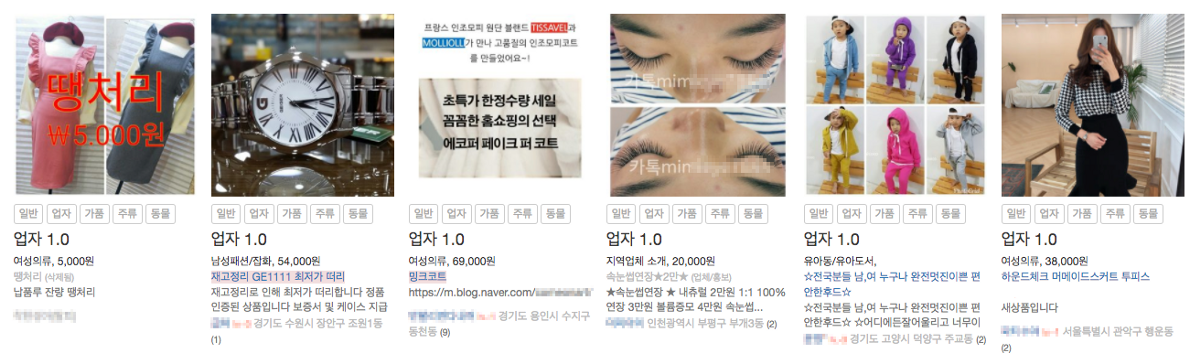
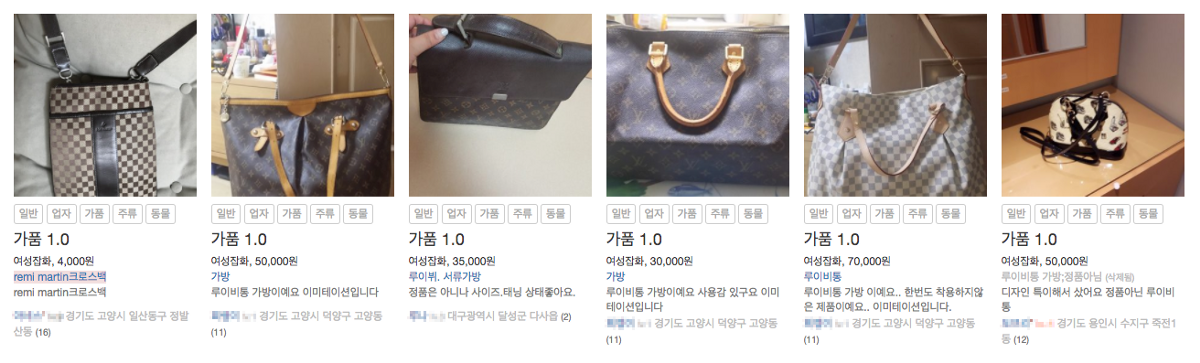
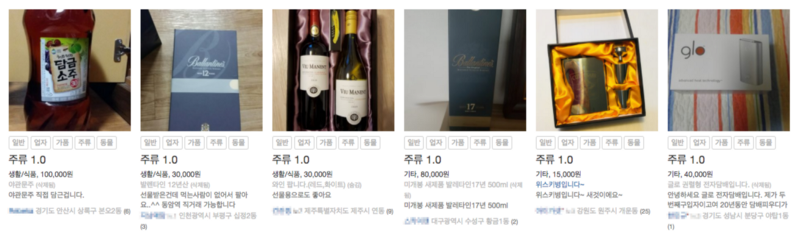
또한 유사한 게시글을 찾는 기능을 통해 비슷한 게시글을 계속 올리는 사용자를 찾아낼 수 있었습니다. 예를 들어 스마트폰만 계속 올리는 전문 판매업자, 다량의 가품 핸드백 판매자가 있었는데 이런 사용자를 쉽게 검출하고 제재하여 반복적인 게시글과 수익의 목적인 사용자를 방지할 수 있었습니다.
