퇴근후 RNN 공부할겸 아래 블로그 글을 한글로 번역하였습니다.
원 저작자, Google Brain의 Chris Olah의 허락을 받고 번역하였습니다.
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
RNN(Recurrent Neural Networks)
인간은 매초 처음부터 생각하지 않습니다. 에세이를 읽을 때, 당신은 바로 전의 문맥에 맞게 다음 단어를 이해합니다. 당신은 모든 내용을 다 던진 다음에 처음부터 생각하지 않습니다. 당신의 생각은 기억력을 가지고 있습니다. 전통적인 뉴럴네트워크 알고리즘에선 이런 기능을 구현할 수 없었습니다. 그리고 이는 중요한 단점이었습니다. 예를 들어, 영화에서 어떤 이벤트가 일어났었는지 구분(classify)하고싶다고 상상해봅시다. 기존의 뉴럴 네트워크 알고리즘에선 특정 이벤트가 일어났을 때 그 전의 일어났던 이벤트 없이 미래의 이벤트를 설명할 수 있는지에 대해 설명하기가 명확하지 않습니다.
RNN(순환신경망, Recurrent Neural Network)는 이런 문제를 지적합니다. RNN은 루프가 들어있고, 과거의 데이터가 미래에 영향을 줄 수 있는 구조를 가지고 있습니다.
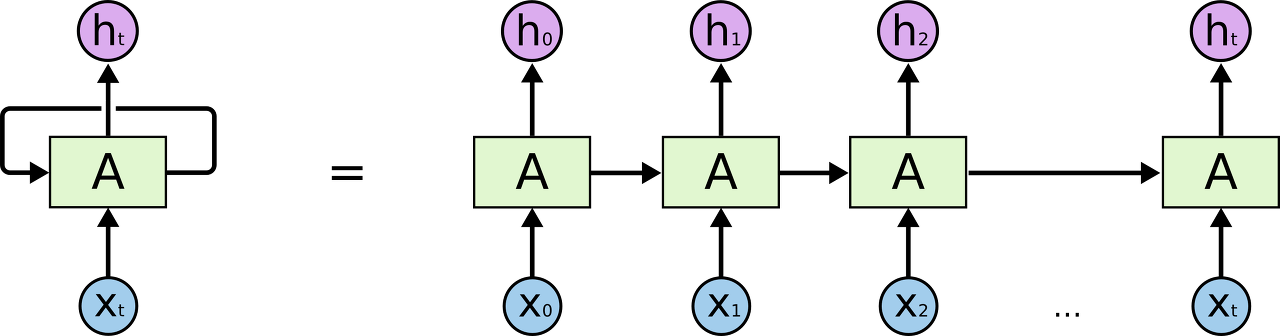
 Recurrent Neural Network는 루프를 가지고 있습니다.
Recurrent Neural Network는 루프를 가지고 있습니다.
위 다이어그램에서 하나의 뉴럴 네트워크 덩어리, A는 xt 를 입력값으로 가지고 ht를 결과값으로 내놓습니다. 이 루프는 정보가 다음 단계의 뉴럴 네트워크로 이동하게 만들어줍니다. 이러한 루프는 Recurrent Neural Network가 뭔가 불가사의하게 느끼게 만들어줍니다. 하지만, 당신이 조금만 더 생각해본다면, 이 알고리즘은 다른 뉴럴 네트워크 알고리즘과 그렇게 큰 차이가 있지 않다는 것을 알게 됩니다. Recurrent Neural Network는 하나의 네트워크가 여러개 복사된 형태를 띄고 있습니다. 각각의 네트워크는 다음 단계로 정보를 넘겨줍니다. 저 루프를 좀 풀어서 보면 아래 그림과 같은 모양을 띄게 됩니다.
이러한 쇠사슬 같은 성격은 Recurrent Neural Network를 이벤트의 연속와 리스트에 적합하게 만들어주었습니다. 이벤트의 연속, 리스트에 관련된 문제를 해결하기 위해 알고리즘을 떠올린다면, 가장 적절한 알고리즘이 되겠습니다. 그리고 RNN은 이미 많은 분야에서 쓰이고 있습니다. 과거 몇 년간, 음성인식, 언어 모델링, 번역, 이미지 캡셔닝 등 여러 분야에서 성공적으로 적용되어 성과를 내고 있습니다. 그리고 그 성공 사례들은 계속되고 있습니다. 저는 이런 RNN을 활용한 엄청난 성공 사례들에 대해선 Andrej Kapathy의 탁월한 블로그 포스트로 대체하겠습니다. The Unreasonable Effectiveness of Recurrent Neural Networks. 진짜 대단합니다.
