
- 전체
- Sample DB
- database modeling
- [표준 SQL] Standard SQL
- G-SQL
- 10-Min
- ORACLE
- MS SQLserver
- MySQL
- SQLite
- postgreSQL
- 데이터아키텍처전문가 - 국가공인자격
- 데이터 분석 전문가 [ADP]
- [국가공인] SQL 개발자/전문가
- NoSQL
- hadoop
- hadoop eco system
- big data (빅데이터)
- stat(통계) R 언어
- XML DB & XQuery
- spark
- DataBase Tool
- 데이터분석 & 데이터사이언스
- Engineer Quality Management
- [기계학습] machine learning
- 데이터 수집 및 전처리
- 국가기술자격 빅데이터분석기사
- 암호화폐 (비트코인, cryptocurrency, bitcoin)
[기계학습] [번역] TensorFlow Lite 튜토리얼 1 부 : Wake Word 기능 추출
 기계 학습 (ML)은 기술 커뮤니티에서 관심을 끌고 있으며 현재 TensorFlow가 가장 인기있는 프레임워크인 것 같습니다. ML에 내장형 장치를 사용하는 것은 여전히 새롭고 “TensorFlow Lite”라고 하는 TensorFlow의 하위 집합이 출시되어 단일 보드 컴퓨터 및 마이크로컨트롤러와 같은 더 작고 전력이 낮은 장치에서 모델의 추론을 실행할 수 있습니다.
기계 학습 (ML)은 기술 커뮤니티에서 관심을 끌고 있으며 현재 TensorFlow가 가장 인기있는 프레임워크인 것 같습니다. ML에 내장형 장치를 사용하는 것은 여전히 새롭고 “TensorFlow Lite”라고 하는 TensorFlow의 하위 집합이 출시되어 단일 보드 컴퓨터 및 마이크로컨트롤러와 같은 더 작고 전력이 낮은 장치에서 모델의 추론을 실행할 수 있습니다.
다음 몇 가지 자습서를 통해 오디오 파일에서 기능을 추출하고, CNN (Convolutional Neural Network) 모델을 훈련하여 많은 음성 단어를 감지하고 해당 모델을 Raspberry Pi에 배포하여 해당 단어를 실제로 감지합니다.
이 튜토리얼에서는 MFCC (Mel Frequency Cepstral Coefficients)의 개념과 Python 라이브러리를 사용하여 계산하는 방법을 소개합니다. 우리는 MFCC 샘플로 구성된 일련의 학습 데이터를 생성하고 다음 튜토리얼에서 CNN에 공급할 것입니다.
이 학습서에 포함 된 정보는 비디오 형식으로도 볼 수 있습니다.

전제 조건
이 학습서를 시작하기 전에 몇 가지 태스크를 수행해야 합니다.
- Edge AI (Edge 인공 지능)에 대한 소개가 필요한 경우 이 자습서를 검토하는 것이 좋습니다.
- 데스크탑 또는 랩톱에 TensorFlow, Keras, Python 및 Jupyter Notebook이 설치되어 있어야 합니다. 이 튜토리얼에서는 이를 수행하는 단계를 안내합니다.
또는, Google Colab을 사용하여 Google 서버에서 Jupyter Notebook을 실행할 수 있지만 파일 (예 : 교육 샘플)을 로드하려면 파일을 Google 드라이브에 업로드하고 다른 코드를 작성하여 프로그램으로 가져와야 합니다. 이 안내서는 Colab에서 파일을 로드하는 방법에 대한 팁을 제공합니다.
개요
모델을 교육하고 배포하는 방법에 대한 전체 프로세스는 초보자에게 혼란을 줄 수 있습니다. 우리는 그것이 어떻게 작동하는지에 대한 광범위한 개요를 제공할 수 있기를 바랍니다.
시작하기 전에 해결하고자하는 문제를 파악하고 스스로에게 묻고 싶을 것입니다. 문제를 해결하려면 기계 학습이 필요한가요? 그렇다면 일반적으로 고려해야 할 4 가지 단계가 있습니다.