특징 추출
유사한 정도를 비교하기 위해 게시글의 특징을 뽑아야 합니다. 사진은 미리 학습하여 공개된 모델인 Inception V4 모델을 사용하였고, 텍스트는 doc2vec (StarSpace — ArticleSpace)을 사용하여 전체 게시글 내용을 학습 데이터로 모델을 비지도 학습 시킨 뒤 특징 embedding을 추출했습니다. 참고로 Inception V4 모델은 1년전부터 이미지 특성 추출하고 있어 그대로 사용한 것으로 이후 더 가볍고 성능이 좋은 새로운 모델로 전환을 하면 좋을 것 같습니다.
인덱스 서버
특징 embedding은 [0.12, 0.48, …, 0.9] 벡터 형태로 기존 데이터베이스에 저장할 순 있지만 비슷한 항목을 검색할 수 없습니다. 모든 벡터를 메모리에 올려서 가장 가까운 벡터를 찾는 방법이 있는데, 메모리 사용량과 검색 시간의 문제를 해결해야 합니다. 이에 매우 적합한 라이브러리인 Faiss를 사용하여 메모리를 적게 사용하며 매우 빠르게 검색할 수 있는 특징 embedding 인덱스를 구축할 수 있었습니다. 추가적으로 당근마켓 서버에서 사용하기 위해 서버간 통신은 gRPC 라이브러리를 활용했습니다.
고객 문의 분류
사용자들은 당근마켓 이용 중 문의사항이 있을 때 텍스트 글을 적어 질문을 보내고 있습니다. 이러한 문의 중 공통된 답변이 많을 경우 FAQ로 정리를 해놓고, 답변시 FAQ 링크를 보내주고 있습니다. 답변을 보낼 때 관련 참고 FAQ 링크를 찾는 작업은 단순하여 더욱 빠르고 편하게 하기 위해 학습 모델을 만들었습니다. 학습 데이터 구성은 답변에서 FAQ 링크를 라벨로 추출하여 문의 내용을 텍스트 분류로 지도 학습했습니다.
텍스트 분류로 사용한 fastText는 간편하고 빠르며 다른 분류 방법에 비해서도 성능도 괜찮게 나왔습니다.
학습 데이터에는 총 142개의 분류(FAQ)에서 각 분류 당 학습 데이터가 많지 않아 분류 테스트 정확도 accuracy는 64%로 높지 않게 나왔습니다. 하지만 앞으로 학습데이터인 FAQ에 대한 답변이 늘어남에 따라 더 높아질거라 예상합니다.
현재 문의 내용의 FAQ 예측이 일정 확률 이상이면 FAQ 추천을 표시하여 답변에 활용하고 있습니다.

유사 고객 문의 찾기
위의 FAQ 답변할 수 있는 고객 문의처럼 간단한 질문도 있지만, 복잡하고 다양한 질문도 많이 있습니다.
저희 당근마켓팀은 운영팀이 따로 있지 않고 팀원 모두 서로 돌아가면서 고객 문의에 답변합니다. 이렇게 여러 사람이 답변하다보니 이미 비슷한 질문에 답변을 한 경우, 참고면 더욱 간편하게 답변을 할 수 있어서 관련 답변이 있는지 여러 키워드로 검색을 해야하는 번거로움이 있었습니다. 이 부분도 텍스트 학습을 통해 더 효율적으로 빠르고 간편하게 찾을 수 있도록 적용해봤습니다.
유사한 질문을 찾기 위해 위의 유사 게시글 찾기처럼 질문의 특징을 추출하여 인덱스 구축하여 찾았습니다.
Embedding Projector로 시각화 해본 결과, 아래처럼 비슷한 질문들의 특징이 가깝게 분포되어 비슷한 질문들을 찾을 수 있는 걸 확인할 수 있었습니다.
