
- 전체
- Sample DB
- database modeling
- [표준 SQL] Standard SQL
- G-SQL
- 10-Min
- ORACLE
- MS SQLserver
- MySQL
- SQLite
- postgreSQL
- 데이터아키텍처전문가 - 국가공인자격
- 데이터 분석 전문가 [ADP]
- [국가공인] SQL 개발자/전문가
- NoSQL
- hadoop
- hadoop eco system
- big data (빅데이터)
- stat(통계) R 언어
- XML DB & XQuery
- spark
- DataBase Tool
- 데이터분석 & 데이터사이언스
- Engineer Quality Management
- [기계학습] machine learning
- 데이터 수집 및 전처리
- 국가기술자격 빅데이터분석기사
- 암호화폐 (비트코인, cryptocurrency, bitcoin)
[기계학습] machine learning [기계학습][머신러닝][딥러닝] DCGAN 튜토리얼
2022.11.08 20:19
[기계학습][머신러닝][딥러닝] DCGAN 튜토리얼
DCGAN 튜토리얼
- 저자: Nathan Inkawhich
-
번역: 조민성
개요
본 튜토리얼에서는 예제를 통해 DCGAN을 알아보겠습니다. 우리는 실제 유명인들의 사진들로 적대적 생성 신경망(GAN)을 학습시켜, 새로운 유명인의 사진을 만들어볼겁니다. 사용할 대부분의 코드는 pytorch/examples 의 DCGAN 구현에서 가져왔으며, 본 문서는 구현에 대한 설명과 함께, 어째서 이 모델이 작동하는지에 대해 설명을 해줄 것입니다. 처음 읽었을때는, 실제로 모델에 무슨일이 일어나고 있는지에 대해 이해하는 것이 조금 시간을 소요할 수 있으나, 그래도 GAN에 대한 사전지식이 필요하지는 않으니 걱정하지 않으셔도 됩니다. 추가로, GPU 1-2개를 사용하는 것이 시간절약에 도움이 될겁니다. 그럼 처음부터 천천히 시작해봅시다!
적대적 생성 신경망(Generative Adversarial Networks)
그래서 GAN이 뭘까요?
GAN이란 학습 데이터들의 분포를 학습해, 같은 분포에서 새로운 데이터를 생성할 수 있도록 DL 모델을 학습시키는 프레임워크입니다. 2014년 Ian Goodfellow가 개발했으며, Generative Adversarial Nets 논문에서 처음 소개되었습니다. GAN은 생성자 와 구분자 로 구별되는 두가지 모델을 가지고 있는것이 특징입니다. 생성자의 역할은 실제 이미지로 착각되도록 정교한 이미지를 만드는 것이고, 구분자의 역할은 이미지를 보고 생성자에 의해 만들어진 이미지인지 실제 이미지인지 알아내는 것입니다. 모델을 학습하는 동안, 생성자는 더 진짜같은 가짜 이미지를 만들어내며 구분자를 속이려 하고, 구분자는 더 정확히 가짜/진짜 이미지를 구별할 수 있도록 노력합니다. 이 ‘경찰과 도둑’ 게임은, 생성자가 학습 데이터들에서 직접 가져온 것처럼 보일정도로 완벽한 이미지를 만들어내고, 구분자가 생성자에서 나온 이미지를 50%의 확률로 가짜 혹은 진짜로 판별할 때, 균형상태에 도달하게 됩니다.
그럼 이제부터 본 튜토리얼에서 사용할 표기들을 구분자부터 정의해보겠습니다. 는 이미지로 표현되는 데이터로 두겠습니다. 는 구분자 신경망이고, 실제 학습데이터에서 가져온 를 통과시켜 상수(scalar) 확률값을 결과로 출려합니다. 이때, 우리는 이미지 데이터를 다루고 있으므로, 에는 3x64x64크기의 CHW 데이터가 입력됩니다. 직관적으로 볼때, 는 가 학습데이터에서 가져온 것일 때 출력이 크고, 생성자가 만들어낸 일때 작을 것입니다. 는 전통적인 이진 분류기(binary classification)으로도 생각될 수 있습니다.
이번엔 생성자의 표기들을 확인해봅시다. 를 정규분포에서 뽑은 잠재공간 벡터(laten space vector)라고 하겠습니다 (번역 주. laten space vector는 쉽게 생각해 정규분포를 따르는 n개의 원소를 가진 vector라 볼 수 있습니다. 다르게 얘기하면 정규분포에서 n개의 원소를 추출한 것과 같습니다). 는 벡터를 원하는 데이터 차원으로 대응시키는 신경망으로 둘 수 있습니다. 이때 의 목적은 에서 얻을 수 있는 학습 데이터들의 분포를 추정하여, 모사한 의 분포를 이용해 가짜 데이터들을 만드는 것입니다.
이어서, 는 가 출력한 결과물이 실제 이미지일 0~1사이의 상수의 확률값입니다. Goodfellow의 논문 에 기술되어 있듯, 가 이미지의 참/거짓을 정확히 판별할 확률인 에서 생성한 이미지를 가 가짜로 판별할 확률인 ()를 최소화 시키려는 점에서, 와 는 최대최소(minmax)게임을 하는 것과 같습니다. 논문에 따르면, GAN의 손실함수는 아래와 같습니다.
이론적으로는, 이 최대최소게임은 이고, 구분자에 입력된 데이터가 1/2의 무작위 확률로 참/거짓이 판별될때 해답에 이릅니다. 하지만 GAN의 수렴 이론은 아직도 활발히 연구가 진행중이고, 현실에서의 모델들은 이론적인 최적 상태에 도달하지 않는 경우도 많습니다.
그렇다면 DCGAN은 뭘까요?
DCGAN은 위에서 기술한 GAN에서 직접적으로 파생된 모델로, 생성자와 구분자에서 합성곱 신경망(convolution)과 전치 합성곱 신경망(convolution-transpose)을 사용했다는 것이 차이점입니다 Radford와 그 외가 저술한 Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks 논문에서 처음 모델이 소개되었고, 지금은 대부분의 GAN모델이 DCGAN을 기반으로 만들어지는 중입니다. 이전 GAN과 모델의 구조가 실제로 어떻게 다른지 확인을 해보자면, 먼저 구분자에서는 convolution 계층, batch norm 계층, 그리고 LeakyReLU 활성함수가 사용되었습니다. 클래식한 GAN과 마찬가지로, 구분자의 입력 데이터는 3x64x64 의 이미지이고, 출력값은 입력 데이터가 실제 데이터일 0~1사이의 확률값입니다. 다음으로, 생성자는 convolutional-transpose 계층, 배치 정규화(batch norm) 계층, 그리고 ReLU 활성함수가 사용되었습니다. 입력값은 역시나 정규분포에서 추출한 잠재공간 벡터 이고, 출력값은 3x64x64 RGB 이미지입니다. 이때, 전치 합성곱 신경망은 잠재공간 벡터로 하여금 이미지와 같은 차원을 갖도록 변환시켜주는 역할을 합니다 (번역 주. 전치 합성곱 신경망은 합성곱 신경망의 반대적인 개념이라 이해하면 쉽습니다. 입력된 작은 CHW 데이터를 가중치들을 이용해 더 큰 CHW로 업샘플링해주는 계층입니다). 논문에서는 각종 최적화 방법이나 손실함수의 계산, 모델의 가중치 초기화 방법등에 관한 추가적인 정보들도 적어두었는데, 이 부분은 다음 섹션에서 설명하도록 하겠습니다.
from __future__ import print_function
#%matplotlib inline
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
# 코드 실행결과의 동일성을 위해 무작위 시드를 설정합니다
manualSeed = 999
#manualSeed = random.randint(1, 10000) # 만일 새로운 결과를 원한다면 주석을 없애면 됩니다
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)
Out:
Random Seed: 999
설정값
몇 가지 설정값들을 정의해봅시다:
-
dataroot - 데이터셋 폴더의 경로입니다. 데이터셋에 관한건 다음 섹션에서 더 자세히 설명하겠습니다.