이러한 성공의 핵심은 "LSTM의 활용"에 있습니다. 아주 특별한 종류의 RNN 알고리즘입니다. 일반 RNN 알고리즘에 비해 아주아주 뛰어나고 다양한 분야에서 쓰일 수 있습니다. RNN 알고리즘의 성과 중에 대부분을 LSTM 알고리즘이 이루어냈습니다. 그리고 이 글에서는 이 LSTM을 설명드릴 것입니다.
장기 의존성(Long-Term Dependency) 문제점
RNN의 장점 중 하나는 이전의 정보를 현재의 문제 해결에 활용할 수 있다는 점입니다. 예를 들어 바로 전의 비디오 프레임은 현재 프레임을 해석하는 데 도움을 줄 수 있죠. 만약에 RNN이 이런 작업을 할 수 있다면 이 알고리즘은 엄청나게 유용할 것입니다. 그런데 진짜 이런 일이 가능한 걸까요? 상황에 따라 다릅니다.
가끔, 우리는 최근 데이터를 가지고 현재의 문제를 해결해야하는 상황에 직면하게 됩니다. 예를 들어서, 이전 단어 선택을 활용하여 다음에 입력될 단어를 예측하는 언어 모델을 생각해봅시다. 만약에 우리가 "the clouds are in the sky,"라는 문장에서 "the clouds are in the"라는 입력값을 받고 마지막 단어를 예측해야 한다면, 우리는 더 이상 문맥이 필요하지 않습니다. 명확하게 다음에 입력될 단어는 "sky"가 될 확률이 높습니다. 이러한 경우에 제공된 데이터와 배워야 할 정보의 입력 위치 차이(Gap)가 크지 않다면, RNN은 과거의 데이터를 기반으로 학습을 할 수 있게 됩니다.
하지만, 우리는 더 많은 문맥이 필요할 때가 있습니다. 예를 들어 "I grew up in France... I speak fluent French.(나는 프랑스에서 자라났어... 나는 프랑스어를 유창하게 해)"라는 문장에서 마지막 단어 French(프랑스어)를 예측하는 문제를 생각해보겠습니다. 최근 정보를 기반으로 예측 모델은 다음 단어가 아마도 언어의 한 종류라고 예측될 것입니다. 그렇다면, 이 예측 모델은 "I grew up in France(나는 프랑스에서 자라났다)"에서 프랑스라는 문맥이 필요하게 됩니다. 실제로 "I grew up in France(프랑스에서 자라났다)"는 표현과 "I speak fluent *** (나는 *** 언어를 유창하게 한다)"라는 표현의 위치가 멀어지는 문제는 아주 빈번하게 발생합니다.
불행히도, 이런 문장표현의 순서상 갭이 커질수록, RNN은 두 정보의 문맥을 연결하기 힘들어집니다.
이론상으로, RNN은 장기 의존성 문제를 해결할 능력이 있습니다. 사람은 이러한 장기 의존성 문제를 풀 수 있도록 신중하게 파라미터를 선택하면 가능은 합니다만, 슬프게도 실제적으로 RNN은 이러한 문맥을 배울 수 없다는 것이 밝혀졌습니다. 이러한 내용은 Hochreiter (1991) [German] 와 Bengio, et al. (1994) 가 다루었습니다. 이 분들은 왜 RNN이 장기 의존성 문제를 해결 할 수 없는지에 대한 논리를 대었습니다.
감사하게도, LSTM은 이러한 문제를 해결하였습니다!
LSTM 네트워크
주로 “LSTMs” 으로 불리는 Long Short Term Memory networks는 특별한 종류의 RNN입니다. LSTM은 장기 의존성 문제를 해결할 수 있습니다. 이러한 LSTM 컨셉은 Hochreiter & Schmidhuber (1997) 이 제안하였고, 많이 개선되고 대중화되면서 다양한 문제에 적용되기 시작했습니다. 그리고 지금 많은 분야에 사용되고 있습니다.
LSTM은 장기 의존성 문제를 해결하기 위해 명시적으로 디자인되었습니다. 오랜 기간동안 정보를 기억하는 일은 LSTM에 있어 특별한 작업없이도 기본적으로 취하게 되는 기본 특성입니다. 장기 의존성 문제를 풀려고 특별히 열심히 노력할 필요가 없습니다.
모든 RNN은 뉴럴 네트워크의 반복되는 체인으로 구성되어있습니다. 표준 RNN에서 이러한 반복되는 모듈은 아주 단순한 구조를 가지고 있습니다. 예를 들어, 단일 tanh 레이어가 있습니다.
