
- 전체
- Sample DB
- database modeling
- [표준 SQL] Standard SQL
- G-SQL
- 10-Min
- ORACLE
- MS SQLserver
- MySQL
- SQLite
- postgreSQL
- 데이터아키텍처전문가 - 국가공인자격
- 데이터 분석 전문가 [ADP]
- [국가공인] SQL 개발자/전문가
- NoSQL
- hadoop
- hadoop eco system
- big data (빅데이터)
- stat(통계) R 언어
- XML DB & XQuery
- spark
- DataBase Tool
- 데이터분석 & 데이터사이언스
- Engineer Quality Management
- [기계학습] machine learning
- 데이터 수집 및 전처리
- 국가기술자격 빅데이터분석기사
- 암호화폐 (비트코인, cryptocurrency, bitcoin)
[기계학습] [번역] TensorFlow Lite 튜토리얼 3 부 : Raspberry Pi의 음성 인식

이전 자습서에서는 TensorFlow와 Keras를 사용하여 CNN (Convolutional Neural Network)을 훈련시켜 음성 단어 "stop"에 응답했습니다. 이 모델을 이 튜토리얼에서 읽고 TensorFlow Lite 모델 파일로 변환할 파일로 저장했습니다.
TensorFlow Lite 모델 파일은 가중치 및 조작이 TensorFlow Lite 파일에 FlatBuffer로 저장된다는 점에서 일반 TensorFlow 모델 파일과 다릅니다. FlatBuffer는 플래시 스토리지에서 대량의 데이터를 덩어리로 읽을 수 있는 특수한 유형의 스토리지 컨테이너입니다. 이를 통해 프로세서는 데이터를 모두 메모리에 먼저 로드하지 않고도 데이터를 스트리밍할 수 있습니다. 또한 TensorFlow Lite 모델 파일은 스토리지에 최적화되어 있어 단일 보드 컴퓨터 및 마이크로 컨트롤러와 같은 임베디드 시스템에서 사용하기에 적합합니다.
이 자습서의 나머지 부분에서는 TensorFlow Lite 모델 파일을 읽고 이를 사용하여 실시간 단어 인식을 수행하는 Raspberry Pi용 Python 프로그램을 개발합니다. Amazon Echo와 같은 자체 음성 어시스턴트 하드웨어를 개발하거나 새로운 유형의 하드웨어 인터페이스를 생성하기 위해 이 작업을 수행할 수 있습니다.
비디오를 선호하는 경우 이 자습서를 YouTube에서 볼 수 있습니다.

이 자습서 및 이 시리즈의 이전 자습서에 대한 모든 코드는 이 GitHub 리포지토리에서 찾을 수 있습니다.
TensorFlow Lite 모델 파일 작성
첫 번째 단계는 TensorFlow Lite 모델 파일을 작성하는 것 입니다. TensorFlow에는 내장된 명령이 있어 파이썬 내에서 호출하여 변환을 처리할 수 있습니다. 빠른 스크립트만 작성하면 됩니다.
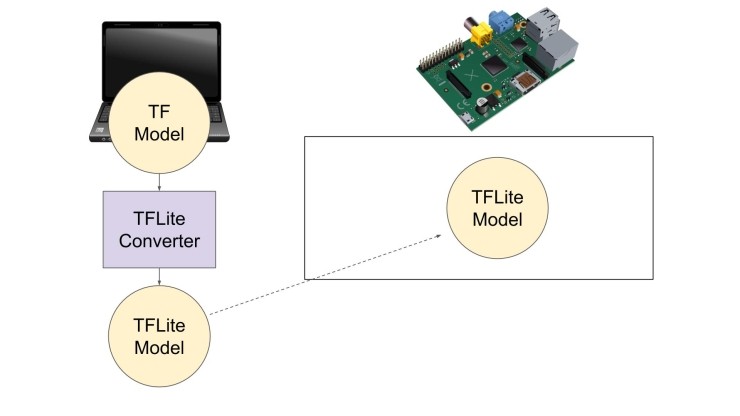
여기에서 TensorFlow Lite 모델 파일(.tflite)을 Raspberry Pi로 복사할 수 있습니다. 이를 통해 실시간 추론 프로그램에서 일반 파일로 읽을 수 있습니다.
새 Python 파일 또는 Jupyter Notebook에서 다음 코드를 입력하십시오. keras_model_filename이 이전 학습서에서 작성한 .h5 파일의 위치를 가리키는지 확인하십시오.
from tensorflow import lite
from tensorflow.keras import models
# Parameters
keras_model_filename = 'wake_word_stop_model.h5'
tflite_filename = 'wake_word_stop_lite.tflite'
# Convert model to TF Lite model
model = models.load_model(keras_model_filename)
converter = lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
open(tflite_filename, 'wb').write(tflite_model)
이 코드를 실행할 때 Keras 모델을 TensorFlow Lite 모델 파일로 변환해야 합니다.