-
workers - DataLoader에서 데이터를 불러올 때 사용할 쓰레드의 개수입니다.
-
batch_size - 학습에 사용할 배치 크기입니다. DCGAN에서는 128을 사용했습니다.
-
image_size - 학습에 사용되는 이미지의 크기입니다. 본 문서에서는 64x64의 크기를 기본으로 하나, 만일 다른 크기의 이미지를 사용한다면 D와 G의 구조 역시 변경되어야 합니다. 더 자세한 정보를 위해선 이곳 을 확인해 보세요.
-
nc - 입력 이미지의 색 채널개수입니다. RGB 이미지이기 때문에 3으로 설정합니다.
-
nz - 잠재공간 벡터의 원소들 개수입니다.
-
ngf - 생성자를 통과할때 만들어질 특징 데이터의 채널개수입니다.
-
ndf - 구분자를 통과할때 만들어질 특징 데이터의 채널개수입니다.
-
num_epochs - 학습시킬 에폭 수입니다. 오래 학습시키는 것이 대부분 좋은 결과를 보이지만, 당연히도 시간이 오래걸리는 것이 단점입니다.
-
lr - 모델의 학습률입니다. DCGAN에서 사용된대로 0.0002로 설정합니다.
-
beta1 - Adam 옵티마이저에서 사용할 beta1 하이퍼파라미터 값입니다. 역시나 논문에서 사용한대로 0.5로 설정했습니다.
-
ngpu - 사용가능한 GPU의 번호입니다. 0으로 두면 CPU에서 학습하고, 0보다 큰 수로 설정하면 각 숫자가 가리키는 GPU로 학습시킵니다.
# 데이터셋의 경로
dataroot = "data/celeba"
# dataloader에서 사용할 쓰레드 수
workers = 2
# 배치 크기
batch_size = 128
# 이미지의 크기입니다. 모든 이미지들은 transformer를 이용해 64로 크기가 통일됩니다.
image_size = 64
# 이미지의 채널 수로, RGB 이미지이기 때문에 3으로 설정합니다.
nc = 3
# 잠재공간 벡터의 크기 (예. 생성자의 입력값 크기)
nz = 100
# 생성자를 통과하는 특징 데이터들의 채널 크기
ngf = 64
# 구분자를 통과하는 특징 데이터들의 채널 크기
ndf = 64
# 학습할 에폭 수
num_epochs = 5
# 옵티마이저의 학습률
lr = 0.0002
# Adam 옵티마이저의 beta1 하이퍼파라미터
beta1 = 0.5
# 사용가능한 gpu 번호. CPU를 사용해야 하는경우 0으로 설정하세요
ngpu = 1
데이터
본 튜토리얼에서 사용할 데이터는 Celeb-A Faces dataset 로, 해당 링크를 이용하거나 Google Drive 에서 데이터를 받을 수 있습니다. 데이터를 받으면 img_align_celeba.zip 라는 파일을 보게될 겁니다. 다운로드가 끝나면 celeba 이라는 폴더를 새로 만들고, 해당 폴더에 해당 zip 파일을 압축해제 해주시면 됩니다. 압축 해제 후, 위에서 정의한 dataroot 변수에 방금 만든 celeba 폴더의 경로를 넣어주세요. 위의 작업이 끝나면 celeba 폴더의 구조는 다음과 같아야 합니다:
/path/to/celeba
-> img_align_celeba
-> 188242.jpg
-> 173822.jpg
-> 284702.jpg
-> 537394.jpg
...
이 과정들은 프로그램이 정상적으로 구동하기 위해서는 중요한 부분입니다. 이때 celeba 폴더안에 다시 폴더를 두는 이유는, ImageFolder 클래스가 데이터셋의 최상위 폴더에 서브폴더를 요구하기 때문입니다. 이제 데이터셋과 DataLoader의 설정을 끝냈습니다. 최종적으로 학습 데이터들을 시각화해봅시다.
# 우리가 설정한 대로 이미지 데이터셋을 불러와 봅시다
# 먼저 데이터셋을 만듭니다
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
# dataloader를 정의해봅시다
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=workers)
# GPU 사용여부를 결정해 줍니다
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
# 학습 데이터들 중 몇가지 이미지들을 화면에 띄워봅시다
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(),(1,2,0)))

구현
모델의 설정값들과 데이터들이 준비되었기 때문에, 드디어 모델의 구현으로 들어갈 수 있을 것 같습니다. 먼저 가중치 초기화에 대해 이야기 해보고, 순서대로 생성자, 구분자, 손실 함수, 학습 방법들을 알아보겠습니다.
가중치 초기화
DCGAN 논문에서는, 평균이 0이고 분산이 0.02인 정규분포을 이용해, 구분자와 생성자 모두 무작위 초기화를 진행하는 것이 좋다고 합니다. weights_init 함수는 매개변수로 모델을 입력받아, 모든 합성곱 계층, 전치 합성곱 계층, 배치 정규화 계층을, 위에서 말한 조건대로 가중치들을 다시 초기화 시킵니다. 이 함수는 모델이 만들어지자 마자 바로 적용을 시키게 됩니다.
# netG와 netD에 적용시킬 커스텀 가중치 초기화 함수
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
생성자
생성자 는 잠재 공간 벡터 를, 데이터 공간으로 변환시키도록 설계되었습니다. 우리에게 데이터라 함은 이미지이기 때문에, 를 데이터공간으로 변환한다는 뜻은, 학습이미지와 같은 사이즈를 가진 RGB 이미지를 생성하는것과 같습니다 (예. 3x64x64). 실제 모델에서는 스트라이드(stride) 2를 가진 전치 합성곱 계층들을 이어서 구성하는데, 각 전치 합성곱 계층 하나당 2차원 배치 정규화 계층과 relu 활성함수를 한 쌍으로 묶어서 사용합니다. 생성자의 마지막 출력 계층에서는 데이터를 tanh 함수에 통과시키는데, 이는 출력 값을 사이의 범위로 조정하기 위해서 입니다. 이때 배치 정규화 계층을 주목할 필요가 있는데, DCGAN 논문에 의하면, 이 계층이 경사하강법(gradient-descent)의 흐름에 중요한 영향을 미치는 것으로 알려져 있습니다. 아래의 그림은 DCGAN 논문에서 가져온 생성자의 모델 아키텍쳐입니다.