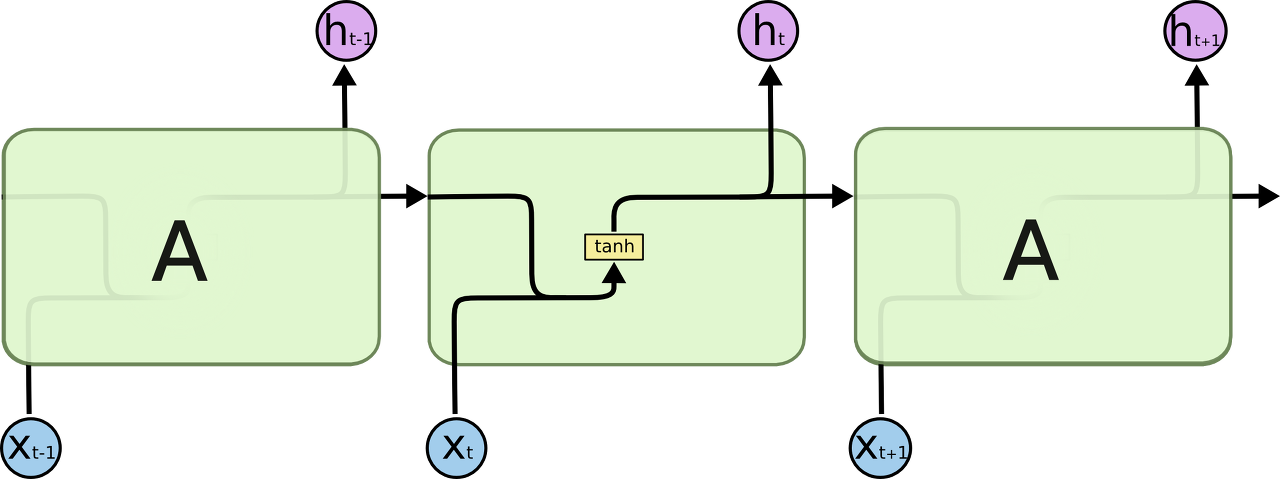 싱글 레이어를 가지고 있는 반복되는 표준 RNN 모듈
싱글 레이어를 가지고 있는 반복되는 표준 RNN 모듈
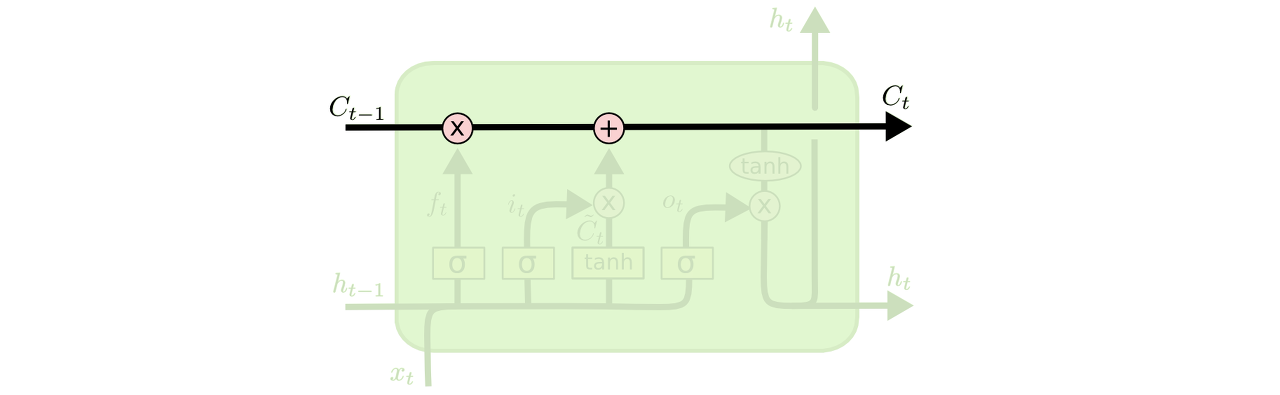
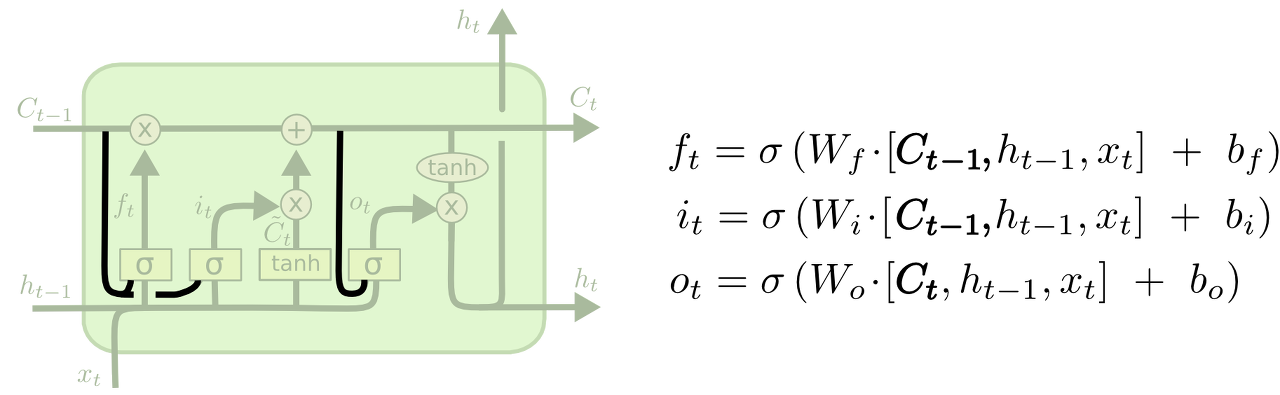
LSTM도 마찬가지로 체인구조를 가지고 있습니다. 하지만 반복되는 모듈은 다른 구조를 가지고 있습니다. LSTM는 단일 뉴럴네트워크 레이어를 가지는 것 대신에, 4개의 상호작용 가능한 특별한 방식의 구조를 가지고 있습니다.
