
[ 一日30分 인생승리의 학습법] [Elasticsearch] 기본 개념잡기
2022.06.02 12:59
[ 一日30分 인생승리의 학습법] [Elasticsearch] 기본 개념잡기
1. Elasticsearch란?
Elasticsearch는 Apache Lucene( 아파치 루씬 ) 기반의 Java 오픈소스 분산 검색 엔진입니다.
Elasticsearch를 통해 루씬 라이브러리를 단독으로 사용할 수 있게 되었으며, 방대한 양의 데이터를 신속하게, 거의 실시간( NRT, Near Real Time )으로 저장, 검색, 분석할 수 있습니다.
Elasticsearch는 검색을 위해 단독으로 사용되기도 하며, ELK( Elasticsearch / Logstatsh / Kibana )스택으로 사용되기도 합니다.
ELK 스택이란 다음과 같습니다.
- Logstash
- 다양한 소스( DB, csv파일 등 )의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch로 전달
- Elasticsearch
- Logstash로부터 받은 데이터를 검색 및 집계를 하여 필요한 관심 있는 정보를 획득
- Kibana
- Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링
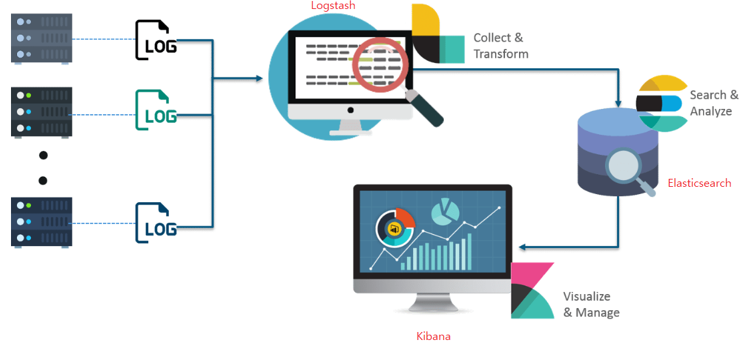
출처 : https://www.edureka.co/blog/elk-stack-tutorial/
이제부터 Elasticsearch와 관련된 용어와 특징들에 대해 알아보겠습니다.
2. Elasticsearch와 관계형 DB 비교
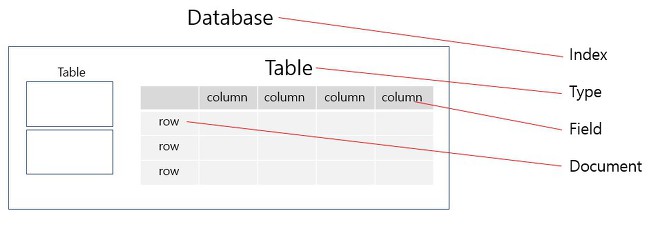
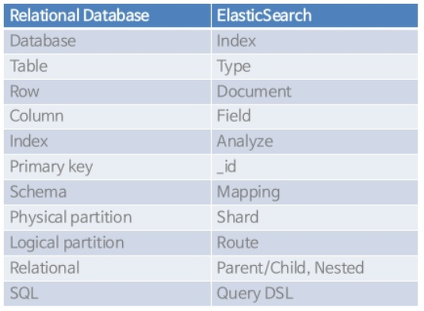
출처: https://www.slideshare.net/deview/2d1elasticsearch
RDBMS를 다루셨던 분들이라면 Elasticsearch에서 사용하는 용어들이 조금 낯설지만 예제를 몇 번 따라해보시면 금방 적응하실 것이라 생각됩니다.
그래도 용어가 낯설기 때문에 다음으로 용어 정리를 해보도록 하겠습니다.
3. Elasticsearch 아키텍쳐 / 용어 정리
Elasticsearch에서 사용하는 대부분의 개념은 RDBMS에도 존재하는 개념들입니다.