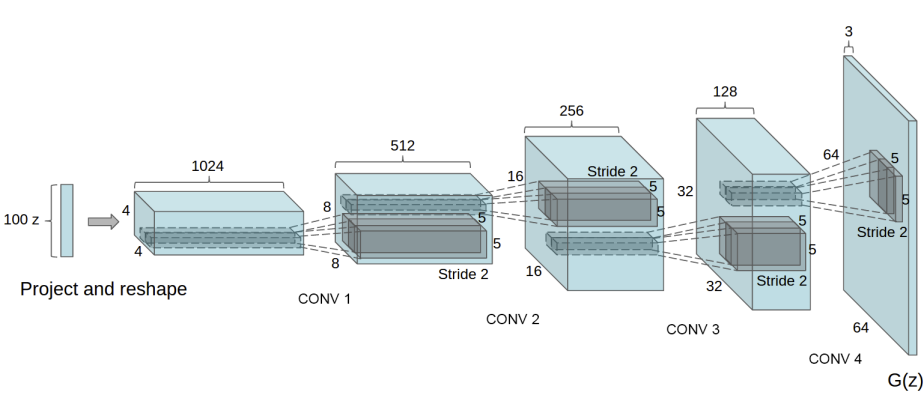
우리가 설정값 섹션에서 정의한 값들이 (nz, ngf, 그리고 nc) 생성자 모델 아키텍쳐에 어떻게 영향을 끼치는지 주목해주세요. nz 는 z 입력 벡터의 길이, ngf 는 생성자를 통과하는 특징 데이터의 크기, 그리고 nc 는 출력 이미지의 채널 개수입니다 (RGB 이미지이기 때문에 3으로 설정을 했습니다). 아래는 생성자의 코드입니다.
# 생성자 코드
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# 입력데이터 Z가 가장 처음 통과하는 전치 합성곱 계층입니다.
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. (ngf*4) x 8 x 8
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. (ngf*2) x 16 x 16
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 위의 계층을 통과한 데이터의 크기. (ngf) x 32 x 32
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# 위의 계층을 통과한 데이터의 크기. (nc) x 64 x 64
)
def forward(self, input):
return self.main(input)
좋습니다. 이제 우리는 생성자의 인스턴스를 만들고 weights_init 함수를 적용시킬 수 있습니다. 모델의 인스턴스를 출력해서 생성자가 어떻게 구성되어있는지 확인해봅시다.
# 생성자를 만듭니다
netG = Generator(ngpu).to(device)
# 필요한 경우 multi-gpu를 설정 해주세요
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
# 모든 가중치의 평균을 0, 분산을 0.02로 초기화 하기 위해
# weight_init 함수를 적용시킵니다
netG.apply(weights_init)
# 모델의 구조를 출력합니다
print(netG)
Out:
Generator(
(main): Sequential(
(0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(13): Tanh()
)
)
구분자
앞서 언급했듯, 구분자 는 3x64x64 이미지를 입력받아, Conv2d, BatchNorm2d, 그리고 LeakyReLU 계층을 통과시켜 데이터를 가공시키고, 마지막 출력에서 Sigmoid 함수를 이용하여 0~1 사이의 확률값으로 조정합니다. 이 아키텍쳐는 필요한 경우 더 다양한 레이어를 쌓을 수 있지만, 배치 정규화와 LeakyReLU, 특히 보폭이 있는 (strided) 합성곱 계층을 사용하는 것에는 이유가 있습니다. DCGAN 논문에서는 보폭이 있는 합성곱 계층을 사용하는 것이 신경망 내에서 스스로의 풀링(Pooling) 함수를 학습하기 때문에, 데이터를 처리하는 과정에서 직접적으로 풀링 계층( MaxPool or AvgPooling)을 사용하는 것보다 더 유리하다고 합니다. 또한 배치 정규화와 leaky relu 함수는 학습과정에서 와 가 더 효과적인 경사도(gradient)를 얻을 수 있습니다.
# 구분자 코드
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# 입력 데이터의 크기는 (nc) x 64 x 64 입니다
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# 위의 계층을 통과한 데이터의 크기. (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
이제 우리는 생성자에 한 것처럼 구분자의 인스턴스를 만들고, weights_init 함수를 적용시킨 다음, 모델의 구조를 출력해볼 수 있습니다.
# 구분자를 만듭니다
netD = Discriminator(ngpu).to(device)
# 필요한 경우 multi-gpu를 설정 해주세요
if (device.type == 'cuda') and (ngpu > 1):
netD = nn.DataParallel(netD, list(range(ngpu)))
# 모든 가중치의 평균을 0, 분산을 0.02로 초기화 하기 위해
# weight_init 함수를 적용시킵니다
netD.apply(weights_init)
# 모델의 구조를 출력합니다
print(netD)
Out:


Discriminator(
(main): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(12): Sigmoid()
)
)
손실함수와 옵티마이저
와 의 설정을 끝냈으니, 이제 손실함수와 옵티마이저를 정하여 학습을 구체화시킬 시간입니다. 손실함수로는 Binary Cross Entropy loss (BCELoss) 를 사용할겁니다. 해당함수는 아래의 식으로 파이토치에 구현되어 있습니다:
이때, 위의 함수가 로그함수 요소를 정의한 방식을 주의깊게 봐주세요 (예. 와 ). 우린 을 조정을 조정하여, BCE 함수에서 사용할 요소를 고를 수 있습니다. 이 부분은 이후에 서술할 학습 섹션에서 다루겠지만, 어떻게 를 이용하여 우리가 원하는 요소들만 골라낼 수 있는지 이해하는 것이 먼저입니다 (예. GT labels).
좋습니다. 다음으로 넘어가겠습니다. 참 라벨 (혹은 정답)은 1로 두고, 거짓 라벨 (혹은 오답)은 0으로 두겠습니다. 각 라벨의 값을 정한건 GAN 논문에서 사용된 값들로, GAN을 구성할때의 관례라 할 수 있습니다. 방금 정한 라벨 값들은 추후에 손실값을 계산하는 과정에서 사용될겁니다. 마지막으로, 서로 구분되는 두 옵티마이저를 구성하겠습니다. 하나는 를 위한 것, 다른 하나는 를 위한 것입니다. DCGAN에 서술된 대로, 두 옵티마이저는 모두 Adam을 사용하고, 학습률은 0.0002, Beta1 값은 0.5로 둡니다. 추가적으로, 학습이 진행되는 동안 생성자의 상태를 알아보기 위하여, 프로그램이 끝날때까지 고정된 잠재공간 벡터를 생성하겠습니다 (예. fixed_noise). 이 벡터들 역시 가우시안 분포에서 추출합니다. 학습 과정을 반복하면서 에 주기적으로 같은 잠재공간 벡터를 입력하면, 그 출력값을 기반으로 생성자의 상태를 확인 할 수 있습니다.
# BCELoss 함수의 인스턴스를 생성합니다
criterion = nn.BCELoss()
# 생성자의 학습상태를 확인할 잠재 공간 벡터를 생성합니다
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
# 학습에 사용되는 참/거짓의 라벨을 정합니다
real_label = 1.
fake_label = 0.