실시간 추론 개요
"추론"(기계 학습 어휘에서)은 보이지 않는 새로운 데이터 세트에서 의미를 유추하는 프로세스입니다. 우리는 Raspberry Pi에 대해 실시간 추론을 수행하여 음성 단어가 발생할 때 응답하도록 합니다. 이를 위해서는 tflite 모델 파일을 Raspberry Pi에 복사해야 합니다. 그런 다음, 항상 청취하는 마이크를 사용하여 1 초마다 오디오를 멜 주파수 cepstral 계수(MFCC)로 변환합니다. 이 MFCC는 tflite 모델 파일을 실행하는 추론 엔진으로 전송되는 기능입니다.
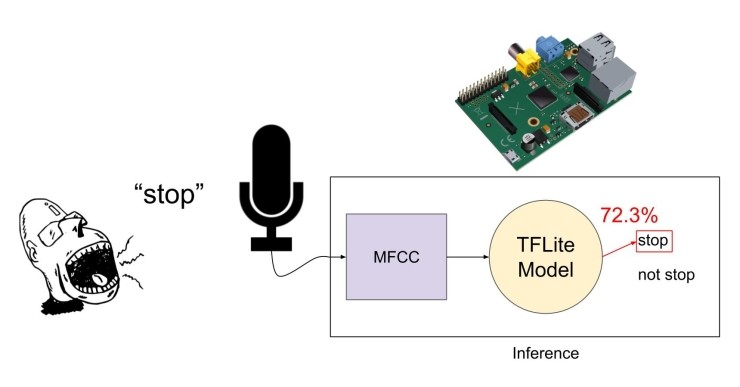
모델의 출력은 모델이 피쳐가 웨이크 단어 "stop"와 얼마나 근접한 것으로 생각하는지에 대한 점수(실제로 확률)를 제공합니다. 해당 점수가 임계값을 초과하면(50%로 설정), Raspberry Pi가 조치를 수행하도록 할 수 있습니다. 이 경우에는 LED만 깜박입니다.
한 가지 우려되는 것은 웨이크 단어가 2 개의 개별 1 초 창으로 분할될 수 있다는 것 입니다. 이를 방지하기 위해 코드에서 "슬라이딩 창"을 수행할 수 있습니다. 추론 엔진의 원시 데이터로 사용하기 위해 1 초 슬라이스를 사용하고 창을 0.5 초 위로 이동한 후 추론을 다시 수행합니다. 즉, 데이터가 약간 겹치면서 두 배의 계산을 수행해야 하지만 창간에 단어가 손실되는 것을 방지하는데 도움이 됩니다.
예를 들어, 이 클립의 첫 1 초를 가져 와서 MFCC를 계산하고 tflite 모델을 통해 실행할 수 있습니다. 그것은 말이 존재하지 않기 때문에 우리에게 약간의 출력 점수를 줄 것입니다.
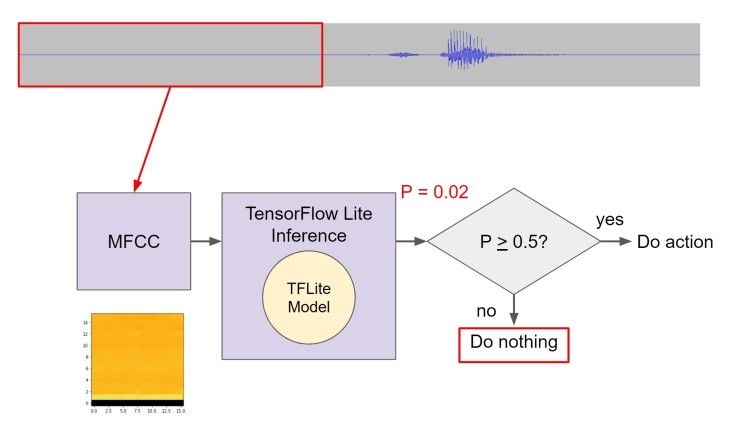


그런 다음 창을 0.5 초 이상 이동하고 프로세스를 반복합니다. 이 단어는 여전히 존재하지 않으므로 낮은 점수를 얻게 됩니다. "stop"는 창의 마지막 부분이지만 전체 단어는 아닙니다.