아래의 사진은 Elasticsearch Architecture이며, 앞으로 설명할 용어들의 구조입니다.
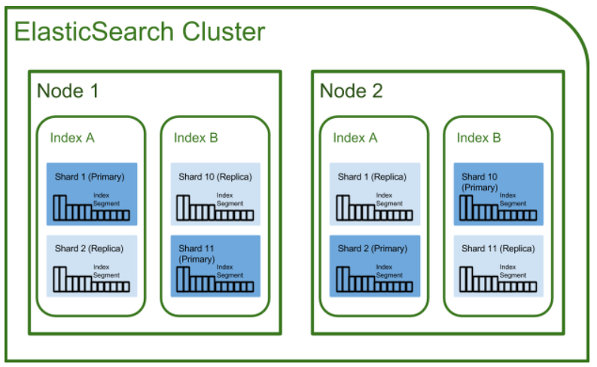
출처 : https://github.com/exo-archives/exo-es-search
1) 클러스터( cluseter )
클러스터란 Elasticsearch에서 가장 큰 시스템 단위를 의미하며, 최소 하나 이상의 노드로 이루어진 노드들의 집합입니다.
서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지되며,
여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재할수도 있습니다.
2) 노드( node )
Elasticsearch를 구성하는 하나의 단위 프로세스를 의미합니다.
그 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분할 수 있습니다.
아래는 각 노드들에 대한 설명인데, 제가 Elasticsearch에 대한 깊이가 없어서 공식 문서의 설명들을 정리만 해보았습니다.
master-eligible node ( 링크 )
클러스터를 제어하는 마스터로 선택할 수 있는 노드를 말합니다.
여기서 master 노드가 하는 역할은 다음과 같습니다.
- 인덱스 생성, 삭제
- 클러스더 노드들의 추적, 관리
- 데이터 입력 시 어느 샤드에 할당할 것인지
Data node ( 링크 )
데이터와 관련된 CRUD 작업과 관련있는 노드입니다.
이 노드는 CPU, 메모리 등 자원을 많이 소모하므로 모니터링이 필요하며, master 노드와 분리되는 것이 좋습니다.
Ingest node ( 링크 )
데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할을 합니다.
Coordination only node ( 링크 )
data node와 master-eligible node의 일을 대신하는 이 노드는 대규모 클러스터에서 큰 이점이 있습니다.
즉 로드밸런서와 비슷한 역할을 한다고 보시면 됩니다.
3) 인덱스( index ) / 샤드( Shard ) / 복제( Replica )
Elasticsearch에서 index는 RDBMS에서 database와 대응하는 개념입니다.
또한 shard와 replica는 Elasticsearch에만 존재하는 개념이 아니라, 분산 데이터베이스 시스템에도 존재하는 개념입니다.
샤딩( sharding )은 데이터를 분산해서 저장하는 방법을 의미합니다.
즉, Elasticsearch에서 스케일 아웃을 위해 index를 여러 shard로 쪼갠 것입니다.
기본적으로 1개가 존재하며, 검색 성능 향상을 위해 클러스터의 샤드 갯수를 조정하는 튜닝을 하기도 합니다.
replica는 또 다른 형태의 shard라고 할 수 있습니다.
노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드들을 복제하는 것이죠.
따라서 replica는 서로 다른 노드에 존재할 것을 권장합니다.
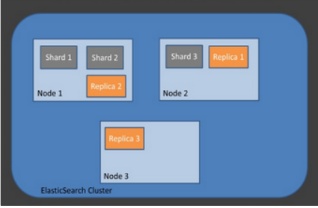
출처 : https://stackoverflow.com/questions/19838825/what-are-elasticsearch-indices#answer-19839840
- Scale out
- 샤드를 통해 규모가 수평적으로 늘어날 수 있음
- 고가용성
- Replica를 통해 데이터의 안정성을 보장
- Schema Free
- Json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없음
- Restful
- 데이터 CURD 작업은 HTTP Restful API를 통해 수행하며, 각각 다음과 같이 대응합니다.
