
[一日 30分 인생슬리의 학습법] Improving CartoonGAN 소개
2021.05.20 12:56
[一日 30分 인생슬리의 학습법] Improving CartoonGAN 소개
Improving CartoonGAN
본 포스트는 실제 사진 이미지를 특정 만화의 장면처럼 바꾸는 것이 가능한 CartoonGAN을 구현해 본 결과와 그 성능을 측정해보고 기존 CartoonGAN 모델을 개선해보는 실험에 대한 내용을 담고 있습니다.
실험에 사용한 코드는 DIYA 동아리 저장소를 참고해주세요.
학습은 KC-ML2의 지원으로 AWS p3.2xlarge 인스턴스에서 진행하였습니다.
INDEX
1. Generative Adversarial Networks
GAN
GAN(Generative Adversarial Networks) 1은 2014년 발표 이후에 이미지의 생성과 관련된 딥러닝 연구에서 놀라운 결과물들을 보여주고 있습니다. GAN의 메인 아이디어는 실제 데이터와 유사한 가짜 데이터를 생성하는 Generator와 이를 구분하는 Discriminator를 번갈아 학습시키는 것입니다. GAN의 학습이 이상적인 경우 학습을 거듭할수록 Generator는 Discriminator를 속이기 위해 주어진 데이터와 매우 유사한 데이터를 생성할 수 있게 됩니다.
결국 GAN은 서로 다른 기능을 하는 두 개의 네트워크를 동시에 학습시키며 성능을 향상시키는 것인데 이 과정은 다음의 수식을 통해서 이해할 수 있습니다.
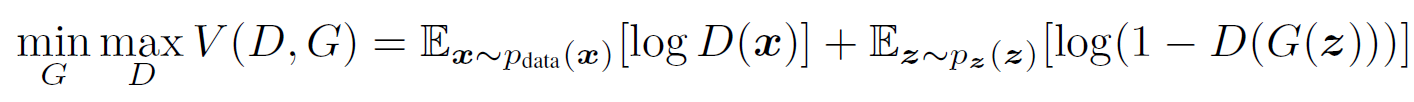
D, G 는 각각 Discriminator와 Generator를 나타냅니다. Discriminator의 관점에서는 실제 데이터가 주어졌을 때 1을 출력하고 Generator가 생성한 가짜 데이터에 대해서는 0을 출력할 때 위의 목적함수를 최대화할 수 있게 됩니다. 반면에 Generator의 관점에서는 Discriminator를 속이는 것이 목적이므로 생성한 데이터가 Discriminator에게 주어졌을 때 1이 출력된다면 전체 목적함수를 최소화 할 수 있습니다. 따라서 각 학습 단계에서 특정 배치 사이즈의 실제 데이터 샘플과 노이즈 벡터 z에 대해서 위의 목적함수를 gradient ascending하여 Discriminator를 학습시키고 이후에 노이즈 벡터 z에 대해서 위의 목적함수에 G가 포함된 부분을 gradient descending하여 Generator를 학습시키게 됩니다. 이 과정이 하나의 step일 때 이를 여러 step 반복하는 과정이 전체 GAN의 학습 과정입니다.
앞서 이 과정이 이상적일 때라고 표현한 것은 GAN이 학습과정에서 초기에 의도했던 목표대로 이뤄지지 않을 가능성이 있기 때문입니다. GAN 학습의 가장 큰 문제로는 1) minimax game의 특성상 모델 파라미터의 수렴이 보장되지 않는다는 점과 2) Generator는 Discriminator를 가장 잘 속일 수 있는 특정 데이터만을 생성하게 되는 문제가 발생할 수 있다는 점이 있습니다.
DCGAN
이렇듯 이후 연구는 GAN을 어떻게 안정적으로 학습시킬 수 있을 수 있을 것인가에 대해 진행되었습니다. 대표적인 연구로는 흔히 DCGAN 으로 불리는 Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks 2 가 있습니다. DCGAN 은 CNN을 GAN에 적용하였고 이 과정에서 모델이 안정적으로 학습하기 위한 다음과 같은 가이드라인을 제시하고 있습니다.

Discriminator와 Generator에 Batch Normalization을 사용할 것, Generator의 아웃풋 레이어를 제외한 모든 레이어에 ReLU를 사용할 것과 같은 DCGAN의 가이드라인은 본 실험에서 중점적으로 구현해 본 CycleGAN이나 CartoonGAN 과 같은 새로운 GAN 모델들이 나올 수 있는 바탕이 되었습니다.
CycleGAN
사진 이미지를 만화 장면의 이미지로 바꾸는 task를 style transfer, 혹은 더 넓은 범위에서 image-to-image translation이라고 부릅니다. 이러한 style transfer task를 GAN을 활용하여 해결한 논문으로는 흔히 Pix2pix 라고 불리는 Image-to-Image Translation with Conditional Adversarial Networks 3 가 있습니다.
Pix2pix 의 경우, paired 데이터를 필요로 합니다. 하지만 이러한 paired 데이터를 구하는 것은 현실적으로 많은 제약이 따르고, 이러한 paired 데이터가 전혀 없는 경우도 있습니다. 흔히 CycleGAN 이라고 불리는 Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks 4 에서는 paired 데이터가 없이도 하나의 Domain에서 다른 Domain으로 이미지를 변환하는 것이 가능하다는 것을 보여주었습니다. 아래의 그림은 CycleGAN 의 구조를 나타낸 것입니다.
