
php로 빅데이터 다루기 : BIG DATA IN PHP
2017.08.03 22:57
php로 빅데이터 다루기 : BIG DATA IN PHP
BIG DATA IN PHP
30 April 2015 7 minutes
“Big data” is a term for a collection of data that is too large and complex to process with traditional tools and techniques. One of the techniques that is capable of processing large amount of data is called MapReduce.
When to use MapReduce ?
MapReduce is particularly suited for problems that involves a lot of data. It works by splitting the work into smaller chunks which then can be processed by multiple systems. As a MapReduce system works in parallel on a single problem, a solution may come a lot quicker in comparison with a traditional system.
Some use cases are for example:
- Counting and summing
- Collating
- Filtering
- Sorting
Apache hadoop
For this article we will be using Apache Hadoop. Hadoop is free, open source and the de facto standard when you want to develop a MapReduce solution. It is even possible to rent a Hadoop cluster online at providers such as Amazon, Google or Microsoft.
Other strong points are:
- Scalable: new processing nodes can easily be added without changing one line of code
- Cost effective: you don’t need any specialized hardware as the software runs fine on commodity hardware.
- Flexible: as it is schema-less it can process any data structure. You can even combine multiple data sources without a lot of problems.
- Fault tolerant: if you lose a node, the processing can continue and other nodes will pick up the extra workload.
It also supports a utility called “streaming“, which gives the user a lot of freedom in choosing the programming language for developing mapper and reducer scripts. We will be using PHP for now.
KISS
The installation and configuration of Apache Hadoop is out of the scope of this article. You can easily find numerous articles online describing the process for your platform of choice. To keep it simple I will only focus on the practical use of the map and reduce step.
The mapper
The task of the mapper is to transform input to a series of key and value pairs. For example in the case of a word counter the input are a series of lines. We split them up in words and transform them into pairs (key: word, value: 1) that could look like this:
PHP
the 1
water 1
on 1
on 1
water 1
on 1
... 1
In turn these pairs are then sent to the reducer for the next step.
The reducer
The task of the reducer is to retrieve the (sorted) pairs, iterate and transform them to the desired output. In the example of the word counter, taking the word count (value) and sum them to get a single word (key) and its final count:
PHP
water 2
the 1
on 3
In a simplistic diagram the whole process of mapping and reducing would look a bit like this
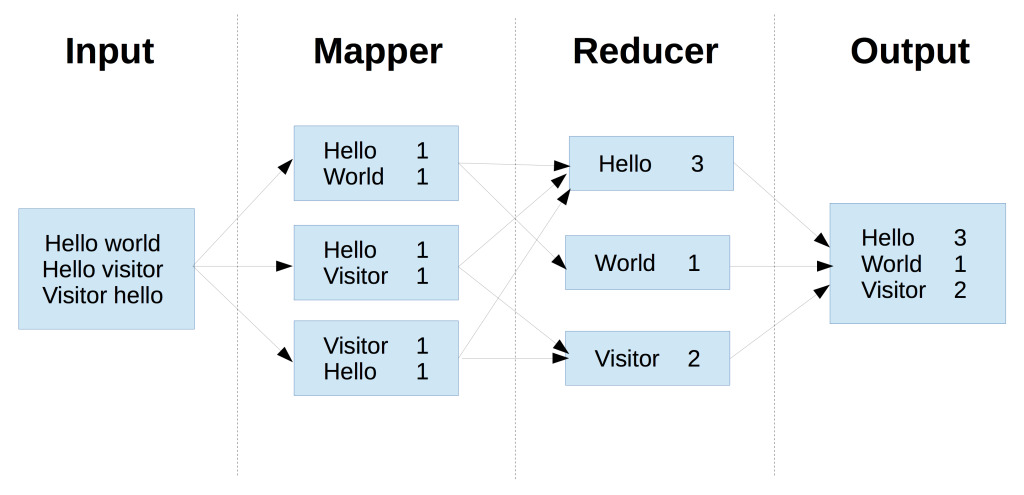
The word counter in PHP
We will start off with the “hello world” example of the MapReduce world and that is the implementation of a simple word counter. We will need some data to work on and for that we will use the public domain book Moby Dick.
Download the book by executing following command
C-like
wget http://www.gutenberg.org/cache/epub/2701/pg2701.txt
Create a working directory in the HDFS (Hadoop Distributed File System)
C-like
hadoop dfs -mkdir wordcount
Copy the book that you have downloaded to the HDFS
C-like
hadoop dfs -copyFromLocal ./pg2701.txt wordcount/mobydick.txt
Now for some code and that starting with the mapper
PHP
#!/usr/bin/php
<?php
// iterate through lines
while($line = fgets(STDIN)){
// remove leading and trailing
$line = ltrim($line);
$line = rtrim($line);
// split the line in words
$words = preg_split('/\s/', $line, -1, PREG_SPLIT_NO_EMPTY);
// iterate through words
foreach( $words as $key ) {
// print word (key) to standard output
// the output will be used in the
// reduce (reducer.php) step
// word (key) tab-delimited wordcount (1)
printf("%s\t%d\n", $key, 1);
}
}
?>
And the reducer code.
