
텍스트를 음성 mp3로 간단하게 변환하기 (With Naver Cloud Platform) : 딥러닝 몰라도 TTS 하는 법
텍스트를 음성 mp3로 간단하게 변환하기 (With Naver Cloud Platform)
: 딥러닝 몰라도 TTS 하는 법
Naver Cloud Platform(이하 NCP)은 AI 서비스를 API 형태로 제공한다. 성능은 그들도 신이 아니기에 100% 완벽하지는 않지만, 직접 만들자 생각해보면 답 없… 적어도 현존하는 서비스 중에는 가장 높은 수준을 보이지 않나 생각한다(실제로 수많은 Task들에 이름을 올린 것으로 증명했다).
이번엔 NCP의 Text-to-Speech(TTS) 모듈인 Clova Speech Synthesis(CSS)를 사용해 본 후기를 공유하고자 한다.
1. 애플리케이션 등록
언제나와 같이 NCP로 이동하여 서비스를 신청하도록 하자. [서비스] → [AI Service] → [Clova Speech Synthesis(CSS)]로 이동한 후 [이용 신청하기]를 눌러주길 바란다.
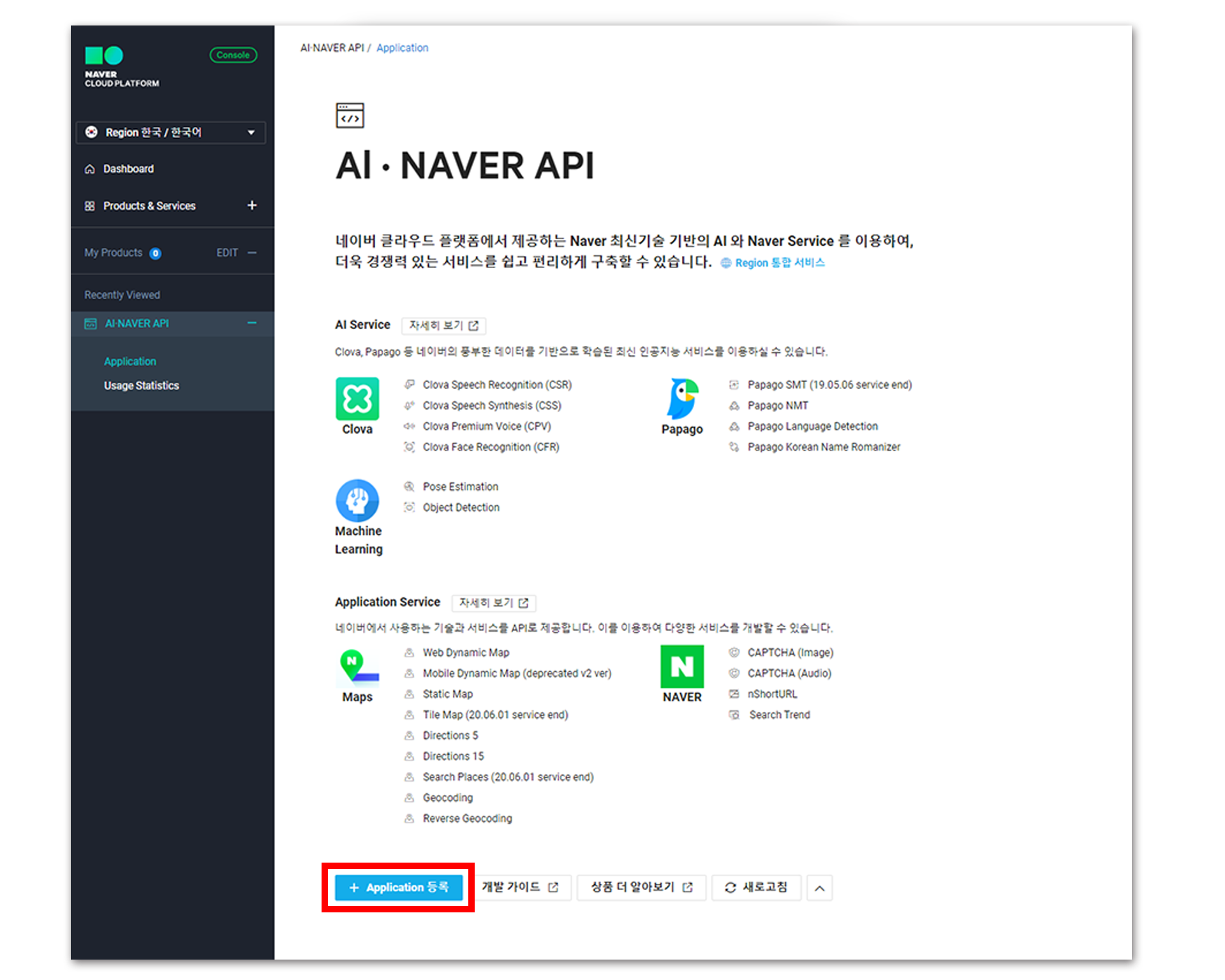
TTS는 STT와 굉장히 밀접한 관계를 가지고 있다. CSR과 CSS 또한 그러하여, 사용법이 굉장히 유사하다. [Application 등록]을 눌러 서비스를 생성!
