
- 전체
- Sample DB
- database modeling
- [표준 SQL] Standard SQL
- G-SQL
- 10-Min
- ORACLE
- MS SQLserver
- MySQL
- SQLite
- postgreSQL
- 데이터아키텍처전문가 - 국가공인자격
- 데이터 분석 전문가 [ADP]
- [국가공인] SQL 개발자/전문가
- NoSQL
- hadoop
- hadoop eco system
- big data (빅데이터)
- stat(통계) R 언어
- XML DB & XQuery
- spark
- DataBase Tool
- 데이터분석 & 데이터사이언스
- Engineer Quality Management
- [기계학습] machine learning
- 데이터 수집 및 전처리
- 국가기술자격 빅데이터분석기사
- 암호화폐 (비트코인, cryptocurrency, bitcoin)
[기계학습] [번역] TensorFlow Lite 튜토리얼 2 부 : 음성 인식 모델 교육
 이전 자습서에서는 Google Speech Commands 데이터 세트를 다운로드하고 개별 파일을 읽은 다음 원시 오디오 클립을 Mel Frequency Cepstral Coefficients(MFCC)로 변환했습니다. 또한 이러한 기능을 교육, 교차 검증 및 테스트 세트로 나눕니다. 이러한 기능 세트를 파일로 저장 했으므로 디스크에서 해당 파일을 읽고 모델 교육을 시작할 수 있습니다.
이전 자습서에서는 Google Speech Commands 데이터 세트를 다운로드하고 개별 파일을 읽은 다음 원시 오디오 클립을 Mel Frequency Cepstral Coefficients(MFCC)로 변환했습니다. 또한 이러한 기능을 교육, 교차 검증 및 테스트 세트로 나눕니다. 이러한 기능 세트를 파일로 저장 했으므로 디스크에서 해당 파일을 읽고 모델 교육을 시작할 수 있습니다.
이 자습서에서는 Convolutional Neural Network(CNN)의 작동 방식과 TensorFlow 및 Keras를 사용하여 훈련하는 방법을 간략하게 살펴 보겠습니다. 모델을 하드 디스크에 파일로 저장하여 나중에 실시간 오디오 데이터를 예측하는 데 사용할 수 있습니다.
우리는 또한 여기에서 비디오 형식으로이 내용을 다룹니다 :

개요
수학적 모델 훈련을 통해 말을 분류하는 방법에는 몇 가지가 있습니다. 처음에는 여러 단어 중 하나를 분류한다고 생각할 수 있습니다.
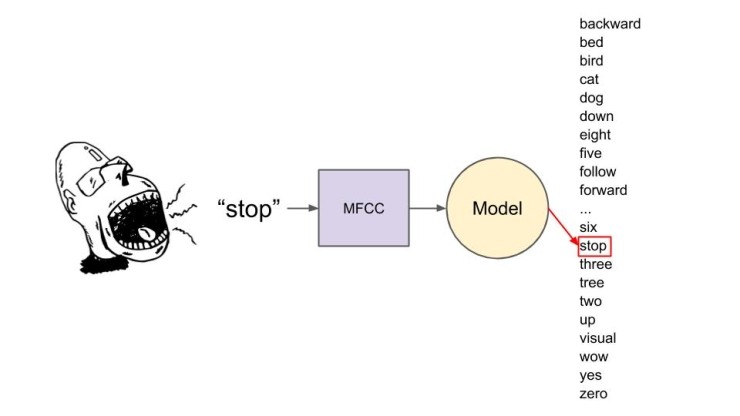
모델을 배포할 때 항상 듣고 있습니다. 들리는 소리의 초마다, 그 소리에 대한 MFCC를 계산하고 그 MFCC 기능을 모델로 보내 예측을 합니다. 모델은 많은 수학을 수행하고 MFCC가 각 클래스에 속한다고 생각하는 신뢰도(또는 확률 수준)를 내뿜습니다.
위의 예에서, 모델은 화자가 여러 단어에서 "stop" 했다고 생각합니다. 이를 범주 분류라고합니다. 이는 로봇을 제어하기 위해 “앞으로” 및 “뒤로”와 같은 여러 키워드를 사용하는데 유용할 수 있지만 한 단어만 신경 쓰면 다른 모든 확률을 계산하기 위해 많은 계산주기를 낭비합니다.
보다 효율적인 모델은 다음과 같습니다.
