
- 전체
- Sample DB
- database modeling
- [표준 SQL] Standard SQL
- G-SQL
- 10-Min
- ORACLE
- MS SQLserver
- MySQL
- SQLite
- postgreSQL
- 데이터아키텍처전문가 - 국가공인자격
- 데이터 분석 전문가 [ADP]
- [국가공인] SQL 개발자/전문가
- NoSQL
- hadoop
- hadoop eco system
- big data (빅데이터)
- stat(통계) R 언어
- XML DB & XQuery
- spark
- DataBase Tool
- 데이터분석 & 데이터사이언스
- Engineer Quality Management
- [기계학습] machine learning
- 데이터 수집 및 전처리
- 국가기술자격 빅데이터분석기사
- 암호화폐 (비트코인, cryptocurrency, bitcoin)
[기계학습] machine learning [기계학습][머신러닝][딥러닝] Generative Adversarial Net (GAN) PyTorch 구현: 손글씨 생성
2022.11.08 20:26
[기계학습][머신러닝][딥러닝] Generative Adversarial Net (GAN) PyTorch 구현: 손글씨 생성
Generative Adversarial Net (GAN) PyTorch 구현: 손글씨 생성
20 Feb 2019
이번 포스트에서는 PyTorch를 이용하여 GAN(Generative Adversarial Network)을 구현하여 MNIST 데이터를 생성해보는 튜토리얼을 다룹니다. MNIST 데이터는 간단히 말해 0부터 9까지의 숫자를 손글씨로 적은 이미지와 그에 대한 레이블 페어로 이루어진 총 7만개의 데이터셋입니다.
이 포스트는 Naver CLOVA 최윤제 연구원님의 튜토리얼을 참조하여 만들었습니다.
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.utils as utils
import torchvision.datasets as dsets
import torchvision.transforms as transforms
is_cuda = torch.cuda.is_available()
device = torch.device('cuda' if is_cuda else 'cpu')
MNIST Data Loader
먼저 PyTorch 라이브러리를 이용하여 MNIST 데이터를 다운받고, 이를 이용하여 batch size가 200인 Data Loader를 만들어보겠습니다. 이에 대한 자세한 내용은 지난 포스트를 참조해주세요.
# standardization code
standardizator = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), # 3 for RGB channels이나 실제론 gray scale
std=(0.5, 0.5, 0.5))]) # 3 for RGB channels이나 실제론 gray scale
# MNIST dataset
train_data = dsets.MNIST(root='data/', train=True, transform=standardizator, download=True)
test_data = dsets.MNIST(root='data/', train=False, transform=standardizator, download=True)
batch_size = 200
train_data_loader = torch.utils.data.DataLoader(train_data, batch_size, shuffle=True)
test_data_loader = torch.utils.data.DataLoader(test_data, batch_size, shuffle=True)
하나의 미니배치를 뽑고, 그 중 16개만 가시화해보겠습니다.
import numpy as np
from matplotlib import pyplot as plt
def imshow(img):
img = (img+1)/2
img = img.squeeze()
np_img = img.numpy()
plt.imshow(np_img, cmap='gray')
plt.show()
def imshow_grid(img):
img = utils.make_grid(img.cpu().detach())
img = (img+1)/2
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1,2,0)))
plt.show()
example_mini_batch_img, example_mini_batch_label = next(iter(train_data_loader))
imshow_grid(example_mini_batch_img[0:16,:,:])