PHP
#!/usr/bin/php
<?php
$last_key = NULL;
$running_total = 0;
// iterate through lines
while($line = fgets(STDIN)) {
// remove leading and trailing
$line = ltrim($line);
$line = rtrim($line);
// split line into key and count
list($key,$count) = explode("\t", $line);
// this if else structure works because
// hadoop sorts the mapper output by it keys
// before sending it to the reducer
// if the last key retrieved is the same
// as the current key that have been received
if ($last_key === $key) {
// increase running total of the key
$running_total += $count;
} else {
if ($last_key != NULL)
// output previous key and its running total
printf("%s\t%d\n", $last_key, $running_total);
// reset last key and running total
// by assigning the new key and its value
$last_key = $key;
$running_total = $count;
}
}
?>
You can easily test the script locally by using a combination of certain commands and pipes.
C-like
head -n1000 pg2701.txt | ./mapper.php | sort | ./reducer.php
To eventually run it on an Apache Hadoop cluster
C-like


hadoop jar /usr/hadoop/2.5.1/libexec/lib/hadoop-streaming-2.5.1.jar \
-mapper "./mapper.php"
-reducer "./reducer.php"
-input "hello/mobydick.txt"
-output "hello/result"
The output will be stored in the folder hello/result and can be viewed by executing following command
C-like
hdfs dfs -cat hello/result/part-00000
Calculating the average yearly gold price
The next example is a more real-life example and although the dataset is relatively small, the same logic can easily be applied on a set with a milion data-points. We will try to calculate the average yearly gold price and that for the past 50 years.
Download the dataset
C-like
wget https://raw.githubusercontent.com/datasets/gold-prices/master/data/data.csv
Create a working directory in the HDFS (Hadoop Distributed File System)
C-like
hadoop dfs -mkdir goldprice
Copy the dataset that you have downloaded to the HDFS
C-like
hadoop dfs -copyFromLocal ./data.csv goldprice/data.csv
My reducer looks like this
PHP
#!/usr/bin/php
<?php
// iterate through lines
while($line = fgets(STDIN)){
// remove leading and trailing
$line = ltrim($line);
$line = rtrim($line);
// regular expression to capture year and gold value
preg_match("/^(.*?)\-(?:.*),(.*)$/", $line, $matches);
if ($matches) {
// key: year, value: gold price
printf("%s\t%.3f\n", $matches[1], $matches[2]);
}
}
?>
The reducer is also slightly modified as we need to keep tabs on the number of items and running average.
PHP
#!/usr/bin/php
<?php
$last_key = NULL;
$running_total = 0;
$running_average = 0;
$number_of_items = 0;
// iterate through lines
while($line = fgets(STDIN)) {
// remove leading and trailing
$line = ltrim($line);
$line = rtrim($line);
// split line into key and count
list($key,$count) = explode("\t", $line);
// if the last key retrieved is the same
// as the current key that have been received
if ($last_key === $key) {
// increase number of items
$number_of_items++;
// increase running total of the key
$running_total += $count;
// (re)calculate average for that key
$running_average = $running_total / $number_of_items;
} else {
if ($last_key != NULL)
// output previous key and its running average
printf("%s\t%.4f\n", $last_key, $running_average);
// reset key, running total, running average
// and number of items
$last_key = $key;
$number_of_items = 1;
$running_total = $count;
$running_average = $count;
}
}
if ($last_key != NULL)
// output previous key and its running average
printf("%s\t%.3f\n", $last_key, $running_average);
?>
Like in the word count example you can also test it locally
C-like
head -n1000 data.csv | ./mapper.php | sort | ./reducer.php
To eventually run it on the hadoop cluster
C-like
hadoop jar /usr/hadoop/2.5.1/libexec/lib/hadoop-streaming-2.5.1.jar \
-mapper "./mapper.php"
-reducer "./reducer.php"
-input "goldprice/data.csv"
-output "goldprice/result"
To view the averages
C-like
hdfs dfs -cat goldprice/result/part-00000
Bonus: generating a chart
We will often want to convert the results to a chart. For this demonstration I’m going to use gnuplot, but you can use anything that tickles your fancy.
First get the result back locally
C-like
hdfs dfs -get goldprice/result/part-00000 gold.dat
Create a gnu plot configuration file (gold.plot) and copy the following content
C-like
# Gnuplot script file for generating gold prices
set terminal png
set output "chart.jpg"
set style data lines
set nokey
set grid
set title "Gold prices"
set xlabel "Year"
set ylabel "Price"
plot "gold.dat"
Generate the chart
C-like
gnuplot gold.plot
This generates a file called chart.jpg and would look like this
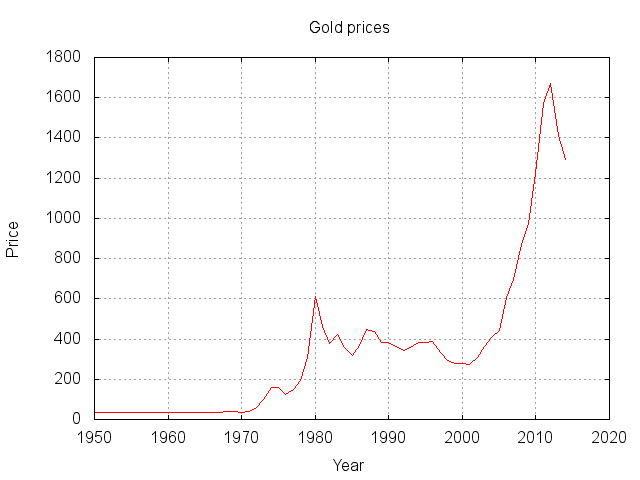
[출처] https://www.simplicity.be/article/big-data-php/
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.