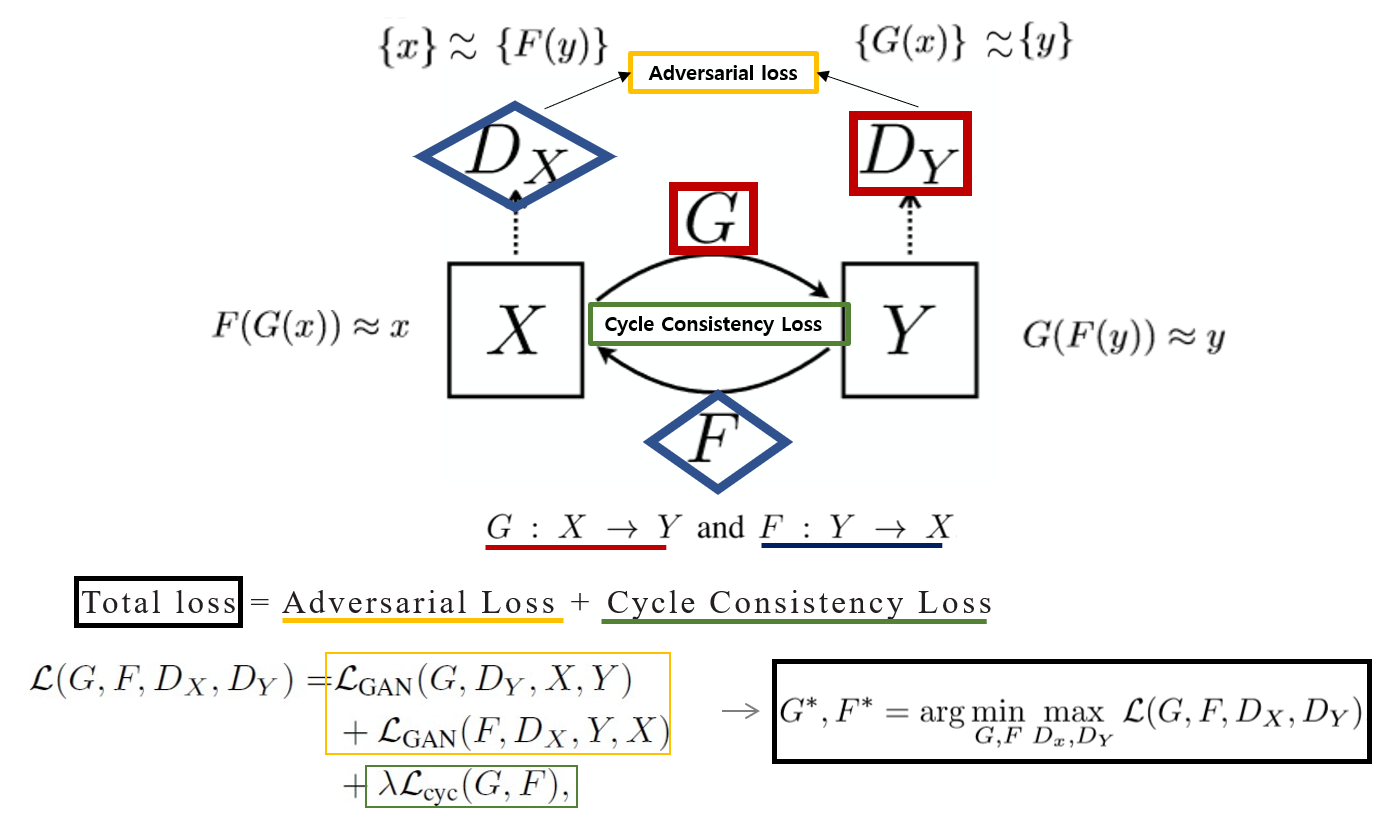
CycleGAN 의 경우에 2개의 Domain에 대해서 하나의 Domain에서 다른 Domain으로의 데이터를 mapping(생성)하는 Generator와 이를 구분하기 위한 Discriminator가 존재하므로 Generator와 Discriminator가 각각 2개씩 존재합니다. CycleGAN이 unpaired 데이터에 대해서도 학습이 가능할 수 있는 가장 큰 이유는 추가로 도입한 Cycle-consistency Loss의 영향입니다. 만약 A Domain의 이미지를 B Domain으로 변환한다고 했을 때, A Domain과 관련이 없지만 B Domain에 속한 이미지가 나올 수 있습니다. 데이터가 unpaired이므로 서로 다른 두 Domain 사이에 관계성을 정의하기가 어려워집니다. Cycle-Consistency Loss는 원래 데이터 x(A Domain)를 받아 생성된 데이터 y = G(x) (B Domain)를 다시 한번 원래 도메인(A Domain)으로 보냈을 때, 생성되는 데이터 x’ = F(y) = F(G(x))와 x의 차이를 적게 하는 방향으로 학습됩니다. 즉 Cycle-Consistency Loss에 의해서 하나의 Domain에서 다른 Domain으로 mapping이 일어나도 원래 Domain에 속한 데이터를 잘 복원하도록 학습이 일어나게 됩니다.