Generative Adversarial Network - 이론
GAN에 대한 이론적 설명은 최윤제 연구원님의 슬라이드 및 발표자료에 매우 자세히 나와있습니다.
이상적인 Discriminator인 D*에 대한 개인적인 생각만 첨언해보겠습니다.
TL;DR: D*는 다음과 같이 조건부확률로서도 해석할 수도 있을 것 같다.
- 다음과 같은 두가지 사건을 정의해보자.
- 실제 데이터에서 임의로 한 데이터를 선택하는 사건 A
- G를 이용해 임의로 하나의 데이터를 생성하는 사건 B
그렇다면,
- 그러나
- P(A)+P(B)=1이고,
- P(A)와 P(B)간의 prior는 논문에서 딱희 정의되지 않으며, 동등하다고 보는 것이 자연스러우므로,
- P(A)=P(B)=0.5로 가정해도 일관성을 잃지 않는다.
따라서
이다.
다만 이 D*는 증명을 위한 이론 값일 뿐, 실제로 구현할 수 조차 없다. 이유는 GAN의 경우 임의에 x 대한 p_data(x)는 물론이고 p_g(x) 조차 직접적인 추론을 할 수 없는 구조이기 때문
첨언에 대한 2020년의 작성자 주석) GAN 공부할 때 쓴 첨언인데 지금보니 개소리 같기도 하고 아닌거 같기도 하고 과거의 나한데 설득되고 있다. 혼란스럽다. 다만 저게 말이 되려면 문제 상황을 조금 수정해야할 것 같다. turing test같이 x를 누군가가 반반의 확률로 임의로 던져주었다고 가정을 했을 때 이상적인 (또는 확률론적인) 를 저런 방식으로 해석할 수도 있을 것 같다.
GAN 구현하기
아주 간단한 MLP(Multi-Layer Perceptron)으로 Generator G를 구현해보겠습니다.
G는 100차원의 가우시안 디스트리뷰션에서 샘플링한 노이즈 z를 이용하여 MNIST 데이터를 만들어내는 MLP입니다.
d_noise = 100
d_hidden = 256
def sample_z(batch_size = 1, d_noise=100):
return torch.randn(batch_size, d_noise, device=device)
G = nn.Sequential(
nn.Linear(d_noise, d_hidden),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(d_hidden,d_hidden),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(d_hidden, 28*28),
nn.Tanh()
).to(device)
# 노이즈 생성하기
z = sample_z()
# 가짜 이미지 생성하기
img_fake = G(z).view(-1,28,28)
# 이미지 출력하기
imshow(img_fake.squeeze().cpu().detach())
# Batch SIze만큼 노이즈 생성하여 그리드로 출력하기
z = sample_z(batch_size)
img_fake = G(z)
imshow_grid(img_fake)


학습이 되기 전이라, 의미 없는 데이터를 만들어 냅니다.


이번에는 주어진 이미지가 실제 데이터인지 아니면 G에 의해 만들어진 데이터인지 판별하는 Discriminator D를 만들어보겠습니다.
D = nn.Sequential(
nn.Linear(28*28, d_hidden),
nn.LeakyReLU(),
nn.Dropout(0.1),
nn.Linear(d_hidden, d_hidden),
nn.LeakyReLU(),
nn.Dropout(0.1),
nn.Linear(d_hidden, 1),
nn.Sigmoid()
).to(device)
print(G(z).shape)
print(D(G(z)).shape)
print(D(G(z)[0:5]).transpose(0,1))
torch.Size([200, 784])
torch.Size([200, 1])
tensor([[0.4965, 0.4984, 0.4948, 0.4938, 0.4918]], device='cuda:0',
grad_fn=<TransposeBackward0>)
GAN 훈련시키기
criterion = nn.BCELoss()
def run_epoch(generator, discriminator, _optimizer_g, _optimizer_d):
generator.train()
discriminator.train()
for img_batch, label_batch in train_data_loader:
img_batch, label_batch = img_batch.to(device), label_batch.to(device)
# ================================================ #
# maximize V(discriminator,generator) = optimize discriminator (setting k to be 1) #
# ================================================ #
# init optimizer
_optimizer_d.zero_grad()
p_real = discriminator(img_batch.view(-1, 28*28))
p_fake = discriminator(generator(sample_z(batch_size, d_noise)))
# ================================================ #
# Loss computation (soley based on the paper) #
# ================================================ #
loss_real = -1 * torch.log(p_real) # -1 for gradient ascending
loss_fake = -1 * torch.log(1.-p_fake) # -1 for gradient ascending
loss_d = (loss_real + loss_fake).mean()
# ================================================ #
# Loss computation (based on Cross Entropy) #
# ================================================ #
# loss_d = criterion(p_real, torch.ones_like(p_real).to(device)) + \ #
# criterion(p_fake, torch.zeros_like(p_real).to(device)) #
# Update parameters
loss_d.backward()
_optimizer_d.step()
# ================================================ #
# minimize V(discriminator,generator) #
# ================================================ #
# init optimizer
_optimizer_g.zero_grad()
p_fake = discriminator(generator(sample_z(batch_size, d_noise)))
# ================================================ #
# Loss computation (soley based on the paper) #
# ================================================ #
# instead of: torch.log(1.-p_fake).mean() <- explained in Section 3
loss_g = -1 * torch.log(p_fake).mean()
# ================================================ #
# Loss computation (based on Cross Entropy) #
# ================================================ #
# loss_g = criterion(p_fake, torch.ones_like(p_fake).to(device)) #
loss_g.backward()
# Update parameters
_optimizer_g.step()
def evaluate_model(generator, discriminator):
p_real, p_fake = 0.,0.
generator.eval()
discriminator.eval()
for img_batch, label_batch in test_data_loader:
img_batch, label_batch = img_batch.to(device), label_batch.to(device)
with torch.autograd.no_grad():
p_real += (torch.sum(discriminator(img_batch.view(-1, 28*28))).item())/10000.
p_fake += (torch.sum(discriminator(generator(sample_z(batch_size, d_noise)))).item())/10000.
return p_real, p_fake
보통 다른 튜토리얼에서는 torch에서 제공해주는 BCELoss(Binary Cross Entropy Loss)를 이용하여 구현합니다. 이 코드에서는 조금 더 원논문에 가까운 표현을 위해 직접 로스값을 하드코딩해주었습니다.
코드를 실행시켜 학습이 제대로 되는지 확인해보겠습니다.
def init_params(model):
for p in model.parameters():
if(p.dim() > 1):
nn.init.xavier_normal_(p)
else:
nn.init.uniform_(p, 0.1, 0.2)
init_params(G)
init_params(D)
optimizer_g = optim.Adam(G.parameters(), lr = 0.0002)
optimizer_d = optim.Adam(D.parameters(), lr = 0.0002)
p_real_trace = []
p_fake_trace = []
for epoch in range(200):
run_epoch(G, D, optimizer_g, optimizer_d)
p_real, p_fake = evaluate_model(G,D)
p_real_trace.append(p_real)
p_fake_trace.append(p_fake)
if((epoch+1)% 50 == 0):
print('(epoch %i/200) p_real: %f, p_g: %f' % (epoch+1, p_real, p_fake))
imshow_grid(G(sample_z(16)).view(-1, 1, 28, 28))
(epoch 50/200) p_real: 0.739482, p_g: 0.231452

