
- 전체
- Sample DB
- database modeling
- [표준 SQL] Standard SQL
- G-SQL
- 10-Min
- ORACLE
- MS SQLserver
- MySQL
- SQLite
- postgreSQL
- 데이터아키텍처전문가 - 국가공인자격
- 데이터 분석 전문가 [ADP]
- [국가공인] SQL 개발자/전문가
- NoSQL
- hadoop
- hadoop eco system
- big data (빅데이터)
- stat(통계) R 언어
- XML DB & XQuery
- spark
- DataBase Tool
- 데이터분석 & 데이터사이언스
- Engineer Quality Management
- [기계학습] machine learning
- 데이터 수집 및 전처리
- 국가기술자격 빅데이터분석기사
- 암호화폐 (비트코인, cryptocurrency, bitcoin)
stat(통계) R 언어 R로 하는 텍스트마이닝(2016_08_15 대통령 광복절 기념사 분석)
2018.03.17 23:14
|
R로 하는 텍스트마이닝(2016_08_15 대통령 광복절 기념사 분석)
|

제이콥입니다.
얼마 전 대한민국 최대 기념일 8월 15일 '광복절'이었죠. 모두 집에 태극기 달으셨나요? :)
역사 공부를 할때마다 대한민국이 주변 강대국에게 당하면서 살았던 것이 항상 분했었는데요.
지금 이렇게 강대국이 되었다는 것에 대해 너무나 기쁘고 가슴이 벅차오릅니다.
그리고 8월 15일, 광복절에 박근혜 대통령이 광복절 기념사를 하셨는데요.
제가 정치에 대해서 잘 알지는 못하나, 역사적인 날을 기념하는 큰 공식적인 자리에서
팩트를 잘못 연설하신 것에 대해선 좋은 기념사는 아니었다고 말하고 싶네요^^;
말이 길어졌네요.
오늘은 박근혜 대통령의 광복절 기념사를 텍스트마이닝 해보려고 하는데요.
텍스트마이닝의 의미는 무엇을 의미하는걸까요?
텍스트 마이닝(text mining)이란 대규모의 문서(text)에서 의미 있는 정보를 추출하는 것을 말한다.
(NAVER 지식백과)
텍스트 마이닝은 분석 분석 대상이 형태가 일정하지 않고 다루기 힘든 비정형 데이터이므로
인간의 언어를 컴퓨터가 인식해 처리하는 자연어 처리 방법과 관련이 깊다고 하는데요.
간단하게 말씀드리면, 저는 마케팅에 관심이 많습니다.
그래서 지인들과 업무 또는 그에 관련된 얘기를 할 때마다 마케팅에 관한 이야기를 많이하게 되죠.
그리고 제가 했던 말들을 분석하면 '마케팅'이란 단어 또는 그에 관련된 단어를 많이 사용했을 것입니다.
단어 빈도수는 간접적으로 제가 마케팅에 관심있다는 것을 알 수 있게 해주는 척도라고 할 수 있죠.
참으로 신통방통한 기법입니다. 마케팅하는 사람들에겐 VOC수집하고 분석하면 큰 도움이 되겠네요 :)
네이버 블로그에도 빅데이터 기술이 적용되는 것을 볼 수 있었죠.
그럼 지금부터 텍스트마이닝 하는 방법에 대해 알아보도록 하겠습니다.
(박근혜 대통령 광복절 기념사는 파일첨부 해놓았습니다. 다운받아서 실습해보세요.)

텍스트 마이닝을 실행하기 위한 패키지를 우선 설치하셔야 하는데요.
KoNLP, data.table, plyr, RColorBrewer, wordcloud 총 5개 패키지를 사용합니다. 패키지를 모두 설치해주세요:)
1. 파일 불러오기(.txt)
'2016_박근혜 대통령 광복절 기념사'파일을 readLines함수로 불러옵니다.
![]()
txt에 제대로 담겨졌는데 확인해보세요:)
2. 단어 추출 및 데이터 구조 변경
txt파일의 단어를 추출해보도록 하겠습니다.
![]()
txt2를 확인해보시면 아래와 같이 단어가 추출된 것을 보실 수 있습니다.

txt 파일에서 단어를 추출하면서 데이터 구조가 character에서 list로 변환되었습니다.
이 구조를 다시 character로 바꿔주기 위해 다시 한번 함수를 사용합니다.
![]()
한 번 확인해볼까요?
![]()
![]()