CycleGAN 은 실험에서 말을 얼룩말로 바꾸거나 계절을 바꾸는 등의 style transfer가 가능함을 보여줍니다. 하지만 강아지를 고양이로 바꾸지 못하는 등 주어진 물체의 형상을 바꾸는 것은 잘 하지 못하는 한계점도 보여주고 있습니다.
2. CartoonGAN 논문 소개
CartoonGAN: Intro
CartoonGAN: Generative Adversarial Networks for Photo Cartoonization 5 은 GAN을 사용하여 실제 사진을 카툰 이미지로 변환합니다. 이렇게 사진을 카툰 이미지의 스타일로 바꾸는 task를 cartoon stylization이라고도 부릅니다. cartoon stylization의 목표는 input 사진 내용을 유지하면서 카툰 스타일로 변환하는 것입니다. 이때 높은 퀄리티의 카툰 이미지 변환을 위해서는 카툰 스타일의 두 가지 특별한 특징이 고려되어야 합니다. 먼저 카툰은 단순하고 추상화된 (simplified and abstracted) 특징을 갖습니다. 기존의 style transfer 방법은 원본 이미지에 질감을 추가하는 방법으로 스타일 변환을 했는데 (ex. 사진에서 고흐의 그림 스타일로 변화), 카툰의 경우 다른 예술방식과는 다르게 오히려 질감이 단순화됩니다. 또한 만화 이미지를 떠올려보면 카툰 이미지는 사진이나 다른 예술방식에는 없는 분명한 경계선 과 부드러운 음영 을 가집니다. 이와 같은 독특한 특징으로 인해 카툰 스타일 변환에는 기존과는 다른 objective가 요구됩니다.

CartoonGAN 은 트레이닝 데이터 셋으로 unpair된 실제 사진 데이터셋과 카툰 데이터셋을 사용합니다. CartoonGAN 논문의 데이터셋은 실제사진 6153장과 신카이 마코토 감독의 애니메이션 이미지 4500여장, 미야자키 하야오 감독의 애니메이션 이미지 3600여장이 사용합니다. 논문에서는 모든 트레이닝 이미지를 256x256사이즈로 resizing 했습니다.
CartoonGAN: 구조와 Objective
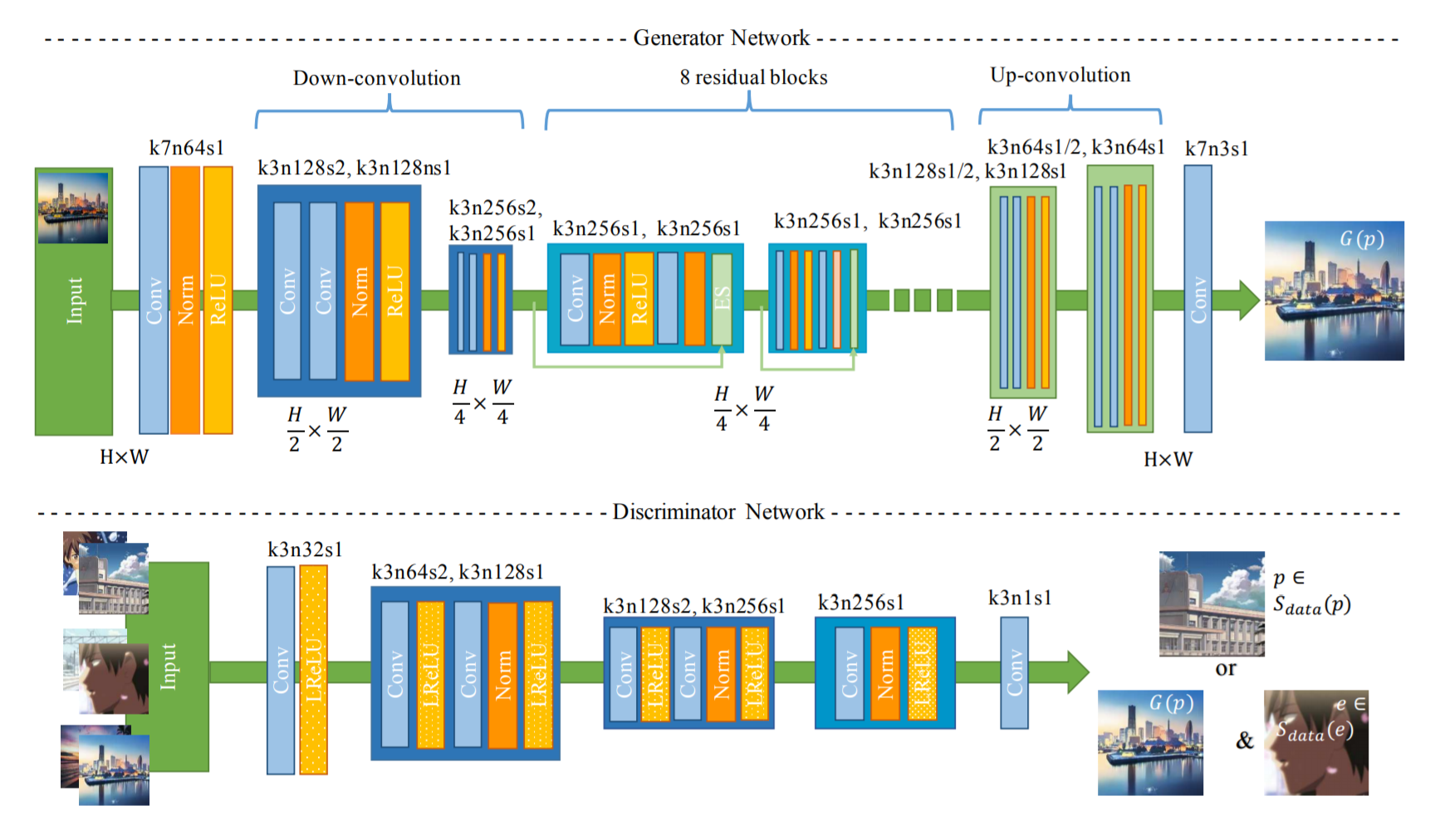
CartoonGAN 은 실제 사진을 카툰이미지로 변환하는 학습을 하는 Generator(G) 와 Generator가 생성한 이미지와 카툰 데이터셋의 이미지를 분별하는 Discriminator(D) 로 구성됩니다.