(epoch 100/200) p_real: 0.632178, p_g: 0.219324

(epoch 150/200) p_real: 0.606782, p_g: 0.295501
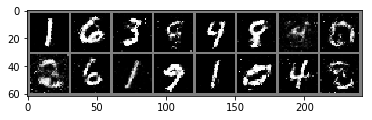
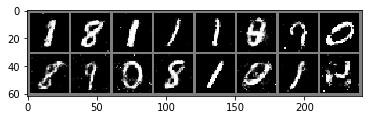
(epoch 200/200) p_real: 0.619400, p_g: 0.373423
D가 실제 데이터 x_real을 실제 데이터라고 판별할 확률 D(x_real)과 G에 의해 생성된 이미지인 x_generated를 실제 데이터라고 판별할 확률을 D(x_generated)라고 두겠습니다. 학습이 진행됨에 따라 이 값들이 어떻게 바뀌는가를 살펴보시겠습니다.
plt.plot(p_fake_trace, label='D(x_generated)')
plt.plot(p_real_trace, label='D(x_real)')
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
plt.show()
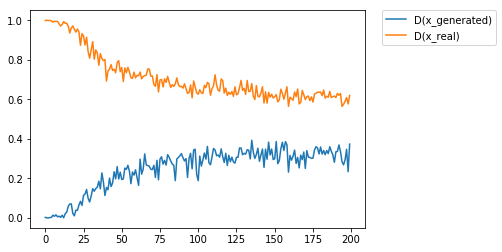
두 값이 점차 0.5로 수렴해가는 것을 확인하실 수 있습니다.
이번에는 실제이미지와 G가 만들어내는 이미지를 확인해보겠습니다. 두 그림들이 얼추 비슷해 보입니다.
vis_loader = torch.utils.data.DataLoader(test_data, 16, True)
img_vis, label_vis = next(iter(vis_loader))
imshow_grid(img_vis)
imshow_grid(G(sample_z(16,100)).view(-1, 1, 28, 28))


지금까지 GAN 튜토리얼을 살펴보았습니다.
[출처] https://ws-choi.github.io/blog-kor/seminar/tutorial/mnist/pytorch/gan/GAN-%ED%8A%9C%ED%86%A0%EB%A6%AC%EC%96%BC/
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.