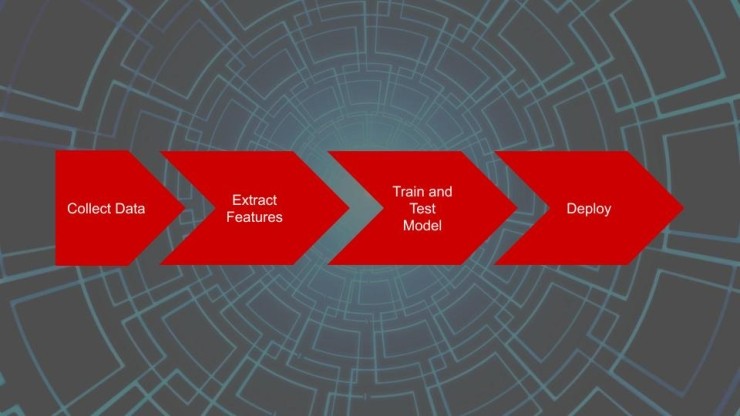
첫째, 필요한 것보다 많은 데이터를 수집해야 합니다. 심층 신경망을 훈련시키려는 경우, 수천 또는 수십만 개의 샘플이 종종 필요합니다.
둘째, 샘플에서 피처를 추출하는 데 시간을 소비해야 합니다. 종종 원시 형식의 데이터는 기계 학습 모델에서 사용할 수 없으므로 데이터를 사용 가능한 것으로 변환해야 합니다. 여기에는 신호의 스펙트럼 및 전력 성분을 검사하기 위해 푸리에 변환을 수행하거나, 단어를 숫자로 인코딩하거나, 이미지를 별도의 색상 채널로 분리하는 것과 같은 것들이 포함될 수 있습니다.
기능을 통해 모델을 학습할 수 있습니다. 여기에는 역전달과 같은 하나 이상의 알고리즘을 실행하여 예측이 예상 결과와 더 밀접하게 일치하도록 모델의 매개 변수(가중치 및 바이어스 항)를 자동으로 업데이트 합니다. 원하는 모델 정확도를 달성하기 위해 다른 모델을 시도하거나 다양한 하이퍼파라미터(사용된 기능 유형 및 사용 된 모델의 크기 및 모양과 같은 훈련 전에 설정 한 값)를 조정해야 할 수도 있습니다.
완전히 훈련된 모델이 있고 보이지 않는 데이터에서 수행되는 방식에 만족하면 프로덕션 환경에 배포할 수 있습니다. 이 튜토리얼 시리즈에서는 모델 파일(.h5)을 TensorFlow Lite 모델 파일(.tflite)로 변환하고 Raspberry Pi로 복사합니다. 그런 다음 TensorFlow Lite 추론 엔진을 사용하여 모델을 실시간으로 예측합니다.
데이터 수집
운 좋게도 수동으로 데이터를 수집할 필요가 없습니다. Google은 이미 다른 단어를 사용하는 사람들의 수천 개의 1 초 오디오 클립으로 구성된 Google 음성 명령 데이터 세트에서 이 작업을 수행했습니다. 이에 대한 자세한 내용을 보거나 자신의 목소리를 높이려면 이 페이지를 참조하십시오!
시작하려면, Google Speech Commands 데이터 셋을 컴퓨터에 다운로드하여 압축을 풉니 다.
고유한 웨이크 단어를 세트에 추가하려면 데이터세트 디렉토리에 폴더를 작성하고 해당 단어를 말하는 사람들의 많은 예를 수집해야 합니다. 단어를 말하는 것만으로도 벗어날 수 있지만 모델이 해당 키워드가 아닌 다른 사람의 목소리를 인식하는 방법을 배울 가능성이 높습니다.