# G와 D에서 사용할 Adam옵티마이저를 생성합니다
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
학습
드디어 최종입니다. GAN 프레임워크에 필요한 부분들은 모두 가졌으니, 실제 모델을 학습시키는 방법을 알아보겠습니다. 주의를 기울일 것은, GAN을 학습시키는 건 관례적인 기술들의 집합이기 때문에, 잘못된 하이퍼파라미터의 설정은 모델의 학습을 망가뜨릴 수 있습니다. 무엇이 잘못되었는지 알아내는 것 조차도 힘들죠. 그러한 이유로, 본 튜토리얼에서는 Goodfellow의 논문에서 서술된 Algorithm 1을 기반으로, ganhacks 에서 사용된 몇가지 괜찮은 테크닉들을 더할 것입니다. 앞서 몇번 설명했지만, 우리의 의도는 “진짜 혹은 가짜 이미지를 구성”하고, 를 최대화하는 G의 목적함수를 최적화 시키는 겁니다. 학습과정은 크게 두가지로 나눕니다. Part 1은 구분자를, Part 2는 생성자를 업데이트하는 과정입니다.
Part 1 - 구분자의 학습
구분자의 목적은 주어진 입력값이 진짜인지 가짜인지 판별하는 것임을 상기합시다. Goodfellow의 말을 빌리자면, 구분자는 “변화도(gradient)를 상승(ascending)시키며 훈련”하게 됩니다. 실전적으로 얘기하면, 를 최대화시키는 것과 같습니다. ganhacks에서 미니 배치(mini-batch)를 분리하여 사용한 개념을 가져와서, 우리 역시 두가지 스텝으로 분리해 계산을 해보겠습니다. 먼저, 진짜 데이터들로만 이루어진 배치를 만들어 에 통과시킵니다. 그 출력값으로 () 의 손실값을 계산하고, 역전파 과정에서의 변화도들을 계산합니다. 여기까지가 첫번째 스텝입니다. 두번째 스텝에서는, 오로지 가짜 데이터들로만 이루어진 배치를 만들어 에 통과시키고, 그 출력값으로 () 의 손실값을 계산해 역전파 변화도를 구하면 됩니다. 이때 두가지 스텝에서 나오는 변화도들은 축적(accumulate) 시켜야 합니다. 변화도까지 구했으니, 이제 옵티마이저를 사용해야겠죠. 파이토치의 함수를 호출해주면 알아서 변화도가 적용될겁니다.
Part 2 - 생성자의 학습
오리지널 GAN 논문에 명시되어 있듯, 생성자는 을 최소화시키는 방향으로 학습합니다. 하지만 이 방식은 충분한 변화도를 제공하지 못함을 Goodfellow가 보여줬습니다. 특히 학습초기에는 더욱 문제를 일으키죠. 이를 해결하기 위해 를 최대화 하는 방식으로 바꿔서 학습을 하겠습니다. 코드에서 구현하기 위해서는 : Part 1에서 한대로 구분자를 이용해 생성자의 출력값을 판별해주고, 진짜 라벨값 을 이용해 G의 손실값을 구해줍니다. 그러면 구해진 손실값으로 변화도를 구하고, 최종적으로는 옵티마이저를 이용해 G의 가중치들을 업데이트시켜주면 됩니다. 언뜻 볼때는, 생성자가 만들어낸 가짜 이미지에 진짜 라벨을 사용하는것이 직관적으로 위배가 될테지만, 이렇게 라벨을 바꿈으로써 라는 BCELoss의 일부분을 사용할 수 있게 합니다 (앞서 우리는 BCELoss에서 라벨을 이용해 원하는 로그 계산 요소를 고를 수 있음을 알아봤습니다).
마무리로 G의 훈련 상태를 알아보기 위하여, 몇가지 통계적인 수치들과, fixed_noise를 통과시킨 결과를 화면에 출력하는 코드를 추가하겠습니다. 이때 통계적인 수치들이라 함은 :
-
Loss_D - 진짜 데이터와 가짜 데이터들 모두에서 구해진 손실값. ().
-
Loss_G - 생성자의 손실값.
-
D(x) - 구분자가 데이터를 판별한 확률값입니다. 처음에는 1에 가까운 값이다가, G가 학습할수록 0.5값에 수렴하게 됩니다.
-
D(G(z)) - 가짜데이터들에 대한 구분자의 출력값입니다. 처음에는 0에 가까운 값이다가, G가 학습할수록 0.5에 수렴하게 됩니다
Note: 이후의 과정은 epoch의 수와 데이터의 수에 따라 시간이 좀 걸릴 수 있습니다
# 학습 과정
# 학습상태를 체크하기 위해 손실값들을 저장합니다
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starting Training Loop...")
# 에폭(epoch) 반복
for epoch in range(num_epochs):
# 한 에폭 내에서 배치 반복
for i, data in enumerate(dataloader, 0):
############################
# (1) D 신경망을 업데이트 합니다: log(D(x)) + log(1 - D(G(z)))를 최대화 합니다
###########################
## 진짜 데이터들로 학습을 합니다
netD.zero_grad()
# 배치들의 사이즈나 사용할 디바이스에 맞게 조정합니다
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label,
dtype=torch.float, device=device)
# 진짜 데이터들로 이루어진 배치를 D에 통과시킵니다
output = netD(real_cpu).view(-1)
# 손실값을 구합니다
errD_real = criterion(output, label)
# 역전파의 과정에서 변화도를 계산합니다
errD_real.backward()
D_x = output.mean().item()
## 가짜 데이터들로 학습을 합니다
# 생성자에 사용할 잠재공간 벡터를 생성합니다
noise = torch.randn(b_size, nz, 1, 1, device=device)
# G를 이용해 가짜 이미지를 생성합니다
fake = netG(noise)
label.fill_(fake_label)
# D를 이용해 데이터의 진위를 판별합니다
output = netD(fake.detach()).view(-1)
# D의 손실값을 계산합니다
errD_fake = criterion(output, label)
# 역전파를 통해 변화도를 계산합니다. 이때 앞서 구한 변화도에 더합니다(accumulate)
errD_fake.backward()
D_G_z1 = output.mean().item()
# 가짜 이미지와 진짜 이미지 모두에서 구한 손실값들을 더합니다
# 이때 errD는 역전파에서 사용되지 않고, 이후 학습 상태를 리포팅(reporting)할 때 사용합니다
errD = errD_real + errD_fake
# D를 업데이트 합니다
optimizerD.step()
############################
# (2) G 신경망을 업데이트 합니다: log(D(G(z)))를 최대화 합니다
###########################
netG.zero_grad()
label.fill_(real_label) # 생성자의 손실값을 구하기 위해 진짜 라벨을 이용할 겁니다
# 우리는 방금 D를 업데이트했기 때문에, D에 다시 가짜 데이터를 통과시킵니다.
# 이때 G는 업데이트되지 않았지만, D가 업데이트 되었기 때문에 앞선 손실값가 다른 값이 나오게 됩니다
output = netD(fake).view(-1)
# G의 손실값을 구합니다
errG = criterion(output, label)
# G의 변화도를 계산합니다
errG.backward()
D_G_z2 = output.mean().item()
# G를 업데이트 합니다
optimizerG.step()
# 훈련 상태를 출력합니다
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# 이후 그래프를 그리기 위해 손실값들을 저장해둡니다
G_losses.append(errG.item())
D_losses.append(errD.item())
# fixed_noise를 통과시킨 G의 출력값을 저장해둡니다
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1
Out:
Starting Training Loop...