CartoonGAN 의 Generator는 CycleGAN 과 유사하게 8개의 residual block으로 구성되어있습니다. CartoonGAN 의 Discriminator는 patch-level discriminator를 사용하였습니다.
CartoonGAN 의 Loss는 Adversarial Loss와 Content Loss로 이루어져있습니다.
Adversarial Loss
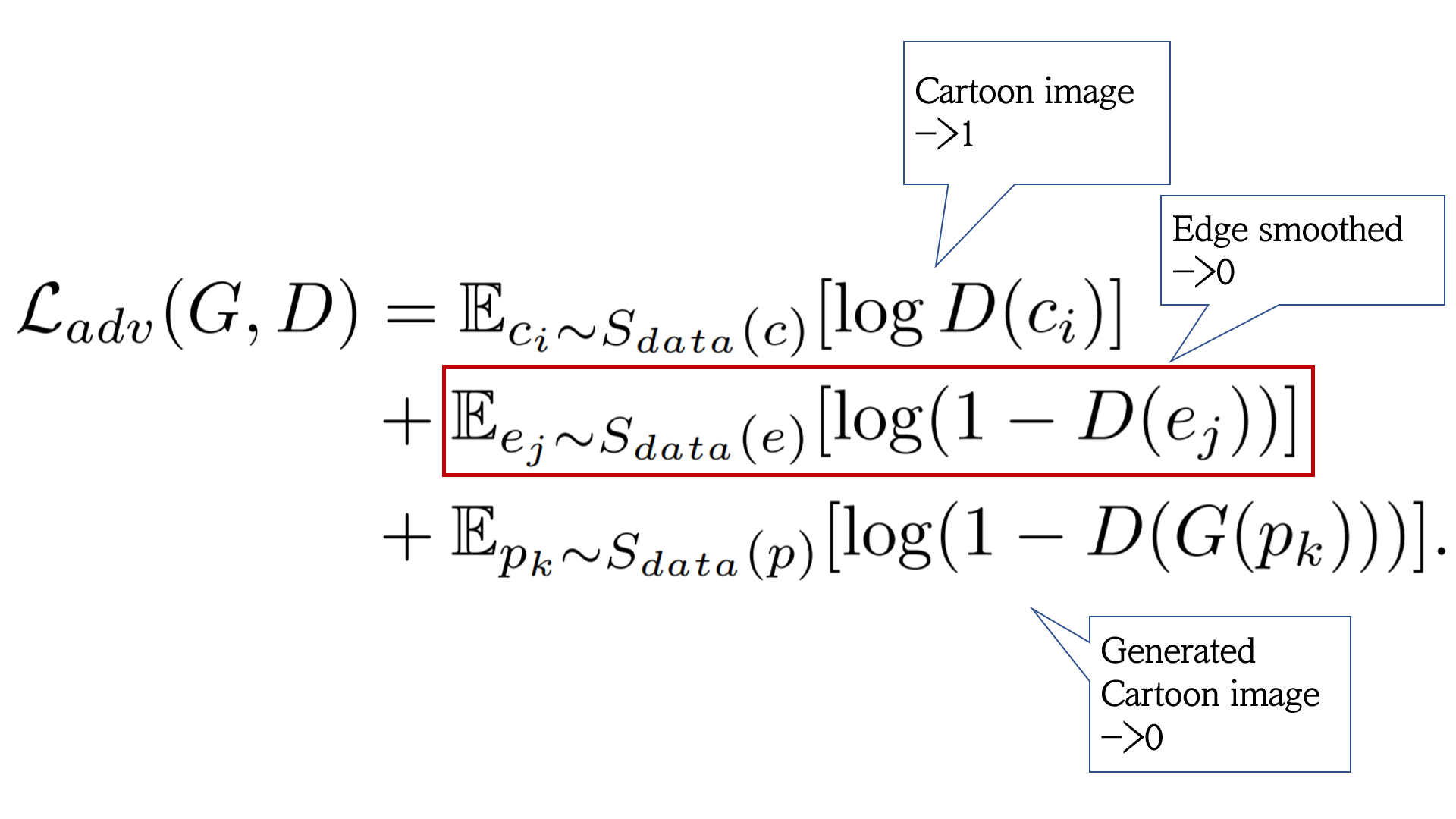
Adversarial Loss는 일반적인 GAN의 Adversarial Loss에 더해 카툰 이미지의 특성을 반영하여 edge-smoothing 부분이 추가돼 있습니다. 논문의 저자들은 일반적인 Adversarial Loss를 사용하여 학습했을 때 생성된 이미지의 가장자리 선 (edge)이 뚜렷하지 않다는 점을 발견했습니다. CartoonGAN 에서는 이를 해결하기 위해 카툰 이미지에서 가장자리 선을 부드럽게 Smoothing한 이미지 데이터 셋을 생성하고 Discriminator가 이러한 이미지를 입력으로 받았을 때 0을 아웃풋 하도록 (카툰 이미지가 아니라고 판단하도록) 하는 edge-smoothing 파트를 추가하였습니다.