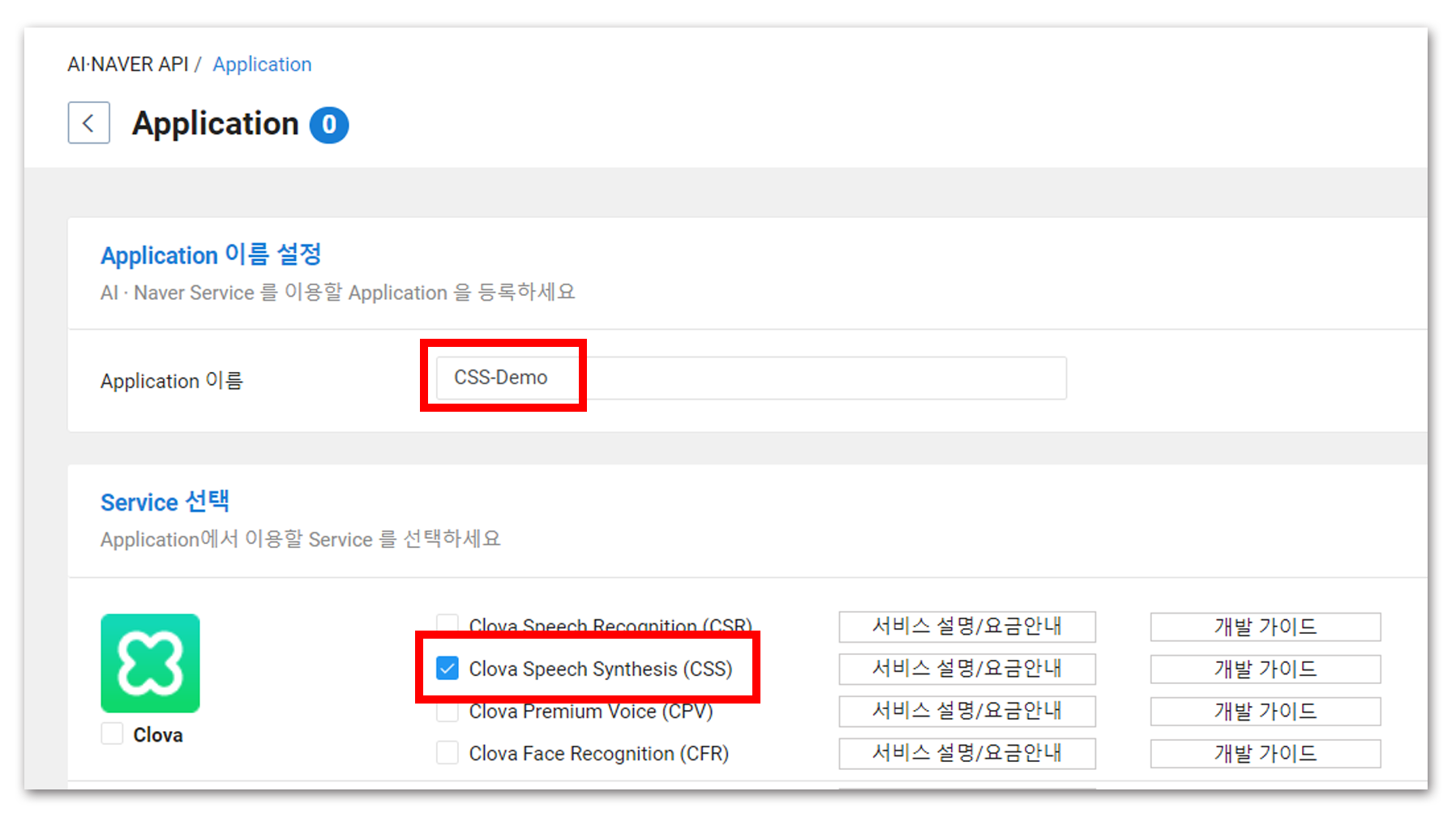
Application 이름을 입력한 후, 아래 리스트에서 사용하고자 하는 서비스를 선택한다. NCP에서 제공하는 TTS 모듈의 이름은 CSS임에 유의한다. 체크해준 후, 아래로 쭉쭉!