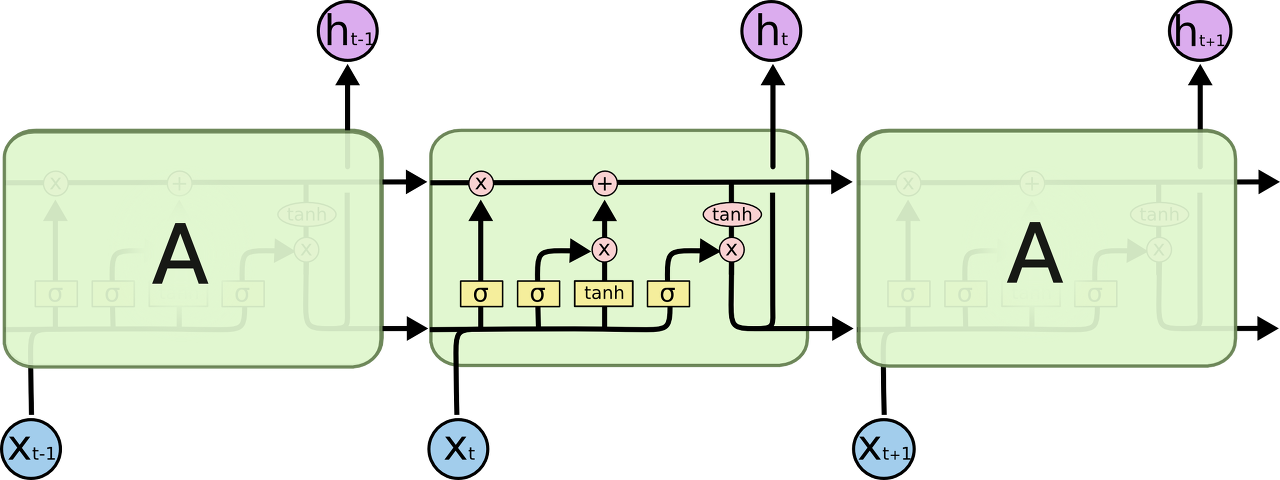 LSTM에 들어있는 4개의 상호작용하는 레이어가 있는 반복되는 모듈
LSTM에 들어있는 4개의 상호작용하는 레이어가 있는 반복되는 모듈
어떤 일이 일어나는지 상세한 내용에 대해선 걱정하지 마세요. 우리는 한 단계 한 단계 LSTM이 구현하는 프로세스를 따라가볼 것입니다. 지금은 우리가 사용할 기호들에 대해서 배워보겠습니다.
위 다이어그램에서 각 라인은 온전한 vector를 포함합니다. 각 출력값은 다른 노드의 입력값이 됩니다. 분홍색 원은 점단위의 연산을 표현합니다(예를 들어, 벡터 더하기 연산이 있습니다.) 그리고 노란색 박스는 뉴럴 네트워크의 단위입니다. 하나로 합쳐지는 4번째 기호는 집중을 의미합니다. 반면에 하나의 화살표가 두개로 나눠지는 5번째 기호는 결과값이 서로 다른 두 노드에 복사되는 것을 의미합니다.
LSTMs의 핵심 아이디어
LSTMs의 핵심은 셀 스테이트(the cell state)입니다. 다이어그램 상단에 있는 수평선입니다.
셀 스테이트(The cell state)는 하나의 컨베이어 벨트와 같습니다. 이것은 아주 마이너한 선형 연산을 거치고 전체 체인을 관통합니다. 이 구조로 인해 정보는 큰 변함 없이 계속적으로 다음 단계에 전달되게 됩니다.
LSTM은 셀 스테이트에 신중하게 정제된 구조를 가진 게이트(gate)라는 요소를 활용하여 정보를 더하거나 제거하는 기능을 가지고 있습니다.