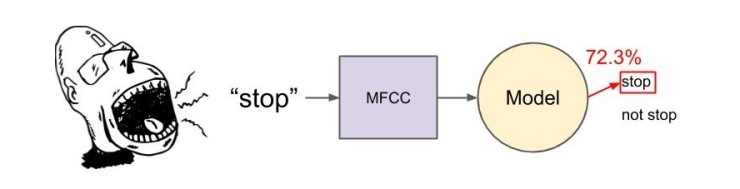
여기서 우리는 화자가 가능한 다른 모든 소리에서 "stop"이라고 말했는지 주의를 기울입니다. 다른 모든 소리와 단어는 단순히 "not stop"으로 분류할 수 있습니다. 이로 인해 많은 계산이 절약되며 가능한 결과가 두 개뿐이므로 이진 분류라고 합니다. 모델의 출력은 단순히 입력 기능이 "stop" 범주에 속하는 것으로 생각되는 정도의 확률(또는 신뢰 수준)입니다.
컨볼루션 신경망
모델은 단순히 숫자와 구조 사이의 숫자와 어떤 종류의 입력(더 많은 숫자)을 적용하는 숫자와 구조의 모음입니다. 이 경우 이미지 분류를 수행하는데 가장 널리 사용되는 모델인 컨볼루션 신경망을 사용합니다.
3Blue1Brown의 이 비디오는 신경망에 대한 훌륭한 소개입니다. 컨볼루션 신경망의 경우 이 기사를 확인하는 것이 좋습니다.
컨볼루션 신경망(CNN)은 컨볼루션 섹션과 분류 섹션의 두 부분으로 구성됩니다.
우리는 이 GeeksforGeeks 기사에 있는 컨볼루션 신경망으로 시작할 것 입니다. 매우 간단한 CNN이므로 쉽게 개념화할 수 있으며 너무 많은 계산이 필요하지 않습니다. 그러나 소리를 분류하는데 합리적으로 잘 작동하는 것 같습니다.
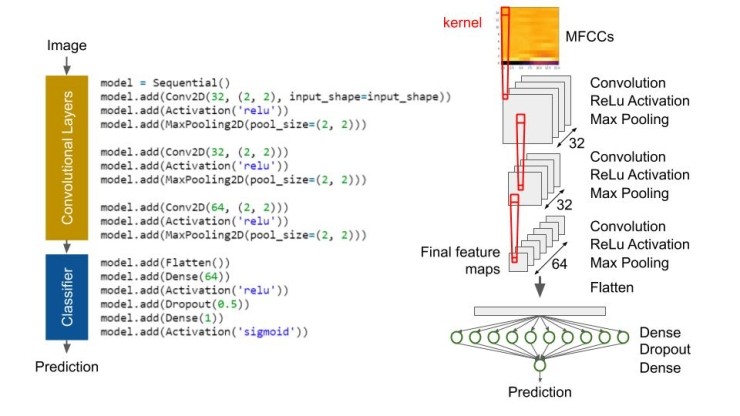
컨볼루션 섹션은 입력 이미지에서 "컨볼루션" 동작을 수행하는 하나 이상의 신경망 계층을 포함합니다. 우리의 목적 상, "컨볼루션(convolution)"은 이미지를 필터링하여 해당 이미지의 기능을 식별하는 것을 말합니다. 이미지 필터는 전체 이미지를 가로 질러 이동하는 창으로, 픽셀 샘플(첫 번째 레이어에서 2x2 픽셀)을 가져와 해당 픽셀에 가중치를 곱한 다음 합계를 사용하여 다음 이미지에 픽셀을 만듭니다. 이 창을 커널이라고 합니다.
첫 번째 컨볼루션 레이어에는 32 개의 노드가 있습니다. 즉, 첫 번째 계산 후 32 개의 작은 이미지로 끝납니다. 이 작은 이미지는 입력의 필터링된 출력이며 종종 원본 이미지의 가장자리 및 모서리와 같은 미세한 세부 사항을 강조 표시합니다.
컨볼루션 후에는 음수값을 0으로 변환하는 정류 선형 단위(ReLU) 활성화 기능을 수행합니다. 이는 신경망에 비선형성 수준을 추가하여 분류 및 기능 추출을 위해 이를 학습할 수 있게 합니다. ReLU 활성화에 대한 자세한 내용은 이 기사를 참조하십시오.