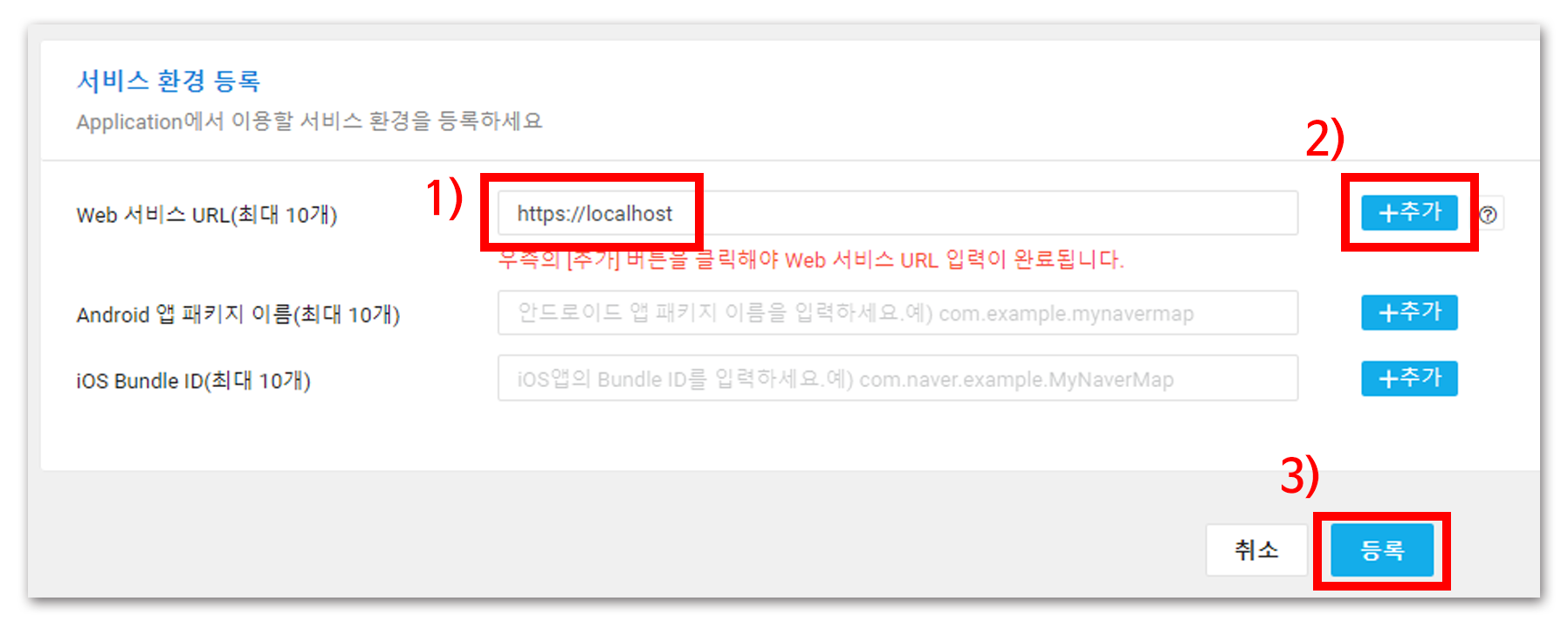
Android와 iOS는 이번 글에서는 다루지 않는다(자꾸 CSR 때 했던 말을 반복하는 것 같다). 로컬 환경에서만 요청을 주고받을 것이므로 서비스 환경 등록 부분에는 https://localhost 를 입력하고 추가하면 애플리케이션을 등록할 수 있다.