[0/5][0/1583] Loss_D: 1.7959 Loss_G: 6.4628 D(x): 0.6612 D(G(z)): 0.6682 / 0.0028
[0/5][50/1583] Loss_D: 0.1906 Loss_G: 13.0804 D(x): 0.9764 D(G(z)): 0.1260 / 0.0000
[0/5][100/1583] Loss_D: 1.4810 Loss_G: 14.5936 D(x): 0.8732 D(G(z)): 0.5854 / 0.0000
[0/5][150/1583] Loss_D: 0.9001 Loss_G: 9.0919 D(x): 0.9559 D(G(z)): 0.4923 / 0.0004
[0/5][200/1583] Loss_D: 0.3785 Loss_G: 5.0609 D(x): 0.7776 D(G(z)): 0.0524 / 0.0114
[0/5][250/1583] Loss_D: 0.9362 Loss_G: 5.8654 D(x): 0.9146 D(G(z)): 0.4799 / 0.0070
[0/5][300/1583] Loss_D: 0.5799 Loss_G: 5.6046 D(x): 0.9065 D(G(z)): 0.2953 / 0.0093
[0/5][350/1583] Loss_D: 0.4637 Loss_G: 3.7669 D(x): 0.8772 D(G(z)): 0.2246 / 0.0385
[0/5][400/1583] Loss_D: 0.3646 Loss_G: 5.9193 D(x): 0.7762 D(G(z)): 0.0350 / 0.0094
[0/5][450/1583] Loss_D: 1.0633 Loss_G: 8.3121 D(x): 0.9224 D(G(z)): 0.5516 / 0.0010
[0/5][500/1583] Loss_D: 0.1696 Loss_G: 5.3900 D(x): 0.9129 D(G(z)): 0.0634 / 0.0080
[0/5][550/1583] Loss_D: 0.4618 Loss_G: 4.4706 D(x): 0.8421 D(G(z)): 0.1841 / 0.0199
[0/5][600/1583] Loss_D: 0.6071 Loss_G: 5.4043 D(x): 0.9305 D(G(z)): 0.3455 / 0.0084
[0/5][650/1583] Loss_D: 0.3765 Loss_G: 5.5768 D(x): 0.8646 D(G(z)): 0.1378 / 0.0090
[0/5][700/1583] Loss_D: 0.2417 Loss_G: 4.7877 D(x): 0.8472 D(G(z)): 0.0480 / 0.0163
[0/5][750/1583] Loss_D: 0.5000 Loss_G: 4.4517 D(x): 0.7209 D(G(z)): 0.0243 / 0.0245
[0/5][800/1583] Loss_D: 0.5771 Loss_G: 10.1181 D(x): 0.9300 D(G(z)): 0.3403 / 0.0001
[0/5][850/1583] Loss_D: 0.9266 Loss_G: 6.9814 D(x): 0.9691 D(G(z)): 0.4892 / 0.0030
[0/5][900/1583] Loss_D: 0.9581 Loss_G: 1.6736 D(x): 0.6383 D(G(z)): 0.2000 / 0.2666
[0/5][950/1583] Loss_D: 0.3992 Loss_G: 3.2458 D(x): 0.8043 D(G(z)): 0.0831 / 0.0726
[0/5][1000/1583] Loss_D: 0.2388 Loss_G: 4.3975 D(x): 0.8652 D(G(z)): 0.0524 / 0.0181
[0/5][1050/1583] Loss_D: 0.8922 Loss_G: 1.9124 D(x): 0.5285 D(G(z)): 0.0310 / 0.2006
[0/5][1100/1583] Loss_D: 0.7334 Loss_G: 3.0939 D(x): 0.6249 D(G(z)): 0.0576 / 0.0763
[0/5][1150/1583] Loss_D: 0.5622 Loss_G: 5.1963 D(x): 0.8829 D(G(z)): 0.2880 / 0.0111
[0/5][1200/1583] Loss_D: 0.3858 Loss_G: 3.0364 D(x): 0.8750 D(G(z)): 0.1747 / 0.0970
[0/5][1250/1583] Loss_D: 0.4891 Loss_G: 5.3349 D(x): 0.8825 D(G(z)): 0.2582 / 0.0102
[0/5][1300/1583] Loss_D: 0.5266 Loss_G: 3.2789 D(x): 0.7251 D(G(z)): 0.0933 / 0.0658
[0/5][1350/1583] Loss_D: 1.7573 Loss_G: 0.6747 D(x): 0.3012 D(G(z)): 0.0215 / 0.5841
[0/5][1400/1583] Loss_D: 0.5714 Loss_G: 2.8549 D(x): 0.7047 D(G(z)): 0.0899 / 0.0989
[0/5][1450/1583] Loss_D: 0.5098 Loss_G: 3.1655 D(x): 0.7570 D(G(z)): 0.1149 / 0.0640
[0/5][1500/1583] Loss_D: 0.8749 Loss_G: 5.7126 D(x): 0.9264 D(G(z)): 0.4816 / 0.0086
[0/5][1550/1583] Loss_D: 0.4130 Loss_G: 2.8181 D(x): 0.7850 D(G(z)): 0.1126 / 0.0920
[1/5][0/1583] Loss_D: 0.5627 Loss_G: 4.4834 D(x): 0.9068 D(G(z)): 0.3043 / 0.0215
[1/5][50/1583] Loss_D: 0.7230 Loss_G: 2.4460 D(x): 0.5977 D(G(z)): 0.0303 / 0.1344
[1/5][100/1583] Loss_D: 0.9871 Loss_G: 0.8562 D(x): 0.4922 D(G(z)): 0.0226 / 0.5728
[1/5][150/1583] Loss_D: 0.5637 Loss_G: 3.7862 D(x): 0.6811 D(G(z)): 0.0555 / 0.0484
[1/5][200/1583] Loss_D: 0.3167 Loss_G: 3.1661 D(x): 0.8372 D(G(z)): 0.1012 / 0.0635
[1/5][250/1583] Loss_D: 0.4507 Loss_G: 3.6032 D(x): 0.7175 D(G(z)): 0.0447 / 0.0577
[1/5][300/1583] Loss_D: 0.4926 Loss_G: 3.5136 D(x): 0.8439 D(G(z)): 0.2295 / 0.0476
[1/5][350/1583] Loss_D: 0.4423 Loss_G: 2.9727 D(x): 0.8002 D(G(z)): 0.1488 / 0.0735
[1/5][400/1583] Loss_D: 0.4441 Loss_G: 4.0641 D(x): 0.8738 D(G(z)): 0.2221 / 0.0274
[1/5][450/1583] Loss_D: 0.4330 Loss_G: 4.7252 D(x): 0.9255 D(G(z)): 0.2648 / 0.0155
[1/5][500/1583] Loss_D: 0.3551 Loss_G: 3.7972 D(x): 0.7741 D(G(z)): 0.0526 / 0.0399
[1/5][550/1583] Loss_D: 0.5481 Loss_G: 4.8267 D(x): 0.9062 D(G(z)): 0.3074 / 0.0137
