
[ 一日30分 인생승리의 학습법] 왜 ‘한국어’의 자연어처리(NLP)는 유독 어려울까?
2022.12.31 00:20
[ 一日30分 인생승리의 학습법] 왜 ‘한국어’의 자연어처리(NLP)는 유독 어려울까?
우리가 일상적으로 사용하는 언어(자연어)는 컴퓨터가 바로 이해할 수 없습니다. 그렇기에 이를 컴퓨터가 이해할 수 있는 방식으로 다시 처리하는 과정이 필요합니다. 이를 ‘자연어 처리’ 기술이라고 하죠. 자연어 처리(Natural Language Processing)는 사람이 이해하는 자연어를 컴퓨터가 이해할 수 있는 값으로 변환하는 과정입니다. 나아가 컴퓨터가 이해하는 값을 사람이 이해할 수 있도록 다시 바꾸는 과정까지도 포함합니다.
- 자연어 이해(NLU, Natural Language Understanding)
- 자연어 생성(NLG, Natural Language Generation)
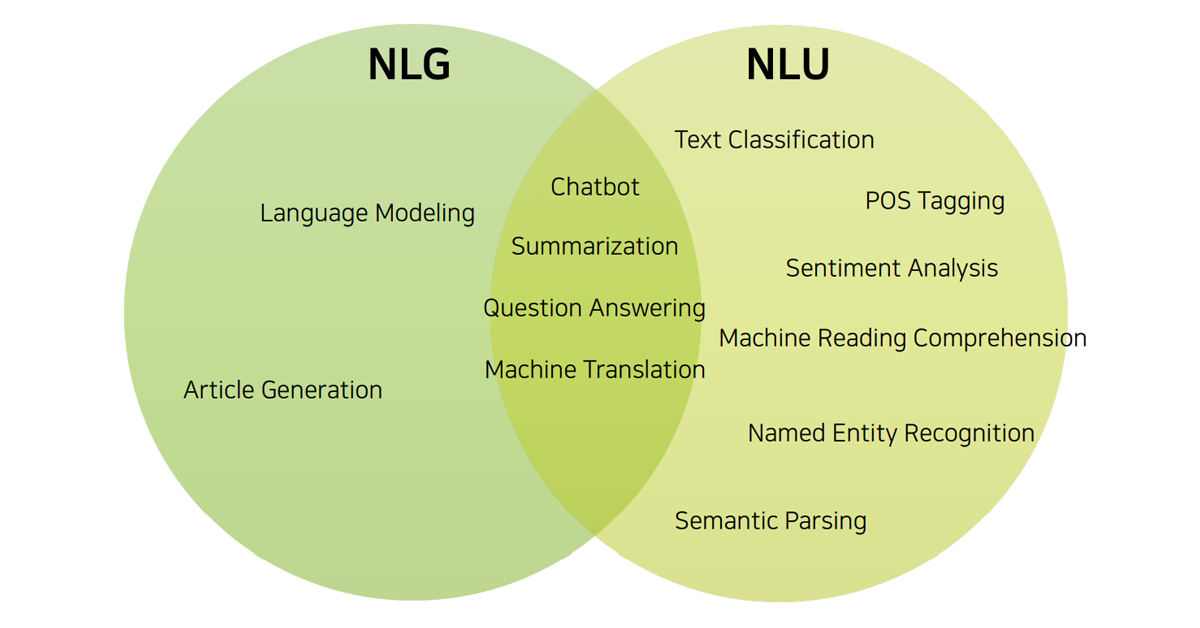
자연어 처리는 왜 이렇게 어려울까?
하지만 인간의 언어를 컴퓨터에게 전달하고, 컴퓨터의 언어를 인간이 이해할 수 있게 바꾸는 이 과정은 여간 쉬운 일이 아닙니다. 이는 언어 자체가 갖고 있는 여러 특징 때문인데요. 예시 문장을 보면서 그 이유를 알아봅시다.