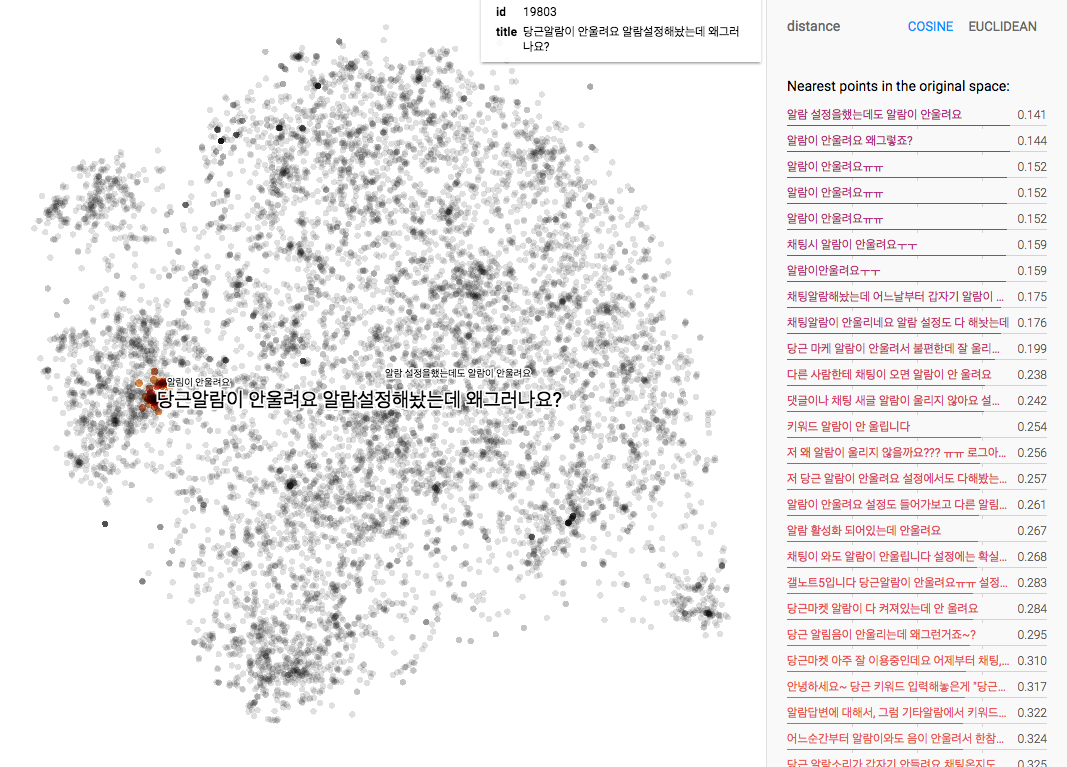
가능성을 확인 후 실제 서비스에 적용으로 문의사항 답변 화면에서 유사 질문의 답변을 표시했습니다. 이제 저를 포함해서 고객문의 담당자는 이미 답변한 비슷한 문의에 대해서 손쉽게 답변할 수 있게 되었습니다. 야호^^!
마치며
당근마켓과 같이 일반 서비스에도 딥러닝을 도입/활용하면서 좋은 점이 많아 공유하게 되었습니다. 위에 언급한 라이브러리와 플랫폼 덕분에 딥러닝 시스템을 구축하기 생각보다 많이 편해진 것 같습니다. 아직 사용해보지 않은 분에게 활용해보시길 추천드립니다.
앞으로도 당근마켓 개인화 / 추천 등 다양한 분야에도 딥러닝을 적극 활용해 볼 계획입니다~!
우리 동네 중고 직거래 마켓 사용해보세요~ https://dngn.kr/2CV0Ztc
[출처] https://medium.com/n42-corp/%EB%8B%B9%EA%B7%BC%EB%A7%88%EC%BC%93%EC%97%90%EC%84%9C-%EB%94%A5%EB%9F%AC%EB%8B%9D-%ED%99%9C%EC%9A%A9%ED%95%98%EA%B8%B0-3b48844eba62
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.