자, character로 변환이 되었네요.
3. 두 단어 이하 제외
두 단어 이하로 된 단어를 제외하려고 합니다.
이때는 Filter 함수를 사용합니다.
![]()
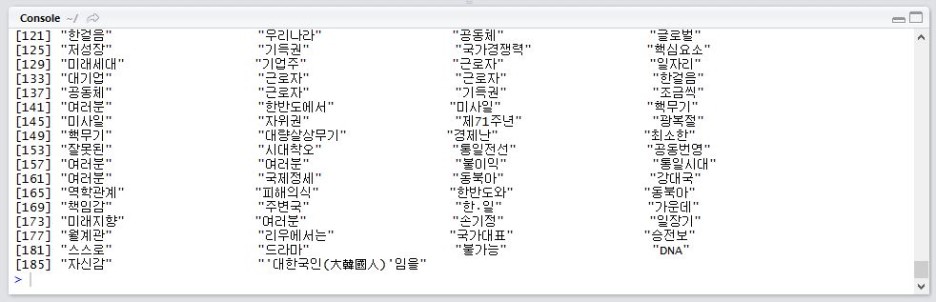
두 단어 이하로 이루어진 단어를 모두 제외시켰습니다.
4. 데이터 테이블로 변형
단어 형태를 바꾸기 위해 데이터 테이블로 만들어줍니다.
![]()
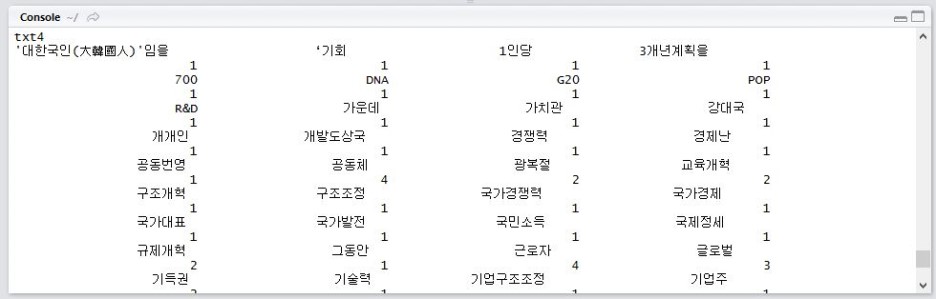
그리고 빈도수를 세어보도록 합시다.
![]()
그리고 확인!
5. 색 지정
출력 될 wordcloud 단어색을 지정해주는 단계입니다.
![]()
6. wordcloud 출력
아래 코드를 따라 입력해줍니다.
wordcloud(names(wordcount), freq=wordcount, scale=c(3,0.3), rot.per=0.25, min.freq=1,random.order=F, random.color=T, colors=ccolour)
(퍼가기하시면 블라인드처리 된 코드를 보실 수 있습니다.)

위와 같은 결과가 나왔습니다.
하지만 부분부분 제외하고 싶은 단어가 보입니다. 마지막으로 제외하고 싶은 단어를 제외합니다.
7. 단어 제외
txt3 <- gsub("\d+","", txt3)
txt3 <- gsub("\n","", txt3)
txt3 <- gsub("[A-z]", "", txt3)
txt3 <- gsub("[[:cntrl:]]", "", txt3)
첫 번째는 날짜를 제외하는 것을 의미하며, 두 번째는 new line 문자 없애는 것을 의미합니다.
또한 세 번째는 영문 제거이며, 마지막으로 네번째는 특수문자 제거입니다.
이외에도 제외하고 싶은 단어는 제외해줍니다.

다시 한번 입력해 준 코드를 실행해주면, 이런 예쁜 그림이 나오게 되죠.
2016년 광복절 기념사에는 "여러분"이란 단어와 "신산업","자신감","규제개혁","교육개혁","공동체"등의 단어가 눈에 많이 띄네요.
박근혜 대통령은 이런 분야에 관심이 많다고 할 수 있겠습니다.
확인해본 결과 빈도수는 이러합니다.
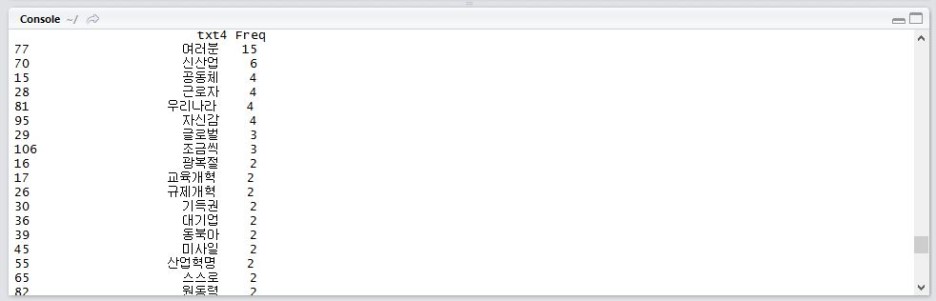
여러분이라는 단어를 15번이나 말씀하셨네요.
이 뿐만 아니라 텍스트 마이닝 기법을 사업 또는 마케팅에 대입하면 더 좋은 인사이트를 뽑을 수 있겠죠?
수고하셨습니다:)

광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.