1. 모호성(Ambiguity)
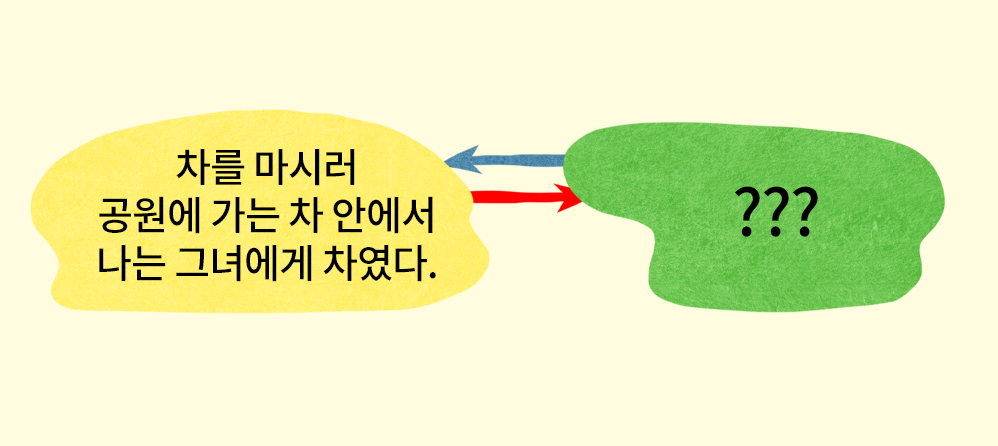
1) 표현의 중의성
차를 마시러 공원에 가는 차 안에서 나는 그녀에게 차였다.
위 문장을 영어 번역기에 입력했을 때, 우리가 이해한 것을 정확하게 구현하는 영어 문장을 과연 확인할 수 있을까요? 인간의 언어에는 ‘차’와 같이, 소리와 모양은 동일하지만 맥락에 따라 의미가 달라지는 단어들이 있습니다. 우리는 이 문장을 보고 직관적으로 맥락을 파악해내지만, 컴퓨터는 그렇게 할 수 없죠.
2) 문장 내 정보 부족
나는 철수를 안 때렸다.
위 문장은 여러 가지 의미로 해석될 수 있습니다. 언어는 효율성 극대화를 위해 커뮤니케이션 과정에서 많은 정보가 생략되기도 합니다. 하지만 컴퓨터는 자연어를 인간처럼 이해하는데 한계가 있기 때문에, 정보의 생략이 많을수록 자연어 처리는 굉장히 어려워집니다.

2. 같은 정보를 다르게 표현하기(Paraphrase)

[문장 1] 여자가 김치를 어떤 남자에게 집어 던지고 있다.
[문장 2] 여자가 어떤 남자에게 김치로 때리고 있다.
[문장 3] 여자가 김치로 싸대기를 날리고 있다.
[문장 4] 여자가 배추 김치 한 포기로 남자를 때리고 있다.
위의 이미지를 여러 문장으로 표현해보았습니다. 모두 다른 문장이지만, 하나의 이미지를 묘사하고 있죠. 이처럼 문장의 표현방식이 다양하고 비슷한 의미의 단어들이 존재하기 때문에 자연어 처리는 까다롭습니다.
언어는 생명체와 같아서 효율성을 극대화하기 위한 방향으로 계속해서 진화합니다. 그 과정에서 최대한 짧은 문장에 많은 정보를 담고, 굳이 언급할 필요 없는 정보는 생략하죠. 단, 생략된 맥락을 기계는 인간만큼 단번에 이해할 수 없다는 것이 자연어 처리가 어려운 이유입니다.
자연어 처리에 딥러닝을 접목하는 이유는?
그렇다면 자연어 처리에 딥러닝 기술을 접목하는 이유는 무엇일까요? 기존의 전통적인 자연어 처리 방식은 언어가 가진 모호성이나 중의성 등의 문제를 해결하기 어려웠습니다.
예를 들어, <빨강>, <분홍>, <파랑>이라는 3개의 단어를 컴퓨터에게 입력한다고 해볼까요? 전통적인 자연어 처리 과정에서는 <빨강>과 <분홍>, <파랑>이 각각 동일하게 다른 의미를 지닌 정보로 취급됩니다. 그러나 사람인 우리는 <빨강>과 <분홍>이 어떤 포함 관계에 속하는 유사성을 지닌 단어임을 직관적으로 이해하죠.