게이트(Gates)들은 선택적으로 정보들이 흘러들어갈 수 있도록 만드는 장치입니다. 이들은 시그모이드 뉴럴 넷(sigmoid neural net layer)와 점단위 곱하기 연산으로 이루어져있습니다.
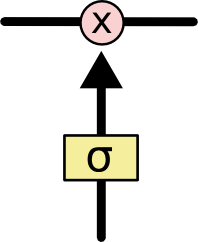 시그모이드 레이어
시그모이드 레이어
시그모이드 레이어(The sigmoid layer)는 0 혹은 1의 값을 출력합니다. 그리고 각 구성요소가 얼마만큼의 영향을 주게 될지를 결정해주는 역할을 합니다. 0이라는 값을 가지게 된다면, 해당 구성요소가 미래의 결과에 아무런 영향을 주지 않도록 만듭니다. 반면에 1이라는 값은 해당 구성요소가 확실히 미래의 예측결과에 영향을 주도록 데이터가 흘러가게 만듭니다.
LSTM은 셀 스테이트를 보호하고 콘트롤하기 위한 세가지 게이트들로 이루어져있습니다.
스텝 바이 스텝 LSTM 따라가기
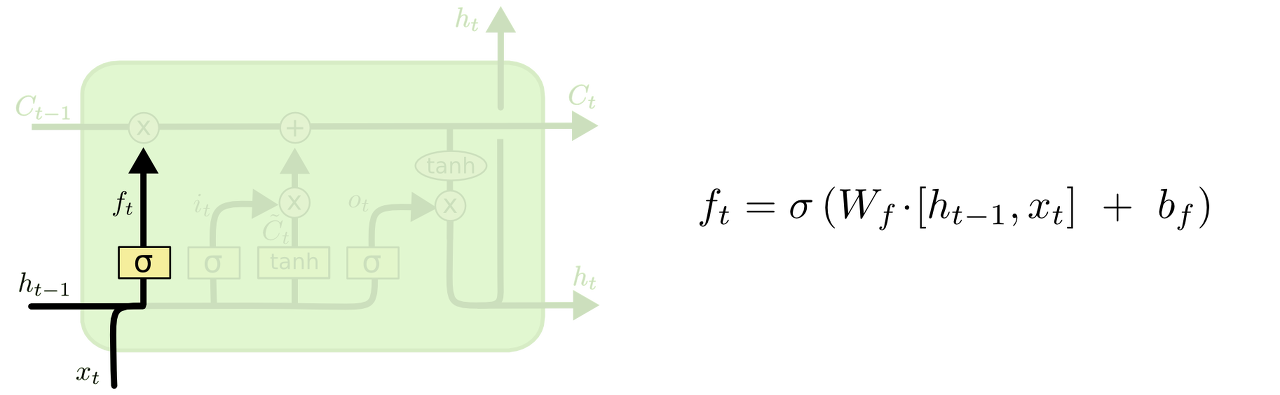
LSTM의 첫번째 스텝은 셀 스테이트에서 어떤 정보를 버릴지 선택하는 과정입니다. 이 결정은 "포겟 게이트 레이어(forget gate layer)"라고 불리는 시그모이드 레이어로 만들어집니다. 이 게이트는 0과 1사이의 출력값을 가지는 ht-1 과 xt 을 입력값으로 받습니다. 출려값이 1이면 "완전히 이 값을 유지해라"라는 뜻이고, 출력값이 0이면 "완전히 이 값을 버려라"라는 뜻입니다.
다시 다음 단어를 예측하는 언어 모델로 돌아가봅시다. 그러한 문제에서, 셀 스테이트(the cell state)에서 특정 주어가 성별을 포함하고 있을 수 있습니다. 그리고 이 성별 표현은 다음에 나올 대명사에 영향을 주게 됩니다. (역자 예시 : "John(남성표현)" likes pizza. So, he(남성형 대명사) ordered it. 남성이름 ... "he"를 예측해야하는 문제를 말함) 그리고, 만약 새로운 주어 표현이 나오게 된다면, 이전의 성별 표현은 잊혀져야만 합니다.