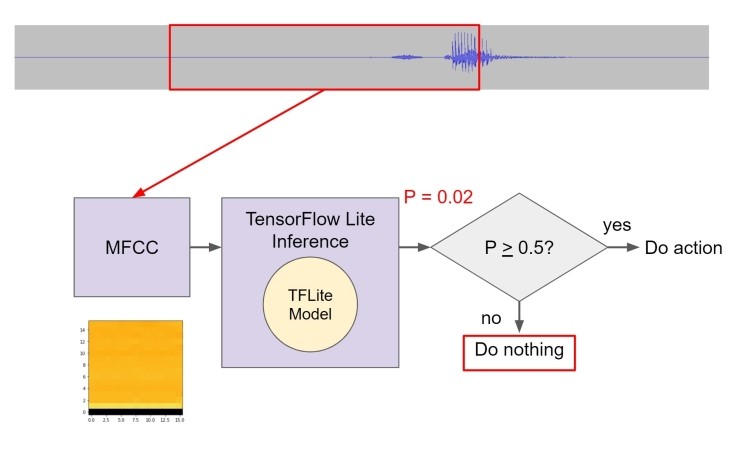
우리는 창을 다시 0.5 초 이상 움직인 후 반복합니다. 이번에는 웨이크 단어가 오디오에 있으므로 추론 섹션에서 훨씬 높은 점수를 얻습니다. 이 시점에서 LED(또는 원하는 다른 것)가 깜박이는 동작을 시작합니다.
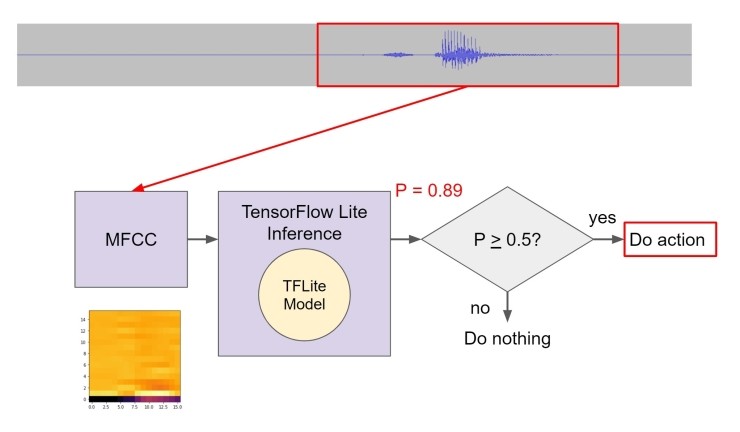
실행 추론
먼저 .tflite 파일을 Raspberry Pi에 복사하십시오. 파일이 코드와 동일한 디렉토리에 있거나 파일을 가리키도록 코드의 경로를 업데이트하고 싶을 것 입니다.
USB 마이크를 Raspberry Pi에 연결하고 필요한 드라이버를 설치하려고 합니다. 이 USB 마이크를 권장하고 Adafruit의 지침을 따르십시오.
Raspberry Pi에서 Python 3 및 Pip 3을 실행 중인지 확인하십시오. python 또는 pip로 표시되는 모든 코드는 버전 3이라고 가정합니다. 다음 패키지를 설치하십시오.
Python -m pip install sounddevice numpy scipy timeit python_speech_features
TensorFlow Lite 인터프리터를 설치하려면 pip가 해당 휠 파일을 가리켜야 합니다. TensorFlow Lite 빠른 시작 안내서로 이동하여 사용 가능한 휠 파일을 보여주는 표를 찾으십시오. 프로세서용 TensorFlow Lite 패키지의 URL을 복사하십시오. Raspbian Buster를 실행하는 Raspberry Pi의 경우 Python 3.7 용 ARM 32 패키지일 수 있습니다. 다음과 같이 TensorFlow Lite를 설치하십시오.
Python -m pip install <URL to TensorFlow Lite 패키지>
보드 핀 8(GPIO14)과 접지 핀 사이에 LED와 제한 저항(100-1k Ω)을 연결하려고 합니다. Raspberry Pi 핀아웃 가이드를 참조하십시오.
.tflite 파일과 동일한 디렉토리에 있는 새 Python 파일에 다음 코드를 추가하십시오.
"""
Connect a resistor and LED to board pin 8 and run this script.