멜 주파수 뇌 계수
시간이 지남에 따라 사운드 클립을 가치의 함수로 보면 아래에 표시된 익숙한 파형 모양( "중지"라고 표시된 1 초 오디오 클립)이 나타납니다. 일부 ML 모델은 이러한 시간 순서 값을 가져와 깨어있는 단어를 식별하는데 사용할 수 있지만, 인간과 같은 방식으로 단어를 듣고 접근하도록 훈련시키는 모델뿐만 아니라 작동하지 않는 것 같습니다.
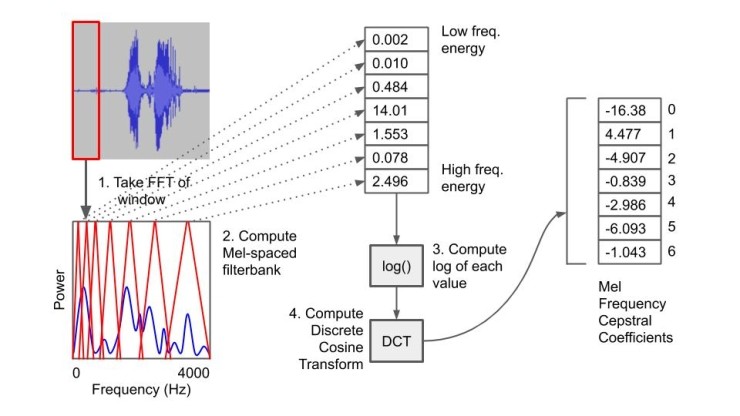
인간으로서, 우리의 귀와 뇌는 일정 기간 동안 주파수를 들음으로써 작동합니다 (음악은 음으로 구성되는 방법에 대해 생각합니다. 짧은 음량의 사운드 주파수 일뿐 입니다). 컴퓨터를 사용하여 주어진 오디오 파일의 이동 창(시간 조각)을 가져 와서 해당 시간 조각의 고속 푸리에 변환(FFT)을 계산합니다. 그것은 우리에게 그 시간 조각에 대한 각 주파수 성분에서의 전력의 표시를 제공합니다.
그런 다음 Mel-spaced 필터 뱅크를 사용하여 해당 전력 그래프를 필터링합니다. 이들은 주파수 스펙트럼에 걸쳐 선형(1 kHz 미만)과 로그 간격(1 kHz 이상) 간격으로 배치되어 사람의 귀가 소리를 인식하는 방법을 모방하는 필터입니다.


각 필터 아래의 에너지가 더해 숫자 벡터를 만듭니다. 대부분의 응용 프로그램에서 이러한 숫자의 로그가 계산되고 벡터에서 이산 코사인 변환(DCT)이 수행됩니다. 이러한 연산의 결과는 MFCC(Mel Frequency Cepstral Coefficient) 항을 제공합니다. 하위 요소(예 : 요소 0 및 1)는 해당 타임 슬라이스에서 스펙트럼의 전체 모양에 대한 정보를 제공하며, 상위 요소(2 이상)가 더 세밀한 세부 정보(노이즈 등)에 대한 정보를 제공합니다.
자동 음성 인식 (ASR)을 위한 대부분의 기계 학습 응용 프로그램에서는 요소 1-13 만 사용됩니다. 다음 자습서에서 신경망을 단순화하기 위해 요소 0-15를 유지합니다. 신경망을 더 빠르고 정확하게 만들 수 있는지 확인하는 데 사용되는 값으로 자유롭게 연주하십시오.