딥러닝을 기반으로 하는 자연어 처리에서는 <빨강>과 <분홍>을 <파랑>과 비교하여 더 가깝고 유사한 관계에 있는 정보라 처리합니다. 다시 말해서, 컴퓨터가 언어에서 연속적인 가치(Continuous Value)를 발견하고 언어를 처리할 수 있게 됩니다. 기존의 자연어 처리 방식이 지녔던 단점을 한층 보완하고, 보다 인간이 이해하는 방식과 유사하게 처리할 수 있습니다.
왜 ‘한국어’ 자연어 처리는 유독 어렵게 느껴질까?


복잡하고 까다로운 자연어 처리, 그런데 ‘한국어’ 를 처리하는 과정은 유독 어렵다고 느껴집니다. 실제로도 쉬운 작업이 절대 아니고요. 이는 각 나라별 언어가 가지고 있는 특징이 다르기 때문인데요. 한국어는 어간에 접사가 붙어 의미와 문법적 기능이 변화하는 ‘교착어’에 속합니다. 교착어만의 특징을 한 번 알아볼까요?
1) 접사 추가에 따른 의미 발생
예를 들어보겠습니다. 한국어로 ‘사과’라는 단어와 접사를 붙여 문장을 만들어 보세요. ‘사과(어간)’ + ‘를(접사)’일 때는 ‘사과’가 목적어가 되지만, ‘사과(어간)’ + ‘가(접사)’일 때는 ‘사과’가 주어가 되어 같은 언어도 문법적 기능이 달라지는 걸 볼 수 있죠. 이는 교착어인 한국어의 대표적인 특징입니다.
2) 유연한 단어 순서
나는 밥을 먹으러 간다.
밥을 먹으러 나는 간다.
나는 간다, 밥을 먹으러.
한국어는 단어의 순서를 바꾸어도 전체 맥락을 이해하는데 전혀 문제가 없습니다. 몇 가지 경우를 제외하면, 어순이 바뀌어도 문법적인 오류가 없는 올바른 문장이라 볼 수 있습니다. 이러한 언어적 특징은 인간에게는 편리하지만, 컴퓨터에게는 매우 어렵습니다. 어순이 제각각이지만 의미는 동일한 이 문장들을 동일한 정보로 처리하는 것이 쉽지 않기 때문입니다. 한국어의 자연어 처리가 유독 더 어려운 이유입니다.
3) 모호한 띄어쓰기 규칙
근대 이전까지 동양의 언어에는 ‘띄어쓰기’ 개념이 존재하지 않았습니다. 서양문화권에서는 중세부터 띄어쓰기가 확립된 것과 비교해보면 늦은 편이죠. 한국어는 맞춤법 상 띄어쓰기 규칙이 정해져 있기는 하나, 띄어쓰기를 지키지 않아도 문장의 맥락을 이해하는데 큰 무리가 없는 언어입니다. 문제는 사람들이 띄어쓰기를 지키지 않고 뭉텅이로 작성한 텍스트를 컴퓨터가 정확하게 인식하는 것이 매우 어렵다는 점이죠.
4) 평서문과 의문문의 차이 없음, 주어 부재
점심 먹었어. (I had lunch.)
점심 먹었어? (Did you have lunch?)
어순의 변화 없이, 주어가 생략되어도 한국어는 이해하는데 큰 문제가 없습니다. 하지만 똑같은 의미의 문장을 영어에서 한국어로 컴퓨터가 번역하는 것과, 한국어에서 영어로 변환하는 데에는 큰 차이가 있습니다. 동일한 문장에 마침표 대신 물음표를 붙이고, 주어에 대한 정보를 생략하더라도 한국어에서는 문장이 완성됩니다. 따라서, 컴퓨터가 숨겨진 맥락이나 의미를 파악하는데 더 까다로울 수밖에 없습니다.
[출처] https://fastcampus.co.kr/story_article_nlp
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.