[1/5][600/1583] Loss_D: 0.4531 Loss_G: 3.3659 D(x): 0.7476 D(G(z)): 0.0721 / 0.0543
[1/5][650/1583] Loss_D: 1.0355 Loss_G: 7.0533 D(x): 0.9748 D(G(z)): 0.5544 / 0.0019
[1/5][700/1583] Loss_D: 0.4840 Loss_G: 2.3388 D(x): 0.7433 D(G(z)): 0.1204 / 0.1381
[1/5][750/1583] Loss_D: 0.6690 Loss_G: 2.1550 D(x): 0.6382 D(G(z)): 0.0922 / 0.1777
[1/5][800/1583] Loss_D: 0.3398 Loss_G: 4.0094 D(x): 0.8738 D(G(z)): 0.1616 / 0.0263
[1/5][850/1583] Loss_D: 1.0483 Loss_G: 0.8916 D(x): 0.4568 D(G(z)): 0.0353 / 0.4880
[1/5][900/1583] Loss_D: 0.4529 Loss_G: 3.1616 D(x): 0.8913 D(G(z)): 0.2564 / 0.0583
[1/5][950/1583] Loss_D: 0.5913 Loss_G: 3.2633 D(x): 0.7995 D(G(z)): 0.2616 / 0.0503
[1/5][1000/1583] Loss_D: 1.3455 Loss_G: 1.7747 D(x): 0.3777 D(G(z)): 0.0303 / 0.2374
[1/5][1050/1583] Loss_D: 0.5999 Loss_G: 3.5441 D(x): 0.8402 D(G(z)): 0.2819 / 0.0422
[1/5][1100/1583] Loss_D: 0.4023 Loss_G: 2.7919 D(x): 0.8142 D(G(z)): 0.1464 / 0.0838
[1/5][1150/1583] Loss_D: 0.3762 Loss_G: 2.7653 D(x): 0.8583 D(G(z)): 0.1748 / 0.0876
[1/5][1200/1583] Loss_D: 0.7506 Loss_G: 4.2851 D(x): 0.8631 D(G(z)): 0.3899 / 0.0237
[1/5][1250/1583] Loss_D: 0.4409 Loss_G: 4.3827 D(x): 0.9266 D(G(z)): 0.2774 / 0.0178
[1/5][1300/1583] Loss_D: 0.8028 Loss_G: 1.1196 D(x): 0.5358 D(G(z)): 0.0473 / 0.3961
[1/5][1350/1583] Loss_D: 0.5463 Loss_G: 2.9937 D(x): 0.7880 D(G(z)): 0.2266 / 0.0660
[1/5][1400/1583] Loss_D: 0.9233 Loss_G: 1.5740 D(x): 0.4889 D(G(z)): 0.0572 / 0.2812
[1/5][1450/1583] Loss_D: 0.4332 Loss_G: 3.2046 D(x): 0.8166 D(G(z)): 0.1708 / 0.0585
[1/5][1500/1583] Loss_D: 1.0461 Loss_G: 4.5634 D(x): 0.9293 D(G(z)): 0.5601 / 0.0193
[1/5][1550/1583] Loss_D: 0.7470 Loss_G: 1.4907 D(x): 0.6029 D(G(z)): 0.1084 / 0.2638
[2/5][0/1583] Loss_D: 0.4752 Loss_G: 2.5540 D(x): 0.7200 D(G(z)): 0.1000 / 0.1069
[2/5][50/1583] Loss_D: 0.6896 Loss_G: 4.0186 D(x): 0.9146 D(G(z)): 0.4075 / 0.0264
[2/5][100/1583] Loss_D: 1.3132 Loss_G: 5.3432 D(x): 0.9627 D(G(z)): 0.6377 / 0.0098
[2/5][150/1583] Loss_D: 0.7652 Loss_G: 4.0374 D(x): 0.9082 D(G(z)): 0.4360 / 0.0274
[2/5][200/1583] Loss_D: 2.3951 Loss_G: 4.4238 D(x): 0.9577 D(G(z)): 0.8319 / 0.0268
[2/5][250/1583] Loss_D: 0.6603 Loss_G: 3.8084 D(x): 0.8973 D(G(z)): 0.3810 / 0.0334
[2/5][300/1583] Loss_D: 0.5613 Loss_G: 1.8718 D(x): 0.6674 D(G(z)): 0.0894 / 0.2089
[2/5][350/1583] Loss_D: 0.7528 Loss_G: 1.7309 D(x): 0.5989 D(G(z)): 0.1279 / 0.2183
[2/5][400/1583] Loss_D: 0.7801 Loss_G: 4.1814 D(x): 0.9042 D(G(z)): 0.4489 / 0.0216
[2/5][450/1583] Loss_D: 0.5258 Loss_G: 2.4628 D(x): 0.8261 D(G(z)): 0.2513 / 0.1138
[2/5][500/1583] Loss_D: 0.5361 Loss_G: 2.7942 D(x): 0.8242 D(G(z)): 0.2542 / 0.0755
[2/5][550/1583] Loss_D: 1.6421 Loss_G: 1.7626 D(x): 0.2621 D(G(z)): 0.0155 / 0.2570
[2/5][600/1583] Loss_D: 1.6040 Loss_G: 4.4201 D(x): 0.9520 D(G(z)): 0.7247 / 0.0253
[2/5][650/1583] Loss_D: 0.6634 Loss_G: 1.0870 D(x): 0.6396 D(G(z)): 0.1235 / 0.3833
[2/5][700/1583] Loss_D: 0.6952 Loss_G: 1.3777 D(x): 0.6367 D(G(z)): 0.1495 / 0.3032
[2/5][750/1583] Loss_D: 1.2731 Loss_G: 3.7225 D(x): 0.8514 D(G(z)): 0.5966 / 0.0421
[2/5][800/1583] Loss_D: 0.5894 Loss_G: 2.4485 D(x): 0.6314 D(G(z)): 0.0567 / 0.1139
[2/5][850/1583] Loss_D: 0.7935 Loss_G: 2.9245 D(x): 0.8093 D(G(z)): 0.3905 / 0.0724
[2/5][900/1583] Loss_D: 0.4361 Loss_G: 2.2168 D(x): 0.8140 D(G(z)): 0.1795 / 0.1367
[2/5][950/1583] Loss_D: 1.3334 Loss_G: 4.3800 D(x): 0.9279 D(G(z)): 0.6277 / 0.0197
[2/5][1000/1583] Loss_D: 0.6805 Loss_G: 1.5319 D(x): 0.5876 D(G(z)): 0.0758 / 0.2571
[2/5][1050/1583] Loss_D: 0.7445 Loss_G: 2.5540 D(x): 0.7508 D(G(z)): 0.3165 / 0.0995
[2/5][1100/1583] Loss_D: 0.5243 Loss_G: 3.6964 D(x): 0.9495 D(G(z)): 0.3493 / 0.0338
[2/5][1150/1583] Loss_D: 0.4806 Loss_G: 2.2581 D(x): 0.7699 D(G(z)): 0.1702 / 0.1325