edge-smoothing 파트가 추가된 Adversarial Loss 식은 아래와 같습니다. 식을 보면 D가 원본 카툰 이미지 인풋을 받으면 1을 Edge Smoothing이 적용된 이미지 인풋을 받으면 0을 Generator가 생성한 이미지 인풋을 받으면 0을 아웃풋으로 출력하도록 훈련됩니다.
Content Loss
두번째로 Content Loss는 인풋 사진의 내용을 유지하도록 강제합니다. Loss 식을 보면 원본 사진을 카툰 이미지로 변환한 output과 input 사진의 특징을 VGG 네트워크를 사용하여 추출하고 두 특징 사이의 차를 L1 distance로 나타냅니다.
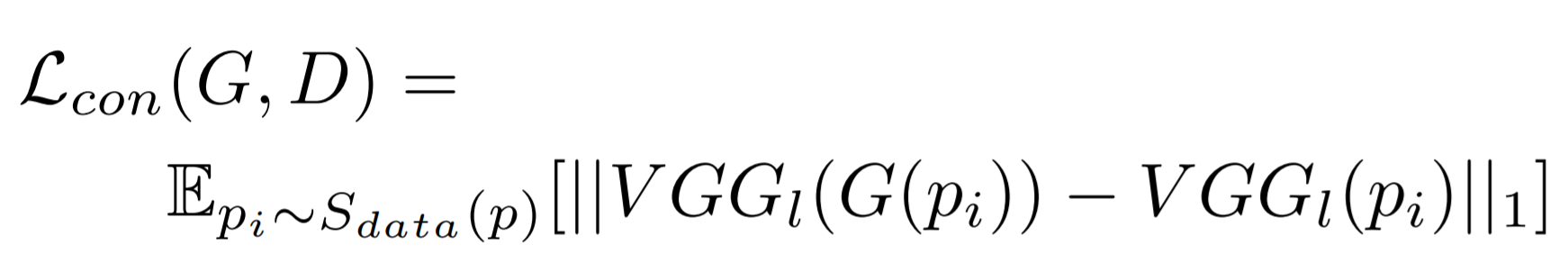
이제 CartoonGAN 의 Loss를 정리하면 다음과 같습니다. 이때 Content Loss의 영향은 hyperparameter ω 로 조절되는데 이 값이 커질수록 사진의 내용이 잘 유지됩니다. 해당 논문에서는 가장 적절한 값 10을 사용했습니다.
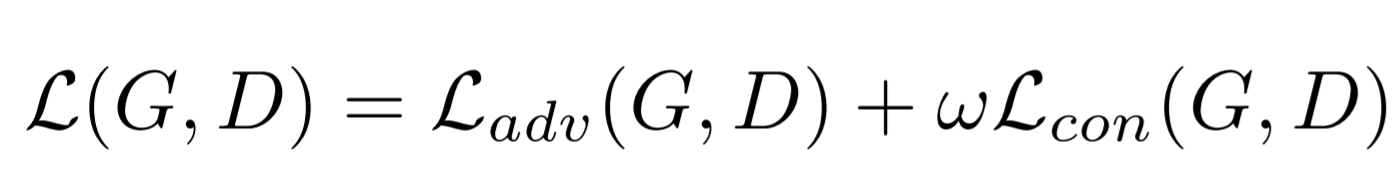
GAN모델의 불안정성과 수렴 문제를 개선하기 위해 CartoonGAN 에서는 훈련 전 initialization phase를 도입했습니다. Initialization phase에서는 Generator를 Content Loss만을 사용하여 10 epoch 동안 훈련시킵니다. 이 과정을 진행하지 않을 경우 CartoonGAN 은 모델이 수렴하지 않아 이미지를 재생성 못하는 문제가 발생합니다.
CartoonGAN: 결과
이제 마지막으로 CartoonGAN 의 성능을 알아보겠습니다. 논문에서는 CartoonGAN 과 CycleGAN 의 비교를 진행하였습니다. 이때 CycleGAN 은 사진의 색감을 보존해주는 Identity Loss가 추가된 경우와 그렇지 않은 경우 두 가지를 훈련했고 모든 비교 모델은 200 epoch씩 훈련했습니다. 결과는 다음과 같습니다.

