
- 전체
- Sample DB
- database modeling
- [표준 SQL] Standard SQL
- G-SQL
- 10-Min
- ORACLE
- MS SQLserver
- MySQL
- SQLite
- postgreSQL
- 데이터아키텍처전문가 - 국가공인자격
- 데이터 분석 전문가 [ADP]
- [국가공인] SQL 개발자/전문가
- NoSQL
- hadoop
- hadoop eco system
- big data (빅데이터)
- stat(통계) R 언어
- XML DB & XQuery
- spark
- DataBase Tool
- 데이터분석 & 데이터사이언스
- Engineer Quality Management
- [기계학습] machine learning
- 데이터 수집 및 전처리
- 국가기술자격 빅데이터분석기사
- 암호화폐 (비트코인, cryptocurrency, bitcoin)
[기계학습] machine learning [딥러닝] [텐서플로우][SSAC X AIFFEL] 작사가 인공지능 만들기
2021.07.10 14:40
[딥러닝] [텐서플로우][SSAC X AIFFEL] 작사가 인공지능 만들기
Copy of 6. 작사가 인공지능 만들기
학습목표
- 인공지능이 문장을 이해하는 방식에 대해 알아본다.
- 시퀀스에 대해 알아본다.
시퀀스(Sequence)
시퀀스는 데이터에 순서(번호)를 붙여 나열한 것이다. 시퀀스의 특징은 다음과 같다.
- 데이터를 순서대로 하나씩 나열하여 나타낸 데이터 구조이다.
- 특정 위치(~번째)의 데이터를 가리킬 수 있다.
문장은 각 단어들이 문법이라는 규칙을 따라 배열되어 있기 때문에 시퀀스 데이터로 볼 수 있다.
문법은 복잡하기 때문에 문장 데이터를 이용한 인공지능을 만들 때에는 통계에 기반한 방법을 이용한다.
순환신경망(RNN)
나는 공부를 [ ]에서 빈 칸에는 한다 라는 단어가 들어갈 것이다. 문장에는 앞 뒤 문맥에 따라 통계적으로 많이 사용되는 단어들이 있다. 인공지능이 글을 이해하는 방식도 위와 같다. 문법적인 원리를 통해서가 아닌 수많은 글을 읽게하여 통계적으로 다음 단어는 어떤 것이 올지 예측하는 것이다. 이 방식에 가장 적합한 인공지능 모델 중 하나가 순환신경망(RNN)이다.
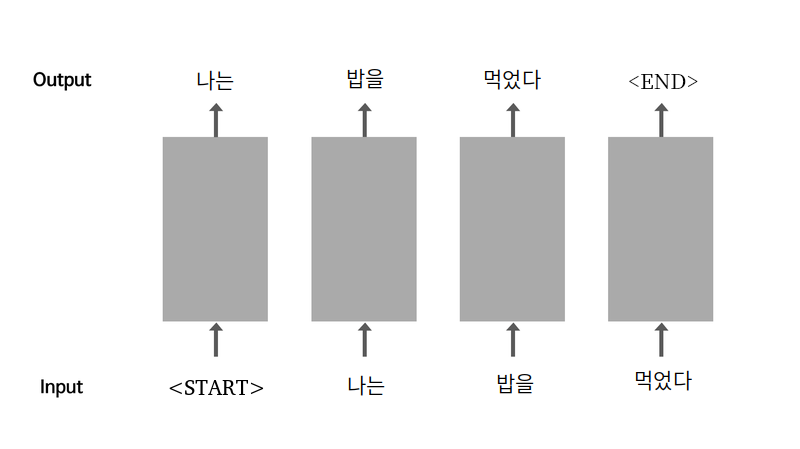
시작은 <start>라는 특수한 토큰을 앞에 추가하여 시작을 나타내고, <end>라는 토큰을 통해 문장의 끝을 나타낸다.
언어 모델
나는, 공부를, 한다 를 순차적으로 생성할 때, 우리는 공부를 다음이 한다인 것을 쉽게 할 수 있다. 나는 다음이 한다인 것은 어딘가 어색하게 느껴진다. 실제로 인공지능이 동작하는 방식도 순전히 운이다.
이것을 좀 더 확률적으로 표현해 보면 나는 공부를 다음에 한다가 나올 확률을 $p(한다|나는, 공부를)$라고 하면, $p(공부를|나는)$보다는 높게 나올 것이다. $p(한다|나는, 공부를, 열심히)$의 확률값은 더 높아질 것이다.
문장에서 단어 뒤에 다음 단어가 나올 확률이 높다는 것은 그 단어가 자연스럽다는 뜻이 된다. 확률이 낮다고 해서 자연스럽지 않은 것은 아니다. 단어 뒤에 올 수 있는 자연스러운 단어의 경우의 수가 워낙 많아서 불확실성이 높을 뿐이다.
n-1개의 단어 시퀀스 $w_1,⋯,w_{n-1}$이 주어졌을 때, n번째 단어 $w_n$으로 무엇이 올지 예측하는 확률 모델을 언어 모델(Language Model)이라고 부른다. 파라미터 $\theta$로 모델링 하는 언어 모델을 다음과 같이 표현할 수 있다.
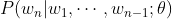
언어 모델은 어떻게 학습시킬 수 있을까? 언어 모델의 학습 데이터는 어떻게 나누어야 할까? 답은 간단하다. 어떠한 텍스트도 언어 모델의 학습 데이터가 될 수 있다. x_train이 n-1번째까지의 단어 시퀀스고, y_train이 n번째 단어가 되는 데이터셋이면 얼마든지 학습 데이터로 사용할 수 있다. 이렇게 잘 훈련된 언어 모델은 훌륭한 문장 생성기가 된다.


인공지능 만들기
(1) 데이터 준비
데이터에서 우리가 원하는 것은 문장(대사)뿐이므로, 화자 이름이나 공백은 제거해주어야 한다.
이제 문장을 단어로 나누어야 한다. 문장을 형태소로 나누는 것을 토큰화(Tokenize)라고 한다. 가장 간단한 방법은 띄어쓰기를 기준으로 나누는 것이다. 그러나 문장부호, 대소문자, 특수문자 등이 있기 때문에 따로 전처리를 먼저 해주어야 한다.
우리가 구축해야할 데이터셋은 입력이 되는 소스 문장(Source Sentence)과 출력이 되는 타겟 문장(Target Sentence)으로 나누어야 한다.
위에서 만든 전처리 함수에서 를 제거하면 소스 문장, 를 제거하면 타겟 문장이 된다.
이제 문장을 컴퓨터가 이해할 수 있는 숫자로 변경해주어야 한다. 텐서플로우는 자연어 처리를 위한 여러 가지 모듈을 제공하며, tf.keras.preprocessing.text.Tokenizer 패키지는 데이터를 토큰화하고, dictionary를 만들어주며, 데이터를 숫자로 변환까지 한 번에 해준다. 이 과정을 벡터화(Vectorize)라고 하며, 변환된 숫자 데이터를 텐서(tensor)라고 한다.
- 데이터셋 생성 과정 요약
- 정규표현식을 이용한 corpus 생성
tf.keras.preprocessing.text.Tokenizer를 이용해 corpus를 텐서로 변환tf.data.Dataset.from_tensor_slices()를 이용해 corpus 텐서를 tf.data.Dataset객체로 변환
(2) 모델 학습하기
이번에 만들 모델의 구조는 다음과 같다.
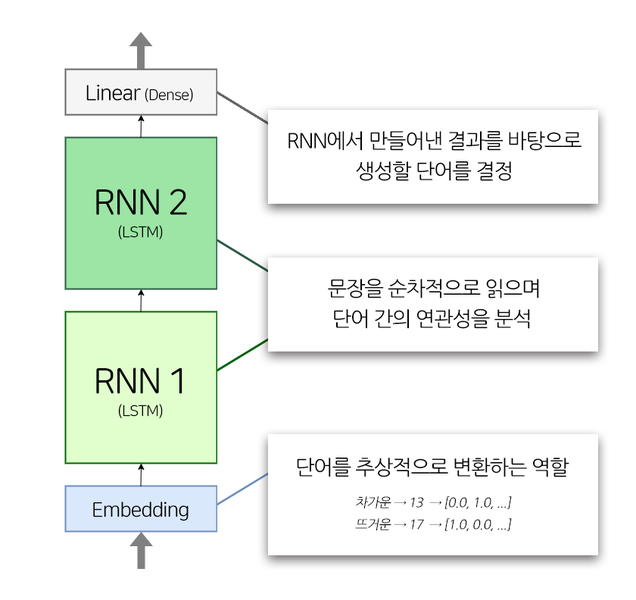
위의 코드에서 embbeding_size 는 워드 벡터의 차원 수를 나타내는 parameter로, 단어가 추상적으로 표현되는 크기를 말한다. 예를 들어 크기가 2라면 다음과 같이 표현할 수 있다.
- 차갑다: [0.0, 1.0]
- 뜨겁다: [1.0, 0.0]
- 미지근하다: [0.5, 0.5]
(3) 모델 평가하기
인공지능을 통한 작문은 수치적으로 평가할 수 없기 때문에 사람이 직접 평가를 해야 한다.
회고록
- range(n)도 reverse() 함수가 먹힌다는 걸 오늘 알았다...
- 예시에 주어진 train data 갯수는 124960인걸 보면 총 데이터는 156200개인 것 같은데 아무리 전처리 단계에서 조건에 맞게 처리해도 168000개 정도가 나온다. 아무튼 일단 돌려본다.
- 문장의 길이가 최대 15라는 이야기는
<start>, <end>를 포함하여 15가 되어야 하는 것 같아서 tokenize했을 때 문장의 길이가 13 이하인 것만 corpus로 만들었다. - 학습 회차 별 생성된 문장 input :
<start> i love- 1회차
'<start> i love you , i love you <end> ' - 2회차
'<start> i love you , i m not gonna crack <end> ' - 3회차
'<start> i love you to be a shot , i m not a man <end> ' - 4회차
'<start> i love you , i m not stunning , i m a fool <end> '
- 1회차
- batch_size를 각각 256, 512, 1024로 늘려서 진행했는데, 1epoch당 걸리는 시간이 74s, 62s, 59s 정도로 batch_size 배수 만큼의 차이는 없었다. batch_size가 배로 늘어나면 걸리느 시간도 당연히 반으로 줄어들 것이라 생각했는데 오산이었다.
- 1회차는 tokenize 했을 때 length가 15 이하인 것을 train_data로 사용하였다.
- 2, 3, 4회차는 tokenize 했을 때 length가 13 이하인 것을 train_data로 사용하였다.
- 3회차는 2회차랑 동일한 데이터에 padding 을 post에서 pre로 변경하였다. RNN에서는 뒤에 padding을 넣는 것 보다 앞쪽에 padding을 넣어주는 쪽이 마지막 결과에 paddind이 미치는 영향이 적어지기 때문에 더 좋은 성능을 낼 수 있다고 알고있기 때문이다.
- 근데 실제로는 pre padding 쪽이 loss가 더 크게 나왔다. 확인해보니 이론상으로는 pre padding이 성능이 더 좋지만 실제로는 post padding쪽이 성능이 더 잘 나와서 post padding을 많이 쓴다고 한다.
- batch_size를 변경해서 pre padding을 한 번 더 돌려보았더니 같은 조건에서의 post padding 보다 loss가 높았고 문장도 부자연스러웠다. 앞으로는 post padding을 사용해야겠다.
[출처] https://ceuity.tistory.com/26
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.