
- 전체
- Sample DB
- database modeling
- [표준 SQL] Standard SQL
- G-SQL
- 10-Min
- ORACLE
- MS SQLserver
- MySQL
- SQLite
- postgreSQL
- 데이터아키텍처전문가 - 국가공인자격
- 데이터 분석 전문가 [ADP]
- [국가공인] SQL 개발자/전문가
- NoSQL
- hadoop
- hadoop eco system
- big data (빅데이터)
- stat(통계) R 언어
- XML DB & XQuery
- spark
- DataBase Tool
- 데이터분석 & 데이터사이언스
- Engineer Quality Management
- [기계학습] machine learning
- 데이터 수집 및 전처리
- 국가기술자격 빅데이터분석기사
- 암호화폐 (비트코인, cryptocurrency, bitcoin)
MySQL [Mysql] mysql에서 json 다루기
2022.08.02 11:16
[Mysql] mysql에서 json 다루기
0. 들어가기
-. 카드 실적에 대한 비정형 데이터 처리를 하다보니.. 만만한게 json이더라.
-. mysql에 json column 만들어 놓고 데이터 넣고빼고 해보자.
1. mysql 테이블 생성
-. 테이블부터 차근차근
CREATE SCHEMA `testschema`;
CREATE TABLE `testschema`.`jsontable` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(45) NULL,
`jsoncol` JSON NULL,
PRIMARY KEY (`id`));
0. 들어가기
-. 카드 실적에 대한 비정형 데이터 처리를 하다보니.. 만만한게 json이더라.
-. mysql에 json column 만들어 놓고 데이터 넣고빼고 해보자.
1. mysql 테이블 생성
-. 테이블부터 차근차근
CREATE SCHEMA `testschema`;
CREATE TABLE `testschema`.`jsontable` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(45) NULL,
`jsoncol` JSON NULL,
PRIMARY KEY (`id`));
2. json 입력
1) 가장 기본적으로, sql 쿼리 쓰듯이, string 입력을 할 수 있다.
INSERT INTO `testschema`.`jsontable`(`name`, `jsoncol`) VALUES ("json_string", '{"a": "A", "b":"B"}');
2) json_object 형식으로 key, value 순서쌍으로도 입력 가능함.
INSERT INTO `testschema`.`jsontable`(`name`, `jsoncol`) VALUES ("json_object", json_object("a", "A", "b", "B"));
3) error) json 내 항목을 배열 (list)로 입력할 땐 바로 할 수 없다.
INSERT INTO `testschema`.`jsontable`(`name`, `jsoncol`) VALUES ("json_object with list", json_object("a", "[1,2,3]", "b", "B"));
4) json_array 형식을 사용해야함.
INSERT INTO `testschema`.`jsontable`(`name`, `jsoncol`) VALUES ("json_object with json_array", json_object("a", JSON_ARRAY(1,2,3), "b", "B"));
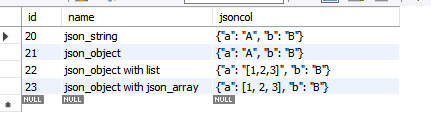
5) 정리하자면 이렇게
INSERT INTO `testschema`.`jsontable`(`name`, `jsoncol`) VALUES ("json_string", '{"a": "A", "b":"B"}');