-
Data CRUD
Elasticsearch Restful
SELECT
GET
INSERT
PUT
UPDATE
POST
DELETE
DELETE
- -d 옵션
- 추가할 데이터를 json 포맷으로 전달합니다.
- -H 옵션
- 헤더를 명시합니다. 예제에서는 json으로 전달하기 위해서 application/json으로 작성했습니다.
- ?pretty
- 결과를 예쁘게 보여주도록 요청
이렇게 curl 요청을 하면, victolee 인덱스에, blog 타입으로 id 값이 1인 document가 저장됩니다.
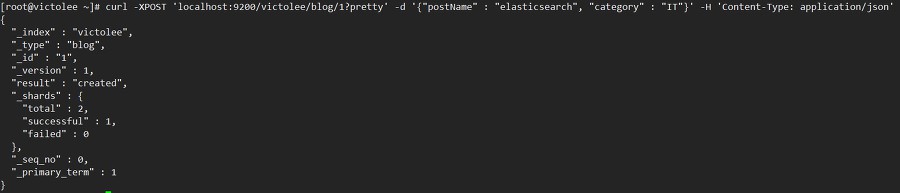
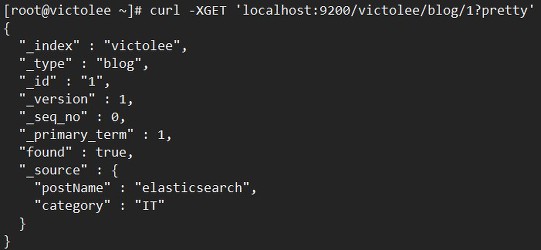


[ Index( 색인 ) - 목차 ] [ Reverted Index( 역색인 ) - 찾아보기 ]
이상으로 Elasticsearch에 대한 개념잡기를 마치도록 하겠습니다.
Elasticsearch를 잘 다루기 위해서는 공식문서의 예제들을 따라해보는 것이 많은 도움이 될 것 같습니다.
1. Elasticsearch란?


Elasticsearch는 Apache Lucene( 아파치 루씬 ) 기반의 Java 오픈소스 분산 검색 엔진입니다.
Elasticsearch를 통해 루씬 라이브러리를 단독으로 사용할 수 있게 되었으며, 방대한 양의 데이터를 신속하게, 거의 실시간( NRT, Near Real Time )으로 저장, 검색, 분석할 수 있습니다.
Elasticsearch는 검색을 위해 단독으로 사용되기도 하며, ELK( Elasticsearch / Logstatsh / Kibana )스택으로 사용되기도 합니다.
ELK 스택이란 다음과 같습니다.
- Logstash
- 다양한 소스( DB, csv파일 등 )의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch로 전달
- Elasticsearch
- Logstash로부터 받은 데이터를 검색 및 집계를 하여 필요한 관심 있는 정보를 획득
- Kibana
- Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링
출처 : https://www.edureka.co/blog/elk-stack-tutorial/
이제부터 Elasticsearch와 관련된 용어와 특징들에 대해 알아보겠습니다.
2. Elasticsearch와 관계형 DB 비교
출처: https://www.slideshare.net/deview/2d1elasticsearch
RDBMS를 다루셨던 분들이라면 Elasticsearch에서 사용하는 용어들이 조금 낯설지만 예제를 몇 번 따라해보시면 금방 적응하실 것이라 생각됩니다.
그래도 용어가 낯설기 때문에 다음으로 용어 정리를 해보도록 하겠습니다.
3. Elasticsearch 아키텍쳐 / 용어 정리
Elasticsearch에서 사용하는 대부분의 개념은 RDBMS에도 존재하는 개념들입니다.
아래의 사진은 Elasticsearch Architecture이며, 앞으로 설명할 용어들의 구조입니다.