그림 6.(a) CycleGAN (without L identity)의 결과는 input 사진의 색감을 유지하지 못했습니다. 그림 6.(b) CycleGAN (with L identity)의 경우 색감은 유지되었으나 카툰스타일화의 성능이 좋지 못합니다. CartoonGAN 은 사용된 작가 개인의 스타일을 높은 수준으로 카툰화하여 이미지를 재생성합니다.


CycleGAN 과 CaroonGAN 모델 모두 훈련에 unpair 데이터셋을 사용하였지만 CycleGAN은 2개의 GAN 모델을 학습하여 하나의 모델을 학습하는 CartoonGAN 에 비해 각 epoch당 약 2배의 훈련시간이 소요되었습니다. 카툰의 아주 중요한 특징인 가장자리 선의 재생성 또한 CartoonGAN 이 훨씬 더 잘 나타냈음이 보입니다. 결과적으로 논문에서는 카툰겐이 효율적으로 cartoon stylization를 이루었다고 제안합니다.
3. CycleGAN과 CartoonGAN 구현 및 학습
CycleGAN 과 CartoonGAN 을 비교하기 위해 PyTorch를 사용하여 두 아키텍처를 직접 구현하고 학습시켰습니다. PyTorch 구현은 DIYA 동아리 저장소를 참고해주세요.
CycleGAN 과 CartoonGAN 의 학습에는 Flickr에서 직접 크롤링한 사진 이미지 약 6,000장 (학습 5,000장, 테스트 1,000장)과 신카이 마코토 감독의 애니메이션에서 추출한 이미지 약 4,000장을 사용하였습니다. 모든 모델은 100 epoch동안 learning rate 0.0002로 학습했습니다.
학습은 KC-ML2의 지원으로 아마존 AWS p3.2xlarge 인스턴스에서 진행했습니다.
4. CartoonGAN의 성능 검증
설문조사
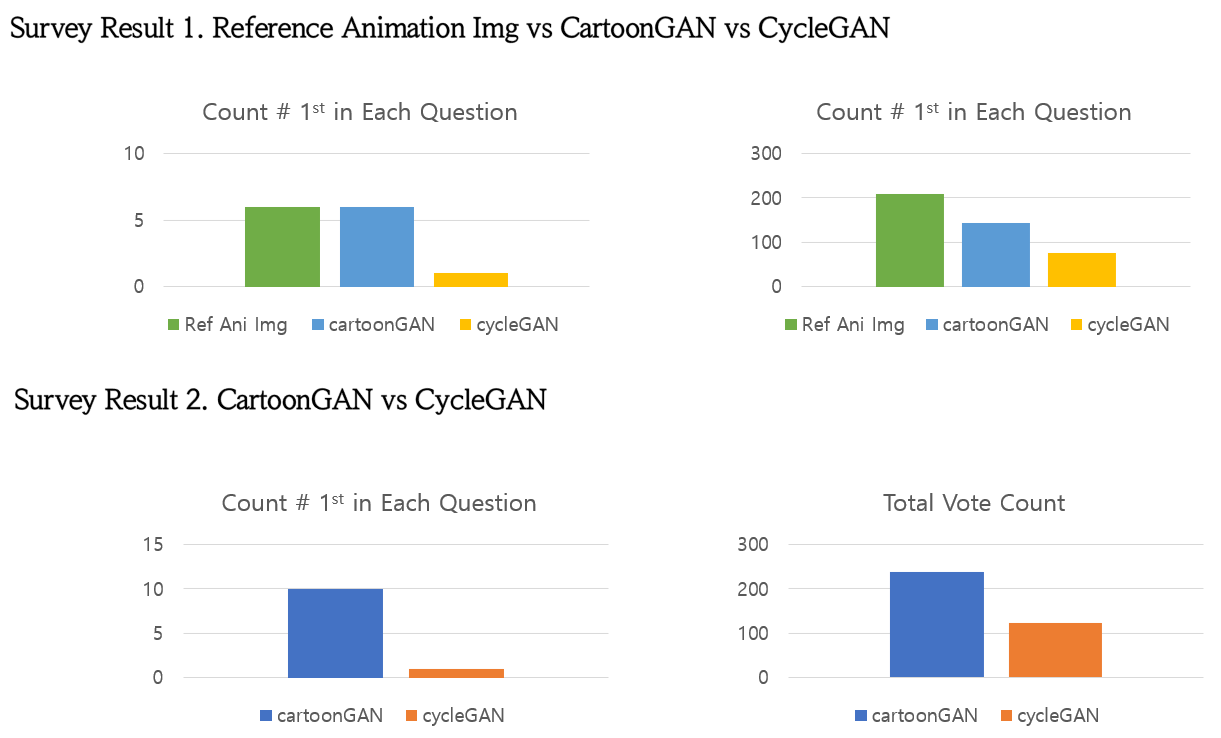
과연 CartoonGAN 은 Cartoon stylization에서 어느 정도의 성과를 보인다고 할 수 있을까요? GAN을 통한 이미지 생성 연구에서 어려운 점 중에 하나는 생성된 이미지를 객관적으로 평가하는 것이 어렵다는 점입니다. 생성된 이미지를 한 장씩 확인하는 방법이 있으나 이는 객관성이 떨어지므로 우리는 CartoonGAN 의 성능을 검증해볼 수 있는 설문조사를 수행했습니다. 설문은 실제 애니메이션 이미지와 CartoonGAN, CycleGAN 이 생성한 이미지 총 세가지 선택지 중 레퍼런스 애니메이션 이미지와 가장 유사한 스타일의 사진을 고르는 24개의 문항으로 구성되었고, 38명이 참여하였습니다. 아래 결과에 따르면 CartoonGAN이 생성한 이미지가 CycleGAN이 생성한 이미지에 비해 훨씬 실제 애니메이션과 더 유사하다는 점을 확인할 수 있습니다.