[2/5][1200/1583] Loss_D: 0.6490 Loss_G: 4.2269 D(x): 0.9521 D(G(z)): 0.4121 / 0.0203
[2/5][1250/1583] Loss_D: 0.5408 Loss_G: 2.4637 D(x): 0.8213 D(G(z)): 0.2640 / 0.1081
[2/5][1300/1583] Loss_D: 0.6561 Loss_G: 2.2401 D(x): 0.6666 D(G(z)): 0.1593 / 0.1366
[2/5][1350/1583] Loss_D: 0.5151 Loss_G: 2.2296 D(x): 0.8063 D(G(z)): 0.2255 / 0.1359
[2/5][1400/1583] Loss_D: 0.6335 Loss_G: 2.9247 D(x): 0.7767 D(G(z)): 0.2745 / 0.0685
[2/5][1450/1583] Loss_D: 0.4867 Loss_G: 2.8086 D(x): 0.7687 D(G(z)): 0.1665 / 0.0778
[2/5][1500/1583] Loss_D: 0.6379 Loss_G: 4.2642 D(x): 0.9216 D(G(z)): 0.3926 / 0.0191
[2/5][1550/1583] Loss_D: 0.5921 Loss_G: 3.1926 D(x): 0.7611 D(G(z)): 0.2263 / 0.0613
[3/5][0/1583] Loss_D: 1.2318 Loss_G: 0.7640 D(x): 0.3492 D(G(z)): 0.0328 / 0.5032
[3/5][50/1583] Loss_D: 0.6451 Loss_G: 1.6483 D(x): 0.6700 D(G(z)): 0.1733 / 0.2371
[3/5][100/1583] Loss_D: 0.8808 Loss_G: 4.0251 D(x): 0.9346 D(G(z)): 0.5067 / 0.0241
[3/5][150/1583] Loss_D: 0.6102 Loss_G: 3.1700 D(x): 0.9058 D(G(z)): 0.3619 / 0.0537
[3/5][200/1583] Loss_D: 0.9629 Loss_G: 0.8192 D(x): 0.5441 D(G(z)): 0.2097 / 0.4843
[3/5][250/1583] Loss_D: 0.5453 Loss_G: 2.3836 D(x): 0.7518 D(G(z)): 0.1894 / 0.1145
[3/5][300/1583] Loss_D: 0.6647 Loss_G: 2.8415 D(x): 0.8874 D(G(z)): 0.3819 / 0.0767
[3/5][350/1583] Loss_D: 1.2558 Loss_G: 1.1806 D(x): 0.4463 D(G(z)): 0.1996 / 0.3861
[3/5][400/1583] Loss_D: 0.7637 Loss_G: 1.7397 D(x): 0.5169 D(G(z)): 0.0291 / 0.2332
[3/5][450/1583] Loss_D: 2.0198 Loss_G: 6.1432 D(x): 0.9719 D(G(z)): 0.8113 / 0.0039
[3/5][500/1583] Loss_D: 1.3090 Loss_G: 0.7428 D(x): 0.3413 D(G(z)): 0.0593 / 0.5127
[3/5][550/1583] Loss_D: 0.5260 Loss_G: 2.7581 D(x): 0.8621 D(G(z)): 0.2841 / 0.0839
[3/5][600/1583] Loss_D: 0.6147 Loss_G: 2.6217 D(x): 0.7316 D(G(z)): 0.2218 / 0.0941
[3/5][650/1583] Loss_D: 0.6390 Loss_G: 2.2976 D(x): 0.7642 D(G(z)): 0.2694 / 0.1307
[3/5][700/1583] Loss_D: 0.7519 Loss_G: 1.5898 D(x): 0.5340 D(G(z)): 0.0444 / 0.2489
[3/5][750/1583] Loss_D: 0.8697 Loss_G: 1.3429 D(x): 0.5113 D(G(z)): 0.0875 / 0.3153
[3/5][800/1583] Loss_D: 0.5610 Loss_G: 2.1159 D(x): 0.7029 D(G(z)): 0.1395 / 0.1538
[3/5][850/1583] Loss_D: 1.0736 Loss_G: 3.8184 D(x): 0.8837 D(G(z)): 0.5680 / 0.0310
[3/5][900/1583] Loss_D: 0.5445 Loss_G: 2.1257 D(x): 0.7326 D(G(z)): 0.1670 / 0.1513
[3/5][950/1583] Loss_D: 0.6790 Loss_G: 1.8632 D(x): 0.5934 D(G(z)): 0.0853 / 0.1974
[3/5][1000/1583] Loss_D: 1.9040 Loss_G: 0.2843 D(x): 0.2016 D(G(z)): 0.0229 / 0.7843
[3/5][1050/1583] Loss_D: 0.5400 Loss_G: 2.3306 D(x): 0.7494 D(G(z)): 0.1853 / 0.1260
[3/5][1100/1583] Loss_D: 0.5972 Loss_G: 2.8698 D(x): 0.8615 D(G(z)): 0.3202 / 0.0718
[3/5][1150/1583] Loss_D: 1.0519 Loss_G: 0.5744 D(x): 0.4465 D(G(z)): 0.1017 / 0.6000
[3/5][1200/1583] Loss_D: 0.6423 Loss_G: 2.8701 D(x): 0.8010 D(G(z)): 0.2993 / 0.0730
[3/5][1250/1583] Loss_D: 0.6473 Loss_G: 2.4524 D(x): 0.7487 D(G(z)): 0.2464 / 0.1301
[3/5][1300/1583] Loss_D: 0.7002 Loss_G: 1.6933 D(x): 0.5929 D(G(z)): 0.1050 / 0.2358
[3/5][1350/1583] Loss_D: 0.6894 Loss_G: 1.7195 D(x): 0.6930 D(G(z)): 0.2255 / 0.2252
[3/5][1400/1583] Loss_D: 0.9255 Loss_G: 0.9604 D(x): 0.5074 D(G(z)): 0.1053 / 0.4271
[3/5][1450/1583] Loss_D: 0.5133 Loss_G: 1.8800 D(x): 0.7076 D(G(z)): 0.1195 / 0.1818
[3/5][1500/1583] Loss_D: 0.6771 Loss_G: 3.4659 D(x): 0.9012 D(G(z)): 0.3987 / 0.0460
[3/5][1550/1583] Loss_D: 0.5520 Loss_G: 2.6518 D(x): 0.8005 D(G(z)): 0.2438 / 0.0905
[4/5][0/1583] Loss_D: 0.5628 Loss_G: 1.7902 D(x): 0.7213 D(G(z)): 0.1743 / 0.1971
[4/5][50/1583] Loss_D: 0.7199 Loss_G: 1.0554 D(x): 0.5796 D(G(z)): 0.0930 / 0.3983
[4/5][100/1583] Loss_D: 0.6448 Loss_G: 1.8463 D(x): 0.6001 D(G(z)): 0.0601 / 0.1977
[4/5][150/1583] Loss_D: 0.4893 Loss_G: 2.4879 D(x): 0.7848 D(G(z)): 0.1910 / 0.1006