Whenever you say "stop", the LED should flash briefly
"""
import sounddevice as sd
import numpy as np
import scipy.signal
import timeit
import python_speech_features
import RPi.GPIO as GPIO
from tflite_runtime.interpreter import Interpreter
# Parameters
debug_time = 1
debug_acc = 0
led_pin = 8
word_threshold = 0.5
rec_duration = 0.5
window_stride = 0.5
sample_rate = 48000
resample_rate = 8000
num_channels = 1
num_mfcc = 16
model_path = 'wake_word_stop_lite.tflite'
# Sliding window
window = np.zeros(int(rec_duration * resample_rate) * 2)
# GPIO
GPIO.setwarnings(False)
GPIO.setmode(GPIO.BOARD)
GPIO.setup(8, GPIO.OUT, initial=GPIO.LOW)
# Load model (interpreter)
interpreter = Interpreter(model_path)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
print(input_details)
# Decimate (filter and downsample)
def decimate(signal, old_fs, new_fs):
# Check to make sure we're downsampling
if new_fs > old_fs:
print("Error: target sample rate higher than original")
return signal, old_fs
# We can only downsample by an integer factor
dec_factor = old_fs / new_fs
if not dec_factor.is_integer():
print("Error: can only decimate by integer factor")
return signal, old_fs
# Do decimation
resampled_signal = scipy.signal.decimate(signal, int(dec_factor))
return resampled_signal, new_fs
# This gets called every 0.5 seconds
def sd_callback(rec, frames, time, status):
GPIO.output(led_pin, GPIO.LOW)
# Start timing for testing
start = timeit.default_timer()
# Notify if errors
if status:
print('Error:', status)
# Remove 2nd dimension from recording sample
rec = np.squeeze(rec)
# Resample
rec, new_fs = decimate(rec, sample_rate, resample_rate)
# Save recording onto sliding window
window[:len(window)//2] = window[len(window)//2:]
window[len(window)//2:] = rec
# Compute features
mfccs = python_speech_features.base.mfcc(window,
samplerate=new_fs,
winlen=0.256,
winstep=0.050,
numcep=num_mfcc,
nfilt=26,
nfft=2048,
preemph=0.0,
ceplifter=0,
appendEnergy=False,
winfunc=np.hanning)
mfccs = mfccs.transpose()
# Make prediction from model
in_tensor = np.float32(mfccs.reshape(1, mfccs.shape[0], mfccs.shape[1], 1))
interpreter.set_tensor(input_details[0]['index'], in_tensor)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
val = output_data[0][0]
if val > word_threshold:
print('stop')
GPIO.output(led_pin, GPIO.HIGH)
if debug_acc:
print(val)
if debug_time:
print(timeit.default_timer() - start)
# Start streaming from microphone
with sd.InputStream(channels=num_channels,
samplerate=sample_rate,
blocksize=int(sample_rate * rec_duration),
callback=sd_callback):
while True:
pass
코드를 실행하면 추론 엔진의 출력이 표시됩니다. 침묵하는 시간과 “stop” 이외의 단어를 말할 때는 0.5 미만이어야 합니다. "stop"라고 말하면 0.5 점 이상의 점수를 표시하고 "stop"라고 들려야 합니다. LED도 깜박입니다.
이것은 완벽한 모델과는 거리가 멀다는 점에 유의하십시오. "stuff"과 같이 "stop"에 가까운 단어는 웨이크 단어 동작을 트리거할 수 있습니다. 또한 모델이 무음 또는 주변 소음에 대해 훈련되지 않았기 때문에 구어체가 없으면 출력 확률이 필요 이상으로 높아질 수 있습니다. 마지막으로 슬라이딩 윈도우 시스템은 매우 조잡합니다. 동일한 0.5 초 오디오 청크에서 MFCC를 다시 계산해야 하며 "stopped"또는 "stopping"과 같은 웨이크 단어의 변형을 트리거할 수 있습니다.
그러나 이것은 임베디드 리눅스에서 실행되는 Edge AI 시스템을 실험하기에 좋은 출발점이 될 것 입니다! 위의 문제 중 일부를 고치거나 자신만의 웨이크 단어를 훈련시키거나 다른 기능으로 훈련해 보십시오.
더 나아가기
이 튜토리얼이 Edge AI 프로젝트의 출발점으로 작용하기를 바랍니다. 예를 들어, "stop!"이라고 외치는 사람에게 응답하여 기계를 끄는 밀링 머신용 보조 비상 정지 회로를 만들 수 있습니다.

이제 처음부터 작성한 완전한 기능의 Edge AI 장치가 있습니다. 프로젝트를 더 진행하고 싶은 경우 다음 자료를 참조하십시오.
- 이 프로젝트의 코드를 위한 GitHub 리포지토리
- TensorFlow GitHub 리포지토리
- TensorFlow Lite 메인 페이지
- 오디오 처리를 위한 스펙트로그램 및 CNN의 문제점
- TensorFlow 음성 인식 : 두 가지 빠른 자습서
[출처] https://m.blog.naver.com/damtaja/221999558070
광고 클릭에서 발생하는 수익금은 모두 웹사이트 서버의 유지 및 관리, 그리고 기술 콘텐츠 향상을 위해 쓰여집니다.