FID 측정
설문조사 방법은 생성된 이미지의 일부에 대해서만 평가가 가능합니다. 이 때문에 보다 정량적인 평가 방법으로 알려져 있는 FID (Frechet Inception Distance) 6 를 추가로 측정했습니다. Frechet Distance는 주어진 multivariate gaussian distribution이 얼마나 차이가 있는지 측정하는 지표입니다. FID는 Inception network를 통해서 이미지들의 feature vector를 추출하고 이 feature vector들을 이용하여 real data(x)와 generated data(g)의 multivariate gaussian distribution의 평균과 공분산행렬을 각각 추정하여 두 분포의 차이를 계산합니다. 즉, FID의 경우 낮을수록 두 이미지의 분포가 유사하다는 의미로 판단할 수 있습니다.
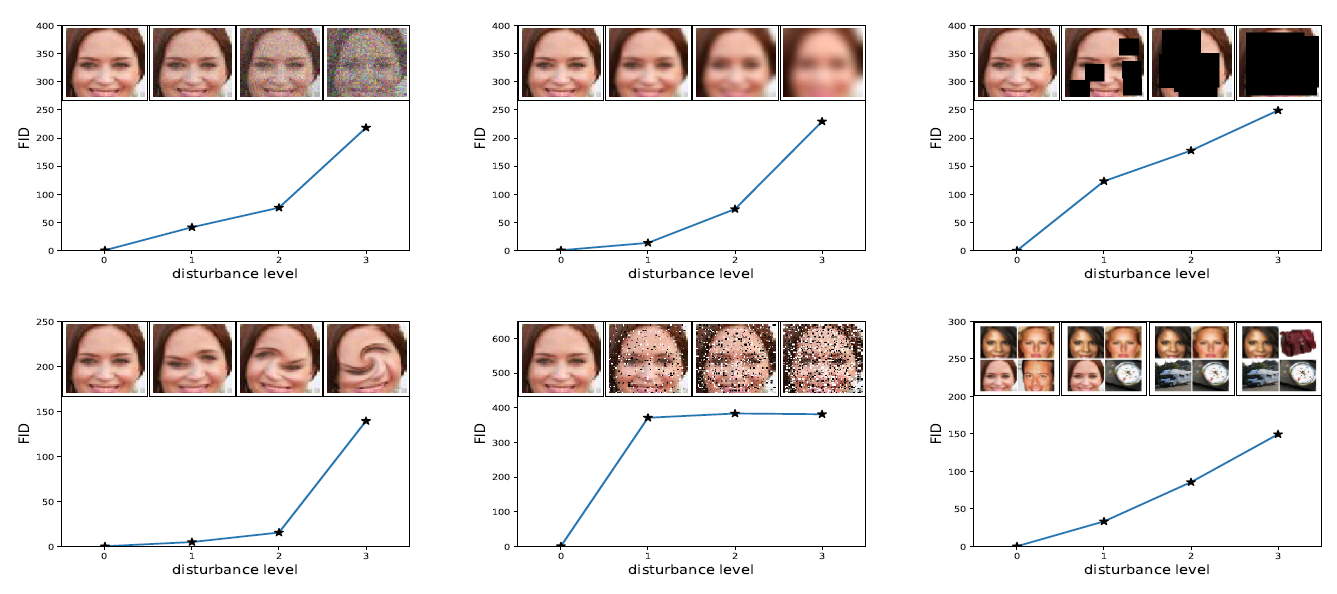
FID를 적용한 실험에서 이미지에 노이즈(noise)나 블러(blur)등을 추가했을 때 FID 값이 증가하는 양상이 나타남을 보였습니다. 즉, FID가 사람이 이미지를 판단하는 것과 유사하다는 것을 보여줍니다. FID 측정은 CartoonGAN 과 CycleGAN 이 각각 생성한 이미지와 실제 애니메이션 이미지의 비교로 이뤄졌고, 결과는 CartoonGAN 이 생성한 이미지와 실제 애니메이션 이미지와의 FID가 가장 낮았습니다.

CycleGAN 에 CartoonGAN technique을 적용한 추가실험
그렇다면 CartoonGAN 의 어떠한 technique이 실제 이미지 생성의 성능을 높였을까요? 이를 확인해보기 위해서 CartoonGAN의 edge-smoothing이 포함된 Adversarial Loss와 initialization phase를 각각 CycleGAN 에 추가해보았습니다. CartoonGAN, CycleGAN, 그리고 두가지의 조건을 각각 추가한 CycleGAN 으로 이미지를 생성하고 FID를 계산해본 결과는 아래와 같습니다.