INSERT INTO `testschema`.`jsontable`(`name`, `jsoncol`) VALUES ("json_object", json_object("a", "A", "b", "B"));
INSERT INTO `testschema`.`jsontable`(`name`, `jsoncol`) VALUES ("json_object with list", json_object("a", "[1,2,3]", "b", "B"));
INSERT INTO `testschema`.`jsontable`(`name`, `jsoncol`) VALUES ("json_object with json_array", json_object("a", JSON_ARRAY(1,2,3), "b", "B"));
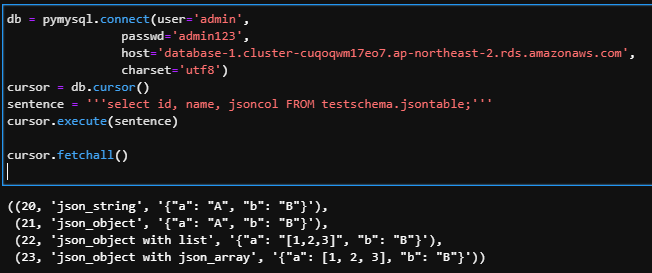
3. json 데이터 읽기
1) 일반적인 쿼리 구문으로 불러오기
select id, name, jsoncol FROM testschema.jsontable;
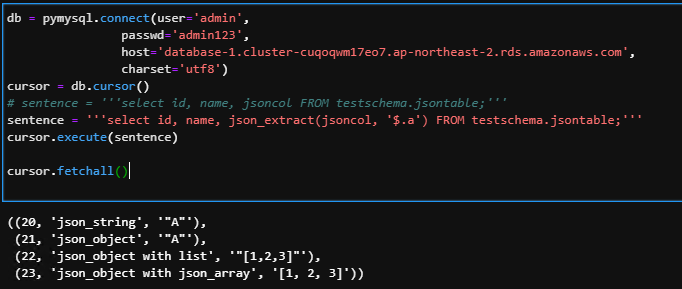
2) 특정 키값만 불러오기


select id, name, json_extract(jsoncol, '$.a') FROM testschema.jsontable;
3) json return 값에 따옴표(") 없애기
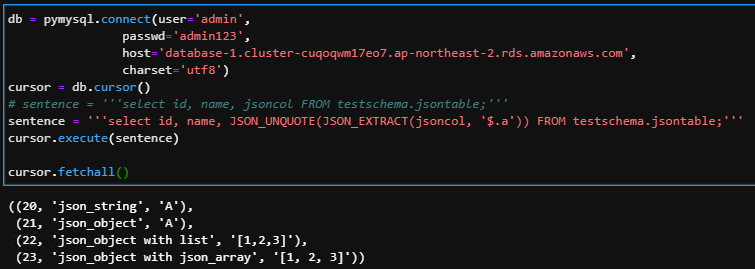
-. 위를 보면 따옴표가 중복으로 ('"A"') 형태로 나온다. json_unquote 구문을 추가해주면 이를 해결 가능함.
select id, name, JSON_UNQUOTE(JSON_EXTRACT(jsoncol, '$.a')) FROM testschema.jsontable;
4) 조건식 (WHERE) 사용
select id, name, json_extract(jsoncol, '$.a') FROM testschema.jsontable WHERE json_extract(jsoncol, '$.a') = "A";
4. json 데이터 변경
-. json_replace 사용법
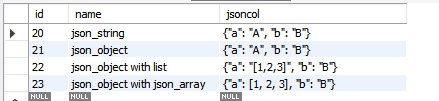
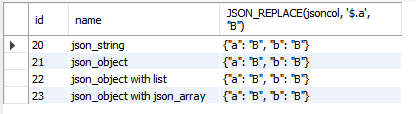
1) json data의 'a' key 데이터 를 전부 'B' 로 바꿔서 불러옴
※ DB의 원본 데이터는 변하지 않음
select id, name, JSON_REPLACE(jsoncol, '$.a', "B") FROM testschema.jsontable;
2) json 데이터 수정
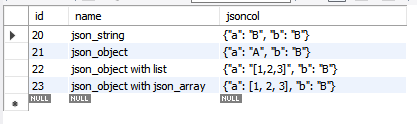
-. UPDATE 테이블명 SET 컬럼명 = new 데이터
UPDATE testschema.jsontable SET jsoncol = JSON_REPLACE(jsoncol, '$.a', "B") WHERE id = 20;
5. 기타
1) json depth
SELECT JSON_DEPTH(jsoncol) FROM testschema.jsontable;

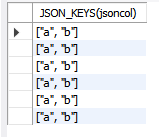
2) json keys
-. 들어있는 키를 반환 (depth 1만)
SELECT JSON_KEYS(jsoncol) FROM testschema.jsontable;
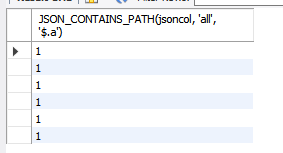
3) json path
-. 특정 키의 유무 확인 (마찬가지로 depth 1만되더라)
SELECT JSON_CONTAINS_PATH(jsoncol, 'all', '$.a') FROM testschema.jsontable;
[출처] https://givemethesocks.tistory.com/75
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.