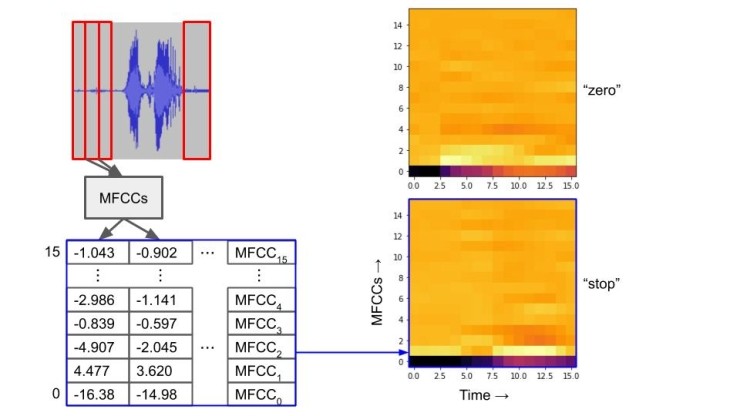
그런 다음 창을 일부 위로 밀고 다음 MFCC 세트를 계산합니다. 특정 오디오 샘플에 대한 모든 MFCC를 계산할 때까지 계속해서 창을 미끄러 뜨립니다. 우리의 목적을 위해, 우리는 시간에 따른 파형의 스펙트럼 형태에 대한 아이디어를 제공하는 16 x 16 배열의 MFCC 값으로 끝납니다.
이 MFCC 배열을 보는 또 다른 방법은 회색조 이미지입니다. 이미지를 보다 쉽게 시각화할 수 있도록 matplotlib에 잘못된 색상을 제공했습니다. 음성 단어 "stop"의 MFCC 이미지를 "zero"와 비교하면 스펙트럼 구성 요소에 차이가 어떻게 나타나는지 알 수 있습니다. 인간이 이러한 차이점을 파악하기 어려울 수 있지만 신경망을 쉽게 훈련시켜 차이점을 식별할 수 있습니다.
이것은 MFCC에 대한 매우 기본적인 개요이며 이들이 유용한 이유입니다. 자세한 내용은 이 기사를 참조하십시오.
Python 스크립트를 실행하여 기능 추출
이러한 기능을 추출하기 위해 pip를 통해 설치할 수 있는 python_speech_features 라이브러리를 사용합니다.
https://github.com/ShawnHymel/tflite-speech-recognition으로 이동하여 Jupyter Notebook 및 Python 파일을 다운로드하십시오. 컴퓨터에서 Jupyter Notebook 세션을 시작하고 01-speech-commands-mfcc-extraction을 엽니다.
첫 번째 셀(또는 노트북 전체)에 나열된 패키지 중 하나가 없는 경우 자체 셀에서 다음을 실행하여 설치할 수 있습니다.
!pip install <name of package>
컴퓨터의 Google 음성 명령 데이터 세트 디렉토리를 가리키도록 dataset_path 변수를 변경하십시오.
한 번에 한 셀씩 노트북을 실행하고 주석 및 출력을 읽고 스크립트에서 발생하는 상황을 파악하는 것이 좋습니다.
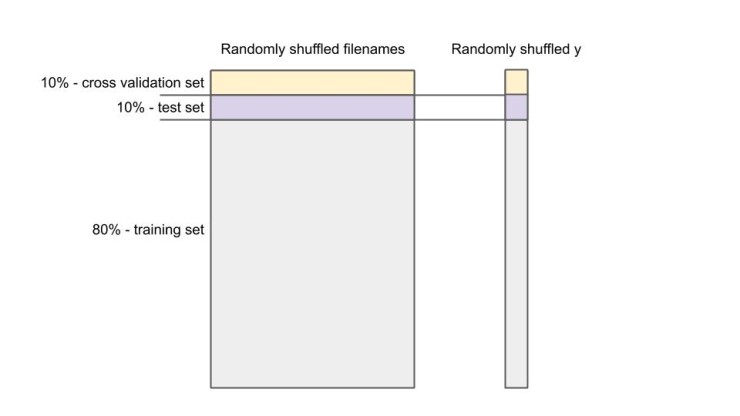
MFCC를 계산하기 전에 먼저 모든 파일 이름을 하나의 긴 목록으로 결합합니다. 그런 다음이 목록을 무작위로 섞고 교차 검증의 경우 10%, 테스트의 경우 10%, 훈련의 경우 80%를 따로 설정합니다. 많은 머신 러닝 프로젝트에서 각 유효성 검사 및 테스트 세트에 대해 10%-20%의 데이터 세트가 제공되는 경우가 종종 있습니다.