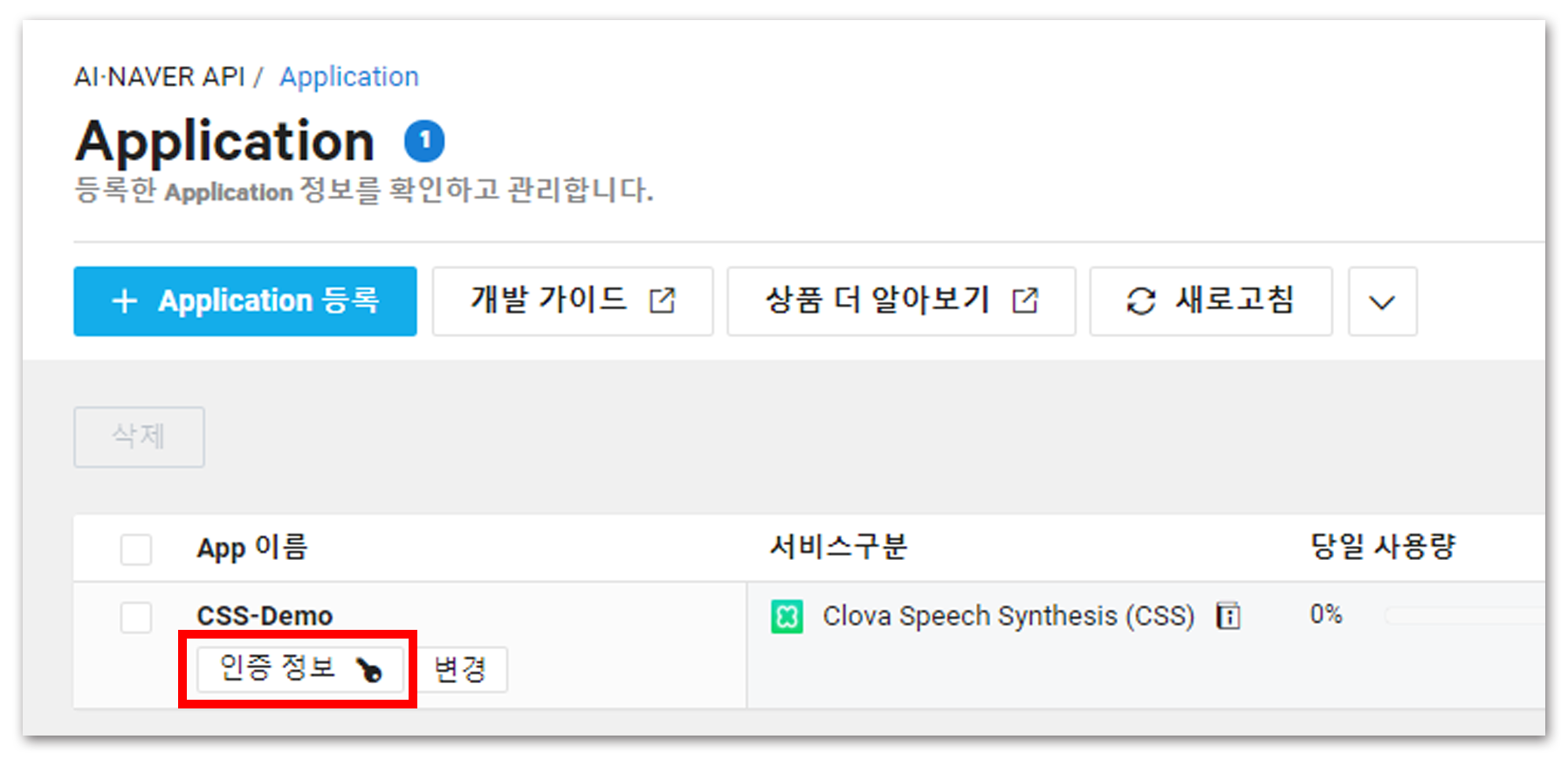
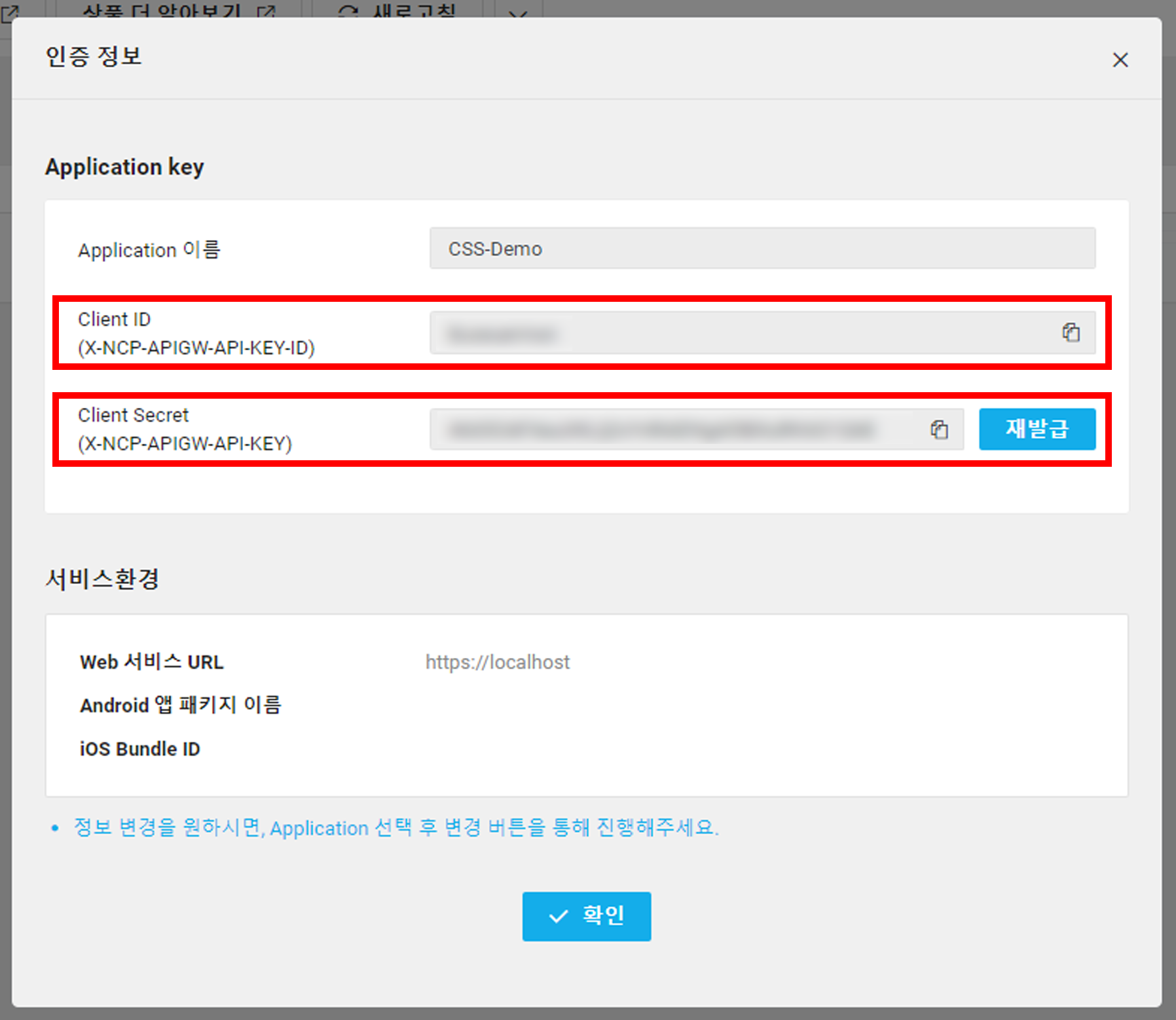
생성된 서비스의 [인증 정보]를 메모해두면 NCP에서 할 일은 끝났다. 정말 간단하다!
2. API 사용
이번 모듈은 JSON 형태로 사용하는 방법을 알아내지 못했다(필자의 견문이 부족해서…). 하지만 Usage만 잘 살펴도 원하는 대로 커스텀 할 수 있을 정도로 코드가 간단하니, 걱정은 말자!
아래 소스를 실행하면 text의 텍스트가 음성 파일로 변환되어 소스 경로에 저장된다.