그런 다음 Max Pooling 작업을 수행합니다. 여기서 필터링된 각 이미지에서 다른 창이 미끄러져 해당 창에서 가장 높은 픽셀 값을 제외한 모든 값이 떨어집니다. 이를 통해 이미지의 정확한 위치가 아니라 대략적인 위치에 대한 가장 중요한 기능과 정보를 유지할 수 있습니다. 또한 다음 레이어의 계산 부하를 줄이는 데 도움이 됩니다. 이 기사에는 Max Pooling에 대한 훌륭한 정보가 있습니다.
이 Convolution-ReLU-Max 풀링 프로세스를 두 번 더 반복하여 최종 64 기능 맵 세트를 얻습니다. 각각의 연속적인 컨볼루션 레이어를 통해 더 복잡한 기능을 배우도록 네트워크를 훈련시킵니다. 예를 들어 첫 번째 레이어는 가장자리와 모서리일 수 있지만 마지막 레이어(개 유형을 식별하도록 훈련 된 네트워크와 같은 것)는 "플로피 귀"와 "뾰족한 귀"일 수 있습니다.
이 이미지 특징들은 분류를 위해 완전히 연결된 신경망에 공급되는 하나의 긴 벡터(2D 행렬의 집합이 아닌)로 편평화됩니다. 이 예에서 네트워크의 깊이는 2 계층입니다. ReLU 활성화와 다른 싱글 노드 레이어가 있는 64 개의 노드들 중 하나의 계층이 있습니다. 최종 노드에 시그모이드 활성화 기능을 제공했기 때문에 모델이 입력 이미지에 대해 단어 "stop"에 대한 MFCC라는 신뢰도에 해당하는 0과 1 사이의 숫자를 제공합니다.
0.5와 같은 임계값을 설정할 수 있으며 해당 임계값을 초과하는 출력은 입력 이미지가 대상 웨이크 워드에 속하는 것을 의미한다고 말할 수 있습니다.
모델의 두 최종 레이어 사이에 드롭아웃 레이어도 있음을 알 수 있습니다. 0.5 드롭아웃 레이어는 이전 레이어의 노드 출력 중 50 %가 다음 레이어로 넘어가는 것을 무시합니다. 이것은 네트워크에 노이즈와 같은 임의성을 추가하고 과적합에 도움을 줄 수 있습니다. 드롭아웃 레이어에 대한 자세한 내용은 이 기사를 참조하십시오.
이제 코드로 신경망을 구현할 준비가 되었습니다! CNN에 관한 모든 것을 완전히 파악하지 못해도 걱정하지 마십시오. 현재 이미지 분류에 인기가 있다는 것을 아는게 중요합니다. 사전 제작된 CNN을 사용하여 낱말로부터 MFCC 기능을 분류하는데 도움을 줍니다. 신경망에서 레이어/노드 추가 또는 제거와 같은 일부 변수를 사용하여 성능이 전혀 바뀌지 않는지 확인하는 것이 좋습니다.
Convolutional Neural Network를 훈련시키기 위해 Python Script 실행
https://github.com/ShawnHymel/tflite-speech-recognition으로 이동하여 Jupyter Notebook 및 Python 파일을 다운로드하십시오. 컴퓨터에서 Jupyter Notebook 세션을 시작하고 02-speech-commands-mfcc-classifier를 엽니다.


첫 번째 셀(또는 노트북 전체)에 나열된 패키지 중 하나가 없는 경우 자체 셀에서 다음을 실행하여 설치할 수 있습니다.
!pip install <name of package>
dataset_path 변수가 컴퓨터의 Google Speech Commands 데이터 세트 디렉토리를 가리키도록 변경하고 feature_sets_path 변수가 all_targets_mfcc_sets.npz 파일의 위치를 가리키도록 변경하십시오.
무슨 일이 일어나고 있는지 이해하려면 한 번에 한 셀씩 노트북을 실행하는 것이 좋습니다.
다음과 같은 Keras 코드를 사용하여 CNN을 구성합니다.
# Build model
# Based on: https://www.geeksforgeeks.org/python-image-classification-using-keras/
model = models.Sequential()
model.add(layers.Conv2D(32,
(2, 2),
activation='relu',
input_shape=sample_shape))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(32, (2, 2), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(64, (2, 2), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
# Classifier
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
그런 다음 신경망의 요약을 인쇄하여 각 레이어의 노드 수와 각 레이어의 동작을 기록하여 모양과 크기에 대한 아이디어를 얻을 수 있습니다.