이 프로세스의 일부에는 지면 진실 값을 샘플에 연관시키는 것이 포함됩니다. 우리는 각 음성 단어에 숫자 값을 할당해야 하므로 디렉토리의 알파벳 순서로 이동합니다. "뒤로"에는 0이 할당되고 "침대"에는 1이 할당되고 "새"에는 2가 할당됩니다. 이 숫자는 모델 학습 알고리즘에서 예측이 실제 답변과 얼마나 멀리 떨어져 있는지 알기 위해 사용되며 이 손실 값은 모델의 가중치와 바이어스를 업데이트하는데 사용됩니다.
훈련 샘플 세트는 모델 훈련에 사용됩니다. 정확성 또는 손실 점수를 얻기 위해 각 훈련 단계에서 교차 검증이 수행됩니다. 이를 통해 모델이 보이지 않는 데이터(대부분)에서 진행 중인지 알 수 있습니다. 훈련하지 않은 데이터에서도 작동합니까? 마지막으로 테스트 세트는 제쳐두고 끝까지 손대지 않아야 합니다. 철저히 학습한 후에는 모델의 최종 정확도 및 손실 점수를 얻기 위해 이 정보를 사용합니다.
# TEST : Test shorter MFCC라는 스크립트에 도달하면 훈련 세트에서 단일 샘플을 가리키도록 idx 변수를 변경할 수 있습니다. 셀은 컴퓨터의 스피커를 통해 샘플을 재생하고 번호와 이미지 형식의 MFCC를 제공합니다.
# TEST: Test shorter MFCC
# !pip install playsound
from playsound import playsound
idx = 13
# Create path from given filename and target item
path = join(dataset_path, target_list[int(y_orig_train[idx])],
filenames_train[idx])
# Create MFCCs
mfccs = calc_mfcc(path)
print("MFCCs:", mfccs)
# Plot MFCC
fig = plt.figure()
plt.imshow(mfccs, cmap='inferno', origin='lower')
# TEST: Play problem sounds
print(target_list[int(y_orig_train[idx])])
playsound(path)
데이터세트의 일부 샘플이 불완전합니다. 1 초 이내에 멈추거나 손상되었습니다. 파일을 읽을 수 없거나 정확히 16 세트의 MFCC를 생성하지 않으면 샘플을 삭제하면 됩니다. 노이즈에 근사한 값을 제거하거나 패딩하는 것과 같이 잘못된 데이터를 처리하는 방법은 다양하지만 가장 간단한 방법은 나쁜 샘플을 제거하는 것 입니다. 이 음성 명령 데이터세트에는 약 10%의 불량 샘플이 있는 것으로 보이므로 제외하면 다음 교육 단계에서 잘 작동합니다.
모든 좋은 샘플에 대해 MFCC를 계산한 후 all_targets_mfcc_sets.npz 파일에 텐서로 저장합니다.
텐서는 임의의 차원의 숫자 모음입니다. 벡터는 1 차원 텐서, 행렬은 2 차원 텐서 등 입니다.
다음 튜토리얼에서이 파일을 로드하고 포함된 기능을 사용하여 신경망을 훈련시킬 수 있습니다.
더 나아가기
아직 머신 러닝을 수행하지는 않았지만이 튜토리얼에는 여전히 많은 정보가 있습니다. 특징 추출은 ML 프로젝트에서 매우 중요한 부분입니다. 실제로 많은 연구자들은 실제 기계 학습보다 기능 추출에 더 많은 시간을 소비한다고 주장합니다.
다음은 여정에 도움이되는 자료입니다. 다음 자습서에서는 기능을 사용하여 신경망 교육을 다룰 것입니다.
멜 주파수 Cepstral 계수 :
데이터를 교육, 검증 및 테스트 세트로 나누기 :
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.