* 참고: 필자는 Jupyter Notebook에서 테스트를 진행했으며 그 외의 환경에서는 동작하지 않을 수 있다.
import os
import sys
import urllib.request
import time
client_id = "your_client_id" # 인증 정보의 Client ID
client_secret = "your_client_secret" # 인증 정보의 Client Secret
speaker = "jinho"
"""
음성 합성에 사용할 목소리 종류
mijin : 한국어, 여성 음색
jinho : 한국어, 남성 음색
clara : 영어, 여성 음색
matt : 영어, 남성 음색
shinji : 일본어, 남성 음색
meimei : 중국어, 여성 음색
liangliang : 중국어, 남성 음색
jose : 스페인어, 남성 음색
carmen : 스페인어, 여성 음색
"""
speed = 0 # -5(Fast) to 5(Slow)
text = urllib.parse.quote("네이버 클라우드 플랫폼의 CSS 모듈 시험 문장입니다.")
data = "speaker=" + speaker + "&speed=" + str(speed) + "&text=" + text
url = "https://naveropenapi.apigw.ntruss.com/voice/v1/tts"
request = urllib.request.Request(url)
request.add_header("X-NCP-APIGW-API-KEY-ID", client_id)
request.add_header("X-NCP-APIGW-API-KEY", client_secret)
response = urllib.request.urlopen(request, data=data.encode('utf-8'))
if response.getcode()==200:
print("CSS 성공! 파일을 저장합니다.")
now = time.localtime()
response_body = response.read()
file_name = "%04d%02d%02d_%02d%02d%02d" % \
(now.tm_year, now.tm_mon, now.tm_mday,
now.tm_hour, now.tm_min, now.tm_sec) + "_" + \
speaker + "_" + str(speed) + "_"
with open(file_name + ".mp3", 'wb') as f:
f.write(response_body)
print("파일명:", file_name)
else:
print("Error Code:" + rescode)


"네이버 클라우드 플랫폼의 CSS 모듈 시험 문장입니다.""
오… 제법 자연스러운 음성이 생성되었다.
하지만 Clova의 음성 생성 프로젝트들은 직접 더빙을 하거나 전화 상담을 할 정도로 수준이 높아 그만큼 기대가 되었는데, 그에 비하면 조금 아쉬운 결과긴 하다. 사실 요청 오는 고작 한 문장으로 감정 상태를 파악하는 게 절대 쉽지 않아서(솔직히 불가능이라서) 이보다 자연스러운 억양은 자동으로는 안될 것 같고, 감정 상태를 직접 정의해주는 방식으론 가능하지 않을까 생각한다. 작성 중에 알아보니 Clova Premium Voice에서 해당 기능을 지원하는 듯하다, 추후 다뤄보겠다...
가지고 놀만한 것은 Speaker! 꽤 많은 음성이 준비되었다고 생각했는데, 직접 해보니 지원되지 않는 음성이 많았다. 한국어를 지원하는 음성이 있고, 올바른 언어를 전달해줘야만 동작하는 언어가 있다(대부분). 각자의 음성을 들어보도록 하자!
모든 음성 펼치기
mijin (한국어, 여성 음색)jinho (한국어, 남성 음색)clara (영어, 여성 음색)matt (영어, 남성 음색)shinji (일본어, 남성 음색)meimei (중국어, 여성 음색)liangliang (중국어, 남성 음색)jose (스페인어, 남성 음색)carmen (스페인어, 여성 음색)
다 각국의 언어로 TTS를 진행했지만 한국어를 지원하는 음성은 뭐였냐면…
...?
정말 이해할 수 없지만 이게 돼버렸다! 영어로 발음 기호를 적어서 준 것도, 일본어로 변환해서 준 것도 아니고… 그냥 한국어를 전달했는데 TTS가 된다! 다른 언어들은 한국어만 전달하면 인식할 수 있는 단어가 없어 HTTPError 400을 발생시킨다. 오직 shinji , 일본어에만 가능하다!
텍스트를 발음 기호로 변환 후 처리하는 방식이 아닐까?라는 생각을 했는데, 그런 방식이면 어떤 언어던 다 작동되는 게 맞고… 정말 이해할 수 없다… 어쩌면 클로바 팀도 한본어를 꿈꾸고 계셨던 걸까 ㅋㅅㅋ?
여하튼 한본어가 성공했으니 저 말을 스페인 억양으로 너무 시켜보고 싶은데 그게 안돼서 아쉽다…… 일본어도 해냈으니 스페인어도 해내실 수 있습니다…… 클로바 화이팅…!
Reference
[출처] https://dev-sngwn.github.io/2020-02-16-tts-step-by-step/
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.