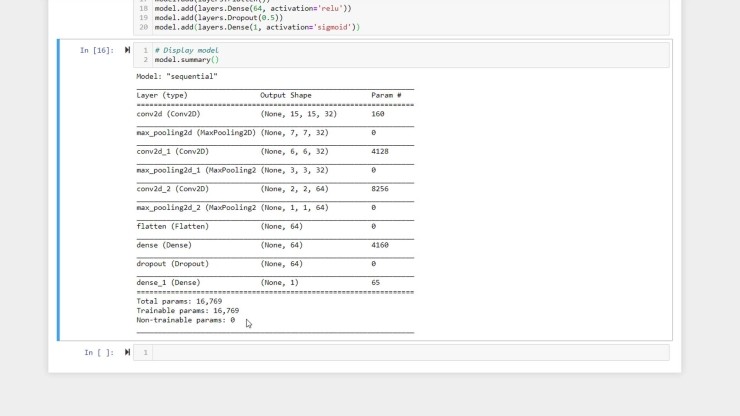
총 매개 변수 수를 살펴 보십시오. 이것은 수행해야 할 무게, 편향 및 작동의 수에 대한 통찰력을 제공하므로 모델의 크기에 대한 아이디어를 제공합니다. 이 숫자가 클수록 모델을 훈련시키고 예측하는데 더 많은 계산주기가 필요합니다. 이 모델을 Raspberry Pi와 같은 엣지 장치에 배포하기 위해 모델의 정확성을 유지하면서 이 숫자를 가능한 작게 만들어야 합니다.
# Train 셀에 도착하면 모델이 교육 프로세스를 시작할 준비가 됩니다.

이전 셀에서는 모델이 binary_crossentropy loss 함수로 모델을 구성했습니다. 이 함수는 모델이 각 샘플의 예측 결과와 실제 답변 간의 차이를 측정하는데 사용할 방정식입니다. 이것은 훈련에서 매우 중요합니다! binary_crossentropy loss 함수는 이진 분류를 위한 모델 학습을 돕기 위해 특별히 설계되었습니다.
또한 rmsprop 함수를 최적화 프로그램으로 추가합니다. 옵티마이저는 신경망에서 가중치 및 바이어스 항을 변경하여 다음 반복에 대한 답변을 보다 정확하게 예측하는 데 사용되는 알고리즘입니다. 널리 사용되는 최적화 프로그램에는 SGD(stochastic gradient descent), RMSProp 및 Adam이 있습니다. 이 기사는 이러한 옵티마이저에 대한 좋은 소개를 제공합니다.
마지막으로 훈련 과정에서 측정 항목 매개 변수에 정확도를 추가하여 정확도를 측정하려고 합니다. 모델의 출력을 Y 벡터의 알려진 양호한 값과 비교하여 모델이 얼마나 자주 답을 얻었는지에 대한 점수를 제공합니다.
# Train 셀을 실행할 때 이상적으로 손실 점수가 감소하고 정확도 점수가 각 에포크를 증가시켜 모델이 예측을 개선하는 데 도움이 됨을 알 수 있습니다.
훈련이 끝나면(내 경험에서 최대 1 시간이 걸릴 수 있음) 시간의 함수로 에포크 단위로 측정된 정확도 및 손실 값을 그래프로 나타낼 수 있습니다.
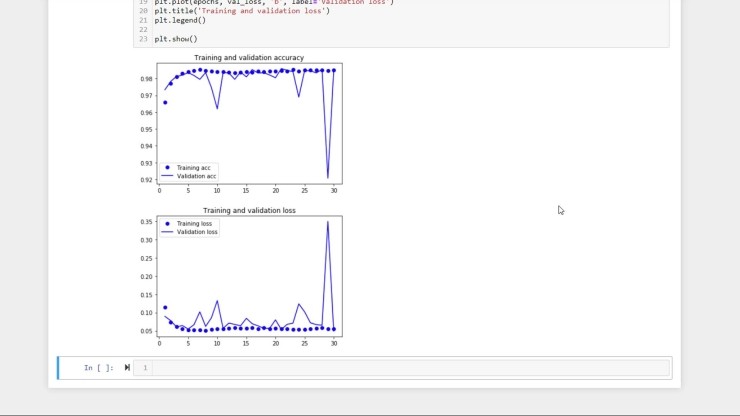
이상적으로는 시간이 지남에 따라 정확도가 증가하고 일부 값에 수렴하고 손실값이 시간에 따라 감소하고 일부 값에 수렴되는 것을 볼 수 있습니다.