Initialization phase를 추가한 것이 기존의 CycleGAN FID를 감소시키는데 약간의 영향이 있었지만 Adversarial Loss에 edge-smoothing 부분을 추가한 것은 큰 영향이 없는 것을 알 수 있었습니다. Initialization의 경우에는 모델이 일반적으로 안정적으로 학습되는데 영향을 주지만 아키텍처 자체가 가진 성능을 크게 끌어 올려지는 못한다는 것을 생각해볼 수 있었습니다.
5. CartoonGAN 개선하기
CartoonGAN 과 CycleGAN 의 성능을 비교하는데 그치지 않고 저희는 CartoonGAN 을 더 발전시키고자 했습니다. Normalization, activation, feature extractor, 그리고 GAN objective 총 4가지 부분을 개선했습니다.
(1) Batch Normalization → Instance Normalization
CartoonGAN 에서 사용한 Batch Normalization은 style transfer task에서 content image contrast에 대한 dependency가 발생한다는 문제점이 있습니다. 이로 인해 content image의 contrast를 변경할 경우 전혀 다른 스타일의 이미지가 생성되는 것을 아래 그림에서 확인할 수 있습니다.

이를 해결하기 위해 제안된 방법이 Instance Normalization 7 입니다. Instance Normalization은 single instance에 대해 normalization을 진행하는 것입니다.
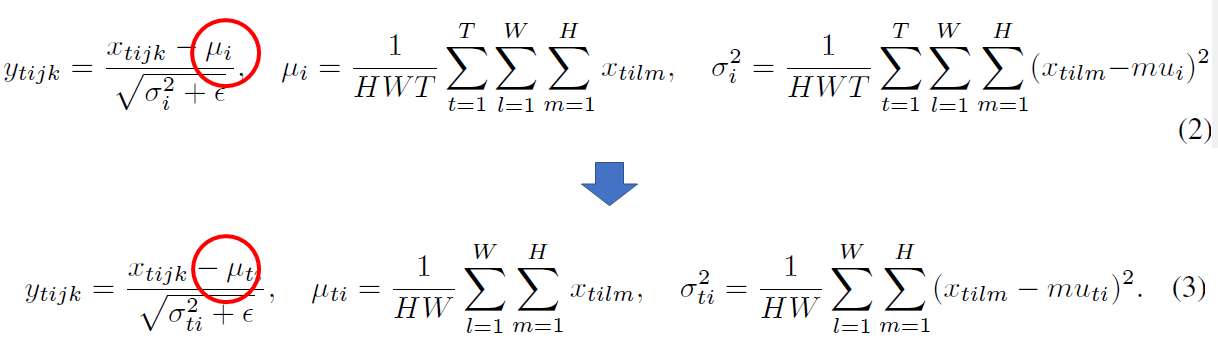

본 연구에서는 CartoonGAN에서 사용한 Batch Normalization을 Instance Normalization으로 변경 시 이미지의 contrast에 영향을 덜 받아 성능 향상이 가능할거라 판단하고 이를 적용했습니다.
(2) ReLU → LeakyReLU
DCGAN, WGAN 등의 저자로 유명한 Soumith Chintala의 조언에 따라 Discriminator 뿐만 아니라 Generator에서도 ReLU 대신 LeakyReLU를 사용했습니다. ReLU 대신 LeakyReLU를 사용하여 학습시 stability가 향상될 것으로 기대했습니다.
(3) VGG → ResNet
CartoonGAN의 Content Loss에서 이미지의 feature vector를 추출하기 위해 CartoonGAN 논문에서 사용한 VGG 대신 ResNet을 사용했습니다. Content Loss에서는 이미지의 feature vector를 잘 추출하는것이 매우 중요한데 object detection 등의 task에서 feature extractor로 더 좋은 성능을 보이는 ResNet을 사용하면 성능이 향상될 것으로 기대했습니다.
(4) GAN → LSGAN
Adversarial Loss에서 일반적인 GAN objective 대신 Least Squares Generative Adversarial Networks (LSGAN)9 objective를 사용했습니다. 일반적인 GAN objective보다 LSGAN 사용시 더 효율적으로 학습될 것을 기대했습니다.
CartoonGAN 개선 결과
위에서 설명한 technique들을 적용해 CartoonGAN 을 조금 더 개선했습니다. 기존 CartoonGAN 모델과의 개선된 모델의 결과들을 비교하며 글을 마무리하겠습니다.




References
1Generative Adversarial Networks, Goodfellow et al, arXiv:1406.2661
2Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, Radford et al, arXiv:1511.06434
3Image-to-Image Translation with Conditional Adversarial Networks, Isola et al, arXiv:1611.07004
4Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, Zhu et al, arXiv:1703.10593
5CartoonGAN: Generative Adversarial Networks for Photo Cartoonization, Chen et al, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018
6GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium, Heusel et al, arXiv:1706.08500
7Instance normalization: The missing ingredient for fast stylization, Ulyanov et al, arXiv:1607.08022
8Speed/accuracy trade-offs for modern convolutional object detectors, Huang et al, arXiv:1611.10012
9Least squares generative adversarial networks, Mao et al, arXiv:1611.04076
Written by 문지환 | 박수현 | 윤준석 | 주윤하
[출처] https://blog.diyaml.com/teampost/Improving-CartoonGAN/
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.