출처 : https://github.com/exo-archives/exo-es-search
1) 클러스터( cluseter )
클러스터란 Elasticsearch에서 가장 큰 시스템 단위를 의미하며, 최소 하나 이상의 노드로 이루어진 노드들의 집합입니다.
서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지되며,
여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재할수도 있습니다.
2) 노드( node )
Elasticsearch를 구성하는 하나의 단위 프로세스를 의미합니다.
그 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분할 수 있습니다.
아래는 각 노드들에 대한 설명인데, 제가 Elasticsearch에 대한 깊이가 없어서 공식 문서의 설명들을 정리만 해보았습니다.
master-eligible node ( 링크 )
클러스터를 제어하는 마스터로 선택할 수 있는 노드를 말합니다.
여기서 master 노드가 하는 역할은 다음과 같습니다.
- 인덱스 생성, 삭제
- 클러스더 노드들의 추적, 관리
- 데이터 입력 시 어느 샤드에 할당할 것인지
Data node ( 링크 )
데이터와 관련된 CRUD 작업과 관련있는 노드입니다.
이 노드는 CPU, 메모리 등 자원을 많이 소모하므로 모니터링이 필요하며, master 노드와 분리되는 것이 좋습니다.
Ingest node ( 링크 )
데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할을 합니다.
Coordination only node ( 링크 )
data node와 master-eligible node의 일을 대신하는 이 노드는 대규모 클러스터에서 큰 이점이 있습니다.
즉 로드밸런서와 비슷한 역할을 한다고 보시면 됩니다.
3) 인덱스( index ) / 샤드( Shard ) / 복제( Replica )
Elasticsearch에서 index는 RDBMS에서 database와 대응하는 개념입니다.
또한 shard와 replica는 Elasticsearch에만 존재하는 개념이 아니라, 분산 데이터베이스 시스템에도 존재하는 개념입니다.
샤딩( sharding )은 데이터를 분산해서 저장하는 방법을 의미합니다.
즉, Elasticsearch에서 스케일 아웃을 위해 index를 여러 shard로 쪼갠 것입니다.
기본적으로 1개가 존재하며, 검색 성능 향상을 위해 클러스터의 샤드 갯수를 조정하는 튜닝을 하기도 합니다.
replica는 또 다른 형태의 shard라고 할 수 있습니다.
노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드들을 복제하는 것이죠.
따라서 replica는 서로 다른 노드에 존재할 것을 권장합니다.
출처 : https://stackoverflow.com/questions/19838825/what-are-elasticsearch-indices#answer-19839840
- Scale out
- 샤드를 통해 규모가 수평적으로 늘어날 수 있음
- 고가용성
- Replica를 통해 데이터의 안정성을 보장
- Schema Free
- Json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없음
- Restful
- 데이터 CURD 작업은 HTTP Restful API를 통해 수행하며, 각각 다음과 같이 대응합니다.
-
Data CRUD
Elasticsearch Restful
SELECT
GET
INSERT
PUT
UPDATE
POST
DELETE
DELETE
- -d 옵션
- 추가할 데이터를 json 포맷으로 전달합니다.
- -H 옵션
- 헤더를 명시합니다. 예제에서는 json으로 전달하기 위해서 application/json으로 작성했습니다.
- ?pretty
- 결과를 예쁘게 보여주도록 요청
이렇게 curl 요청을 하면, victolee 인덱스에, blog 타입으로 id 값이 1인 document가 저장됩니다.
[ Index( 색인 ) - 목차 ] [ Reverted Index( 역색인 ) - 찾아보기 ]
이상으로 Elasticsearch에 대한 개념잡기를 마치도록 하겠습니다.
Elasticsearch를 잘 다루기 위해서는 공식문서의 예제들을 따라해보는 것이 많은 도움이 될 것 같습니다.
[출처] https://victorydntmd.tistory.com/308
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.