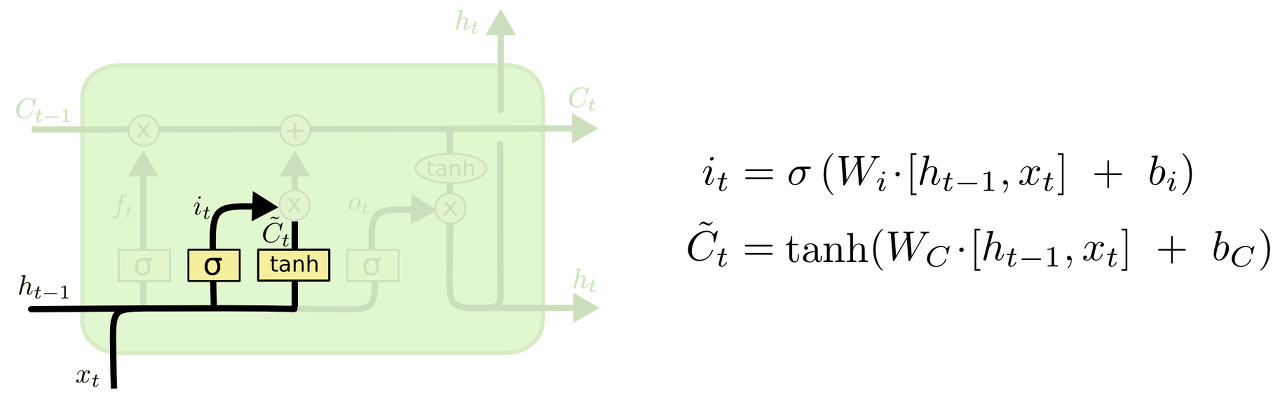
그 다음 스텝은 새로운 정보가 셀 스테이트에 저장될지를 결정하는 단계입니다. 이는 두 단계로 이루어집니다. 첫 번째로, "input gate layer"라고 불리는 시그모이드 레이어는 어떤 값을 우리가 업데이트할 지를 결정하는 역할을 합니다. 그 다음, tanh 레이어는 C̃ t, 값은 셀 스테이트에 더해질 수 있는 새로운 후보 값을 만들어냅니다. 그 다음 스텝으로, 우리는 이러한 두 가지 값을 합쳐서 다음 스테이트에 영향을 주게 됩니다.
우리의 언어 모델의 예시에서 우리는 새로운 주어의 성별을 더할 것입니다. 그리고 이전 표현에서 나왔던 성별 표현은 잊어버릴 것입니다.
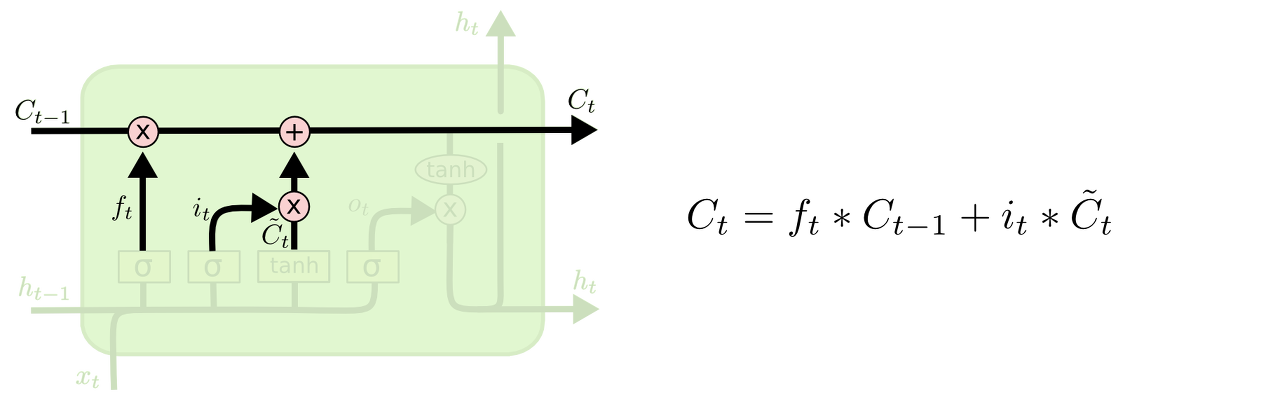
그럼 이제 우리는 오래된 셀 스테이트(Ct−1)를 새로운 스테이트인 (Ct)로 업데이트 할 시간입니다. 전 단계에서 우리는 무엇을 할지 이미 결정했습니다. 그래서 우리는 이 연산을 수행하기만 하면 됩니다.
우리는 오래된 스테이트를 ft로 곱합니다. 우리가 첫번째 스텝에서 잊어버리기로 한 데이터를 잊어버립니다. 그리고 우리는 it ∗ C̃ t를 더합니다. 이는 새로운 후보 값이 기존 값에 영향을 주는 방법입니다.
언어 모델에서 이는 우리가 바로 전에 결정했듯이 이전의 주어의 성별을 버리고 새로운 주어의 성별을 기억하는 방식입니다.
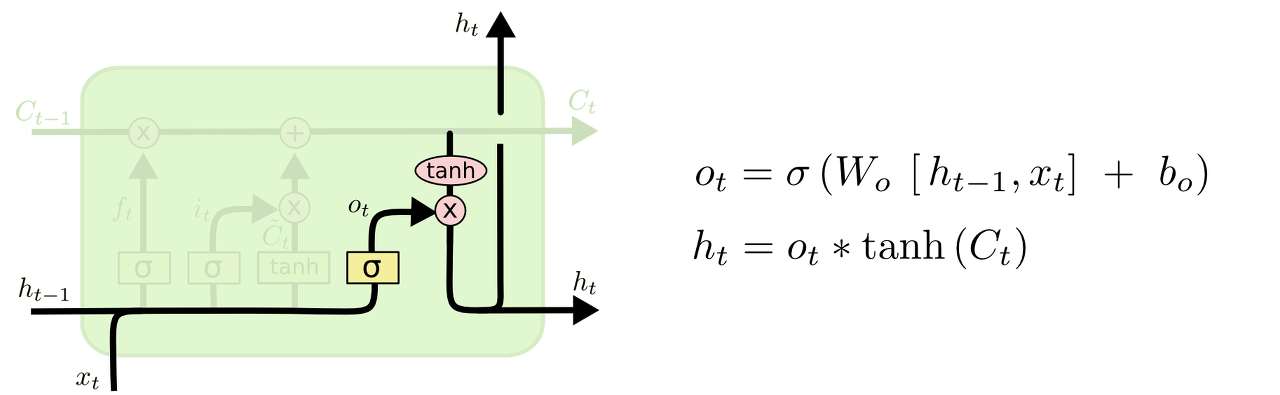
마지막으로, 우리는 어떤 출력값을 출력할지 결정해야합니다. 이 출력값은 우리의 세 스테이트(cell state) 하지만 필터링된 버전입니다. 첫 번째로, 우리는 어떤 값을 출력할 지 결정하는 시그모이드 레이어를 돌릴 것입니다. 그 다음, 우리는 셀 스테이트를 tanh 함수를 거쳐서 -1과 1 사이의 값을 뽑아낼 것입니다. 그리고 이를 시그모이드 게이트의 출력값과 곱할 것입니다. 그래서 우리는 우리가 원하는 값만 결과 값으로 반영할 수 있게 됩니다.
예를 들어, 언어 모델의 예를 들자면, 주어를 한 번 보았기 때문에 예측 모델은 해당 성별을 가진 동사를 사용해야합니다. 예를 들어, 이는 주어가 단수인지 복수인지에 따라 다음 동사가 표현되는 단어가 달라지게 됩니다.
LSTM의 변칙 패턴
제가 위에서 설명한 아주 평범한 LSTM입니다. 하지만 모든 LSTM이 위와 같은 동일한 구조를 갖고 있지는 않습니다. 사실, LSTM을 구현한 모든 논문들은 서로서로 약간 다른 구현체 버전을 가지고 있습니다. 그 차이들은 사실 그리 중요한지는 않습니다만, 그 중에 일부는 소개해드릴 가치가 있어 보입니다.
1번째 변칙) Gers & Schmidhuber (2000)이 소개한 유명한 LSTM 변칙 패턴입니다.
이 버전은 “peephole connections.”을 가지고 있습니다.
이는 게이트(the gate)가 셀 스테이트 자체를 입력값으로 받는 방식을 말합니다.
위 다이어그램에서 peephole을 추가하였습니다. 하지만 많은 논문에서 몇몇에만 peephole을 넣고 나머지는 넣지 않았습니다.
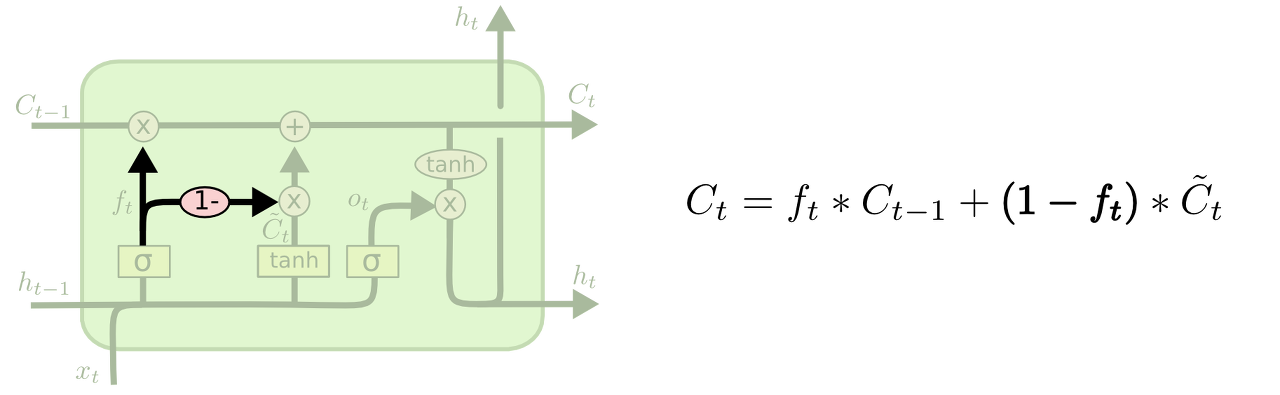
2번째 변칙) 또다른 변칙패턴은 포겟 게이트와 인풋 게이트를 합친 버전입니다. 어떤 값을 잊어버리고 어떤 값을 더할지 과정을 따로따로 수행하는 것이 아니라, 이를 동시에 결정하는 방식입니다. 이 때 우리는 새로운 값이 제공될 때만 이전 값을 잊어버리게 됩니다.
3번째 변칙) 좀더 극적인 변칙패턴은 게이티드 리커런트 유닛(the Gated Recurrent Unit)입니다. 혹은 GRU라고 부릅니다. Cho, et al. (2014) 에 의해 소개되었습니다. 이는 포겟 게이트와 인풋 게이트를 하나의 업데이트 게이트로 통일시켰습니다. 이는 또한 셀 스테이트와 히든 스테이트를 합쳤습니다. 그리고 또한 다른 변화들도 있습니다. 결과적으로 모델은 보통의 LSTM 모델보다는 단순해졌습니다. 그리고 이 변칙 모델은 갈수록 인기를 얻고 있습니다.
이러한 변칙패턴들은 단지 몇몇 주목할만한 LSTM의 변칙패턴들입니다. 그리고 또 엄청 많습니다. 예를 들어, Yao, et al. (2015)의 Depth Gated RNNs. 그리고 완전히 다른 방식으로 장기 의존성 문제를 해결한 Clockwork RNNs by Koutnik, et al. (2014) 도 있습니다..
그럼 어떤 변칙 패턴들이 최고인가요? 그리고 그 차이점들은 어떤 의미를 가질까요? Greff, et al. (2015)는 이러한 변칙패턴들에 대해 자세히 비교분석하였습니다. 그리고 각각의 거의 비슷하다는 것을 발견했습니다. Jozefowicz, et al. (2015) 는 약 만 가지 이상의 RNN 아키텍쳐를 실험해보았는데, 몇몇 RNN 변칙패턴들은LSTM보다 성능이 좋았던 경우가 있다는 것을 발견했습니다.
결론
일찍이, 저는 사람들이 RNN을 활용하여 엄청난 성과를 거두고 있다는 사실을 언급하였습니다. 핵심적으로 모든 이러한 것들은 LSTM을 활용한 결과였습니다. LSTM은 거의 모든 영역에서 다른 RNN알고리즘에 비해 탁월한 성능을 보여주고 있습니다.
이렇게 공식들을 적어놓고 보면, LSTM은 많이 어려워보입니다. 하지만 제가 설명해드린 스텝바이스텝 설명이 여러분들로 하여금 좀 더 LSTM을 친숙하게 만드는데 도움이 되었기를 바랍니다.
LSTM은 우리가 RNN으로 성취할 수 있는 하나의 빅 스텝입니다. 그럼 우리는 이러한 질문을 갖는 것은 자연스러울 것입니다. "다른 빅 스텝은 없는 걸까요?" 연구자들 사이에서 일반적인 의견은 "그렇습니다! 앞으로 빅 스텝이 분명히 있고, 이는 attention입니다!" 이 아이디어는 모든 스텝의 RNN이 거대한 정보로부터 입력값을 받는 방식입니다. 예를 들어 당신이 만약 이미지에 캡션을 달기 원한다면, 특정 이미지 영역을 모든 단어를 표현하는데 활용할 수 있습니다. 사실, Xu, et al. 는 이미 이러한 방식을 구현하였습니다. 만약에 관심이 있으시다면 attention을 공부해보셔도 좋습니다!
Attention만 RNN 연구의 흥미있는 주제는 아닙니다. 예를 들어 Kalchbrenner, et al.의 Grid LSTMs은 극단적으로 희망적입니다!
(밑에는 주 내용과는 상관없어서 번역하지 않았습니다.)
Acknowledgments
I’m grateful to a number of people for helping me better understand LSTMs, commenting on the visualizations, and providing feedback on this post.
I’m very grateful to my colleagues at Google for their helpful feedback, especially Oriol Vinyals, Greg Corrado, Jon Shlens, Luke Vilnis, and Ilya Sutskever. I’m also thankful to many other friends and colleagues for taking the time to help me, including Dario Amodei, and Jacob Steinhardt. I’m especially thankful to Kyunghyun Cho for extremely thoughtful correspondence about my diagrams.
Before this post, I practiced explaining LSTMs during two seminar series I taught on neural networks. Thanks to everyone who participated in those for their patience with me, and for their feedback.
In addition to the original authors, a lot of people contributed to the modern LSTM. A non-comprehensive list is: Felix Gers, Fred Cummins, Santiago Fernandez, Justin Bayer, Daan Wierstra, Julian Togelius, Faustian Gomez, Matteo Gagliolo, and Alex Graves.↩