기능 추출 중에 유효성 검사 세트를 따로 보관하는 방법을 기억하십니까? 각 시대가 지나면 유효성 검증 세트에서 모델의 성능을 평가하여 유효성 검증 손실 및 유효성 검증의 척도를 작성합니다.
정확도 및 손실값은 훈련 세트 데이터에서 결정됩니다. 이론적으로는 검증 및 교육 정확도/손실이 동일해야 합니다. 그러나 종종 검증 데이터보다 교육 데이터에서 모델의 성능이 더 우수하다는 것을 알게 될 것 입니다. 이 간격이 너무 넓으면 모델에 과적합이 발생한다고 합니다. 과적합은 모델이 학습 세트에 고유한 기능을 학습했으며 보이지 않는 데이터에서는 잘 수행되지 않음을 의미합니다. 과적합을 다루는 방법에는 여러 가지가 있지만 지금은 결과가 훈련 정확도와 검증 정확도 사이에 큰 차이가 있는지 확인해야 합니다.
약간 다른 결과를 얻기 위해 훈련 과정을 다시 실행할 수 있습니다. 네트워크의 초기 가중치와 바이어스는 임의로 선택되므로 모델이 완성되는 위치는 다소 임의적 일 수 있습니다.
결과에 만족하면 Keras의 save_model 명령을 사용하여 신경망을 .h5 파일로 저장합니다.
모델이 하나의 샘플을 예측하게 하려면 model.predict() 함수를 사용할 수 있습니다. 1 초짜리 오디오 클립에서 MFCC를 제공해야 합니다.
model.evaluate()를 사용하여 테스트 세트에서 모델을 평가할 수도 있습니다. 이 함수는 모델이 일련의 예측을 수행하고 출력을 y_test 벡터에 저장된 알려진 답변과 비교합니다.
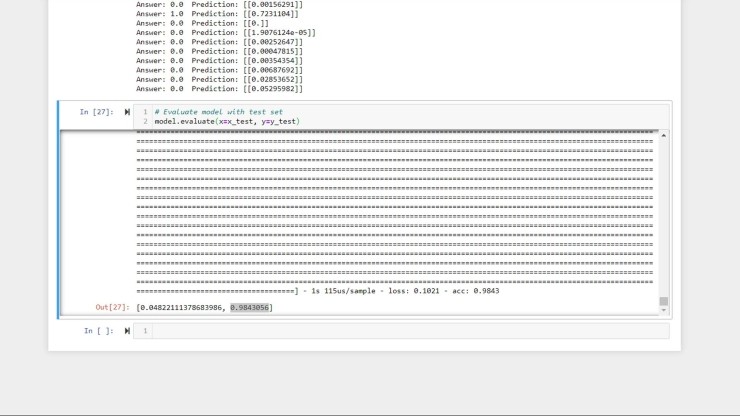
테스트 세트에서 98.4 %의 정확도로 모델이 수행된 것 같습니다!
그것이 높은 것처럼 보일지 모르지만, 우리가 훈련한 모든 단어 중 약 4%만이 “stop”였다는 것을 기억하십시오. 즉, 모델이 모든 오디오 클립에 대해 "not stop"으로 추측한 경우 시간의 96%에 해당합니다. 우리의 모델은 보이지 않는 데이터가 유용하기 위해서는 96% 이상 개선되어야 합니다.
MFCC 계산, 모델 모양 및 크기, 에포크 수 등은 하이퍼파라미터로 간주됩니다. 이 값은 교육 전에 설정되며 교육 중에 자동으로 업데이트되지 않습니다. 이 하이퍼파라미터를 가지고 놀아서 모델이 더 정확한지 확인하십시오!
더 나아가기
이제 완전히 훈련된 모델을 갖추었으므로 대상 장치에 모델을 배포할 준비가 되었습니다. 컨볼루션 신경망에 대해 더 깊이 파고 들고 싶다면 다음과 같은 리소스를 참조하십시오.
[출처] https://m.blog.naver.com/damtaja/221999528752
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.