[4/5][200/1583] Loss_D: 1.7806 Loss_G: 0.7902 D(x): 0.2709 D(G(z)): 0.0612 / 0.5322
[4/5][250/1583] Loss_D: 0.4679 Loss_G: 2.3013 D(x): 0.7938 D(G(z)): 0.1837 / 0.1333
[4/5][300/1583] Loss_D: 0.6849 Loss_G: 3.8390 D(x): 0.8984 D(G(z)): 0.3986 / 0.0290
[4/5][350/1583] Loss_D: 0.8600 Loss_G: 4.1942 D(x): 0.8836 D(G(z)): 0.4651 / 0.0221
[4/5][400/1583] Loss_D: 0.4965 Loss_G: 2.1448 D(x): 0.7545 D(G(z)): 0.1588 / 0.1483
[4/5][450/1583] Loss_D: 0.5851 Loss_G: 2.0878 D(x): 0.6979 D(G(z)): 0.1532 / 0.1675
[4/5][500/1583] Loss_D: 0.6493 Loss_G: 1.4808 D(x): 0.6351 D(G(z)): 0.1297 / 0.2768
[4/5][550/1583] Loss_D: 2.0527 Loss_G: 0.8802 D(x): 0.1726 D(G(z)): 0.0080 / 0.4685
[4/5][600/1583] Loss_D: 0.5884 Loss_G: 2.0371 D(x): 0.7417 D(G(z)): 0.2189 / 0.1508
[4/5][650/1583] Loss_D: 1.0315 Loss_G: 3.0950 D(x): 0.9017 D(G(z)): 0.5481 / 0.0688
[4/5][700/1583] Loss_D: 0.4531 Loss_G: 2.2834 D(x): 0.7699 D(G(z)): 0.1516 / 0.1237
[4/5][750/1583] Loss_D: 0.5399 Loss_G: 3.1644 D(x): 0.8073 D(G(z)): 0.2342 / 0.0566
[4/5][800/1583] Loss_D: 0.7427 Loss_G: 1.7710 D(x): 0.5645 D(G(z)): 0.0904 / 0.2301
[4/5][850/1583] Loss_D: 1.3694 Loss_G: 1.0101 D(x): 0.3654 D(G(z)): 0.0765 / 0.4285
[4/5][900/1583] Loss_D: 1.1275 Loss_G: 3.1603 D(x): 0.9133 D(G(z)): 0.5724 / 0.0679
[4/5][950/1583] Loss_D: 0.5287 Loss_G: 2.5148 D(x): 0.8320 D(G(z)): 0.2618 / 0.1020
[4/5][1000/1583] Loss_D: 0.6012 Loss_G: 2.1862 D(x): 0.6534 D(G(z)): 0.1075 / 0.1491
[4/5][1050/1583] Loss_D: 0.5064 Loss_G: 2.5518 D(x): 0.8703 D(G(z)): 0.2817 / 0.0988
[4/5][1100/1583] Loss_D: 0.4344 Loss_G: 3.2885 D(x): 0.9171 D(G(z)): 0.2704 / 0.0531
[4/5][1150/1583] Loss_D: 0.6307 Loss_G: 2.9836 D(x): 0.7885 D(G(z)): 0.2874 / 0.0627
[4/5][1200/1583] Loss_D: 0.3780 Loss_G: 2.0650 D(x): 0.8246 D(G(z)): 0.1493 / 0.1565
[4/5][1250/1583] Loss_D: 0.5256 Loss_G: 2.6429 D(x): 0.8723 D(G(z)): 0.2968 / 0.0947
[4/5][1300/1583] Loss_D: 1.0447 Loss_G: 4.4796 D(x): 0.9758 D(G(z)): 0.5853 / 0.0169
[4/5][1350/1583] Loss_D: 0.6979 Loss_G: 3.2359 D(x): 0.8866 D(G(z)): 0.3950 / 0.0546
[4/5][1400/1583] Loss_D: 0.7496 Loss_G: 4.4662 D(x): 0.9543 D(G(z)): 0.4623 / 0.0160
[4/5][1450/1583] Loss_D: 0.6232 Loss_G: 1.2068 D(x): 0.6431 D(G(z)): 0.1035 / 0.3470
[4/5][1500/1583] Loss_D: 0.5324 Loss_G: 2.5265 D(x): 0.7611 D(G(z)): 0.1882 / 0.1052
[4/5][1550/1583] Loss_D: 0.6219 Loss_G: 2.1069 D(x): 0.6739 D(G(z)): 0.1602 / 0.1562
결과
결과를 알아봅시다. 이 섹션에서는 총 세가지를 확인할겁니다. 첫번째는 G와 D의 손실값들이 어떻게 변했는가, 두번째는 매 에폭마다 fixed_noise를 이용해 G가 만들어낸 이미지들, 마지막은 학습이 끝난 G가 만들어낸 이미지와 진짜 이미지들의 비교입니다
학습하는 동안의 손실값들
아래는 D와 G의 손실값들을 그래프로 그린 모습입니다
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
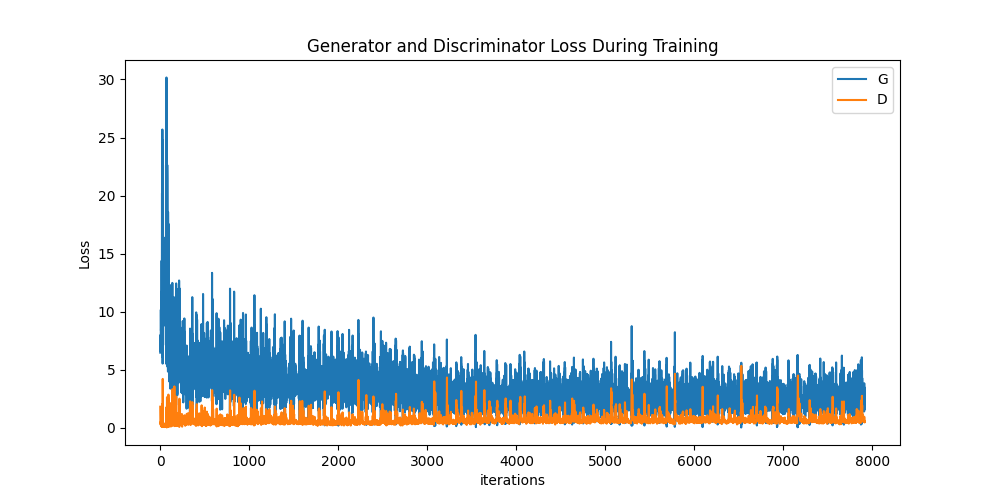
G의 학습 과정 시각화
매 에폭마다 fixed_noise를 이용해 생성자가 만들어낸 이미지를 저장한 것을 기억할겁니다. 저장한 이미지들을애니메이션 형식으로 확인해 봅시다. play버튼을 누르면 애니매이션이 실행됩니다
#%%capture
fig = plt.figure(figsize=(8,8))
plt.axis("off")
ims = [[plt.imshow(np.transpose(i,(1,2,0)), animated=True)] for i in img_list]
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
HTML(ani.to_jshtml())

진짜 이미지 vs. 가짜 이미지
진짜 이미지들과 가짜 이미지들을 옆으로 두고 비교를 해봅시다
# dataloader에서 진짜 데이터들을 가져옵니다
real_batch = next(iter(dataloader))
# 진짜 이미지들을 화면에 출력합니다
plt.figure(figsize=(15,15))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))
# 가짜 이미지들을 화면에 출력합니다
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1],(1,2,0)))
plt.show()

이제 어디로 여행을 떠나볼까요?
드디어 DCGAN이 끝났습니다! 하지만 더 알아볼 것들이 많이 남아있죠. 무엇을 더 시도해볼 수 있을까요?
-
결과물이 얼마나 더 좋아지는지 확인해보기 위해서 학습시간을 늘려볼 수 있습니다
-
다른 데이터셋을 이용해 훈련시켜보거나, 이미지의 사이즈를 다르게 해보거나, 아키텍쳐의 구성을 바꿔볼 수도 있습니다
-
여기 에서 더욱 멋진 GAN 프로젝트들을 찾을수도 있죠
-
음악 을 작곡하는 GAN도 만들 수 있습니다
Total running time of the script: ( 11 minutes 7.000 seconds)
[출처] https://tutorials.pytorch.kr/beginner/dcgan